Why Showing Sources Is Not Enough
Citations add authority without adding verification, and weak retrieval lets a system cite a real document for a false claim.

A design review I sat in went like this. The team had a RAG-powered answer feature, and someone asked the obvious question: how do we stop it from being confidently wrong. The lead designer had a ready answer. "We show sources. Every answer links to the document it came from. The user can always check." The room relaxed. The problem felt solved. It was not solved. It was relabeled. Showing sources had converted a verification problem into a verification theater, and almost everyone in the room believed the theater was the real thing.
This chapter is about why citations, the most popular fix for confident wrongness, mostly do not fix it, and what would.
Three separate failures hide behind "we show sources"
When a team says "we show sources," they are usually claiming three things at once, and all three can fail independently.
The first claim is that the cited source actually supports the answer. It often does not. Retrieval can return a document that is topically relevant but does not contain the claim, and the model can then generate a fluent answer that cites that document anyway. This is the attribution failure, and it is well documented.
The second claim is that the source itself is correct and current. A citation to a real document says nothing about whether that document is right, authoritative, or up to date. The procurement disaster that opened this book cited a real contract template. The template was superseded. The citation was honest and the answer was wrong.
The third claim is that the user will actually check the source. They mostly will not. And here is the cruel twist: the presence of a citation makes them less likely to check, not more, because the citation signals rigor and rigor signals "you don't need to verify this." Showing sources can reduce verification while increasing trust, which is the precise opposite of what you wanted.
Let me take these in turn, because each has a different fix.
Attribution failure: the model cites a source that does not support the claim
In retrieval-augmented generation, the model is given retrieved passages and asked to answer using them. The intuition is that grounding the answer in retrieved text makes it faithful to that text. The research says this intuition is too optimistic.
Work on attribution and faithfulness in language models, such as the Attributed Question Answering line of research from Bohnet and colleagues, frames the problem precisely: a system can produce an answer along with a citation, and the citation may or may not actually entail the answer. They build evaluation specifically to measure whether the cited source supports the generated claim, because the two come apart routinely. A model can retrieve a real, relevant document and then generate a claim that the document does not actually make, while still attaching the citation. The citation is real. The support is not.
This matters enormously for the confident-wrongness problem, because the citation is itself an authority signal. An answer with a citation looks more verified than an answer without one. So an unsupported citation is worse than no citation: it adds authority while subtracting nothing from the error. You have made a wrong answer look more trustworthy.
The fix here is not "show sources." It is verify entailment. Before you display a citation, check, ideally with a separate verification step, that the cited passage actually supports the specific claim. If it does not, you do not get to show the citation, and the answer's confidence should drop accordingly. This is the "Use evidence" step of the DOUBT pattern doing real work: evidence is not a link you attach, it is a check you pass.
Source-quality failure: the cited document is real but wrong, stale, or non-authoritative
Even when the source genuinely supports the claim, the source may not deserve to be trusted. Three failure modes recur.
Staleness. The document was correct when written and is wrong now. Policies change, prices change, contract templates get superseded. A freshness signal, when was this source last updated and is that recent enough for this question, is a first-class confidence input, not metadata.
Authority. Not all sources are equal. An answer grounded in an official, current policy document deserves more confidence than one grounded in a community forum post, an old internal wiki page, or a draft. If your retrieval treats all indexed documents as equally authoritative, your answers inherit the authority of your worst document.
Internal contradiction. Real corpora contradict themselves. Two documents say different things, retrieval returns one of them, and the answer confidently reflects whichever happened to rank higher. The contradiction is invisible to the user, who sees one confident answer, not the disagreement underneath it.
The fix is a source-quality rubric applied at index time and surfaced at answer time. Here is a workable rubric you can adapt.
| Dimension | 3 (high) | 2 (medium) | 1 (low) |
|---|---|---|---|
| Authority | Official, owned, current policy/spec | Internal wiki, approved docs | Forum, comment, draft, unowned |
| Freshness | Updated within policy window | Aging but plausibly valid | Past freshness threshold or unknown |
| Specificity | Directly addresses the question | Adjacent, requires inference | Tangential |
| Corroboration | Agrees with other high sources | Single source | Contradicted by another source |
A source's score on this rubric should feed directly into the answer's internal confidence, and therefore into its expressed confidence. An answer grounded in a 3/3/3/3 source can be stated plainly. An answer grounded in a low-authority, stale, contradicted source should be hedged or abstained from, even if the model is internally fluent about it. The rubric turns "we have sources" into "we have sources of known quality, and the answer's confidence reflects that quality."
The verification failure: users do not click, and citations make it worse
Now the most uncomfortable failure, because it is about humans and you cannot patch it in the model.
The premise of "show sources" is that the user can always check. The premise of safety is that they will. The research on how people use warnings, disclosures, and verification affordances is not kind to that hope. People satisfice. Under time pressure, with a fluent answer in front of them that looks complete, the citation functions as a trust badge, not a verification invitation. Its presence reassures; it does not prompt action.
This connects directly to the automation-bias literature. When a system provides an answer plus a supporting cue, operators tend to accept the answer and treat the cue as confirmation rather than as something to independently check. Parasuraman and Riley's framework of automation misuse, the overreliance that produces monitoring failures, predicts exactly this: the citation becomes part of the automation's authority, absorbed into the reason to trust rather than serving as a reason to verify. The disclosure that was supposed to enable scrutiny becomes another input to complacency.
So a citation that is never clicked has, in practice, only one effect: it raises authority. It does not raise verification. On the Confidence-Cost Matrix from the previous chapter, an unclicked citation moves a feature up and to the right, more apparent confidence, same actual reliability, which is precisely the direction you do not want to move a high-stakes feature.
What actually works: make evidence do work the user does not have to
If showing a link does not produce verification, the design move is to do the verification work inside the product and surface its result, rather than outsourcing it to a user who will not perform it.
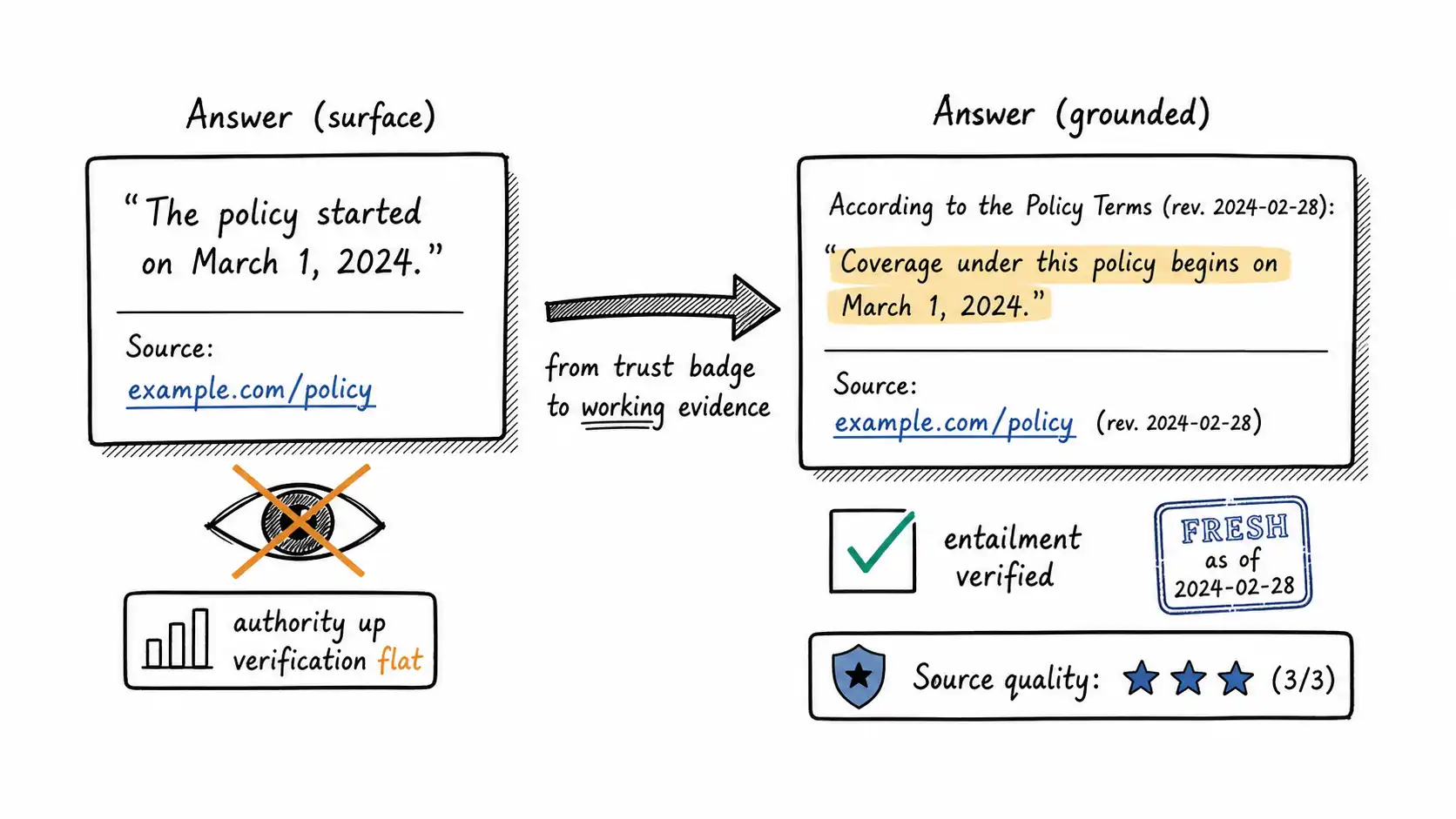
Surface the supporting passage, not just the link. Instead of "[source]", show the exact sentence from the source that supports the claim, inline, with the claim. This collapses the verification step into reading the answer. The user does not have to click and hunt; the evidence is the answer. And critically, if your system cannot find a supporting sentence to surface, that absence is a signal: you are about to make an unsupported claim, and the answer's confidence should drop.
Verify entailment before display. As above, run a check that the cited passage entails the claim. Display the citation only when it passes. When it fails, either abstain or visibly mark the claim as unverified. The user never sees a citation that does not actually support the answer.
Show freshness and authority inline. A small, legible freshness stamp ("from a policy page updated 14 months ago") and a source-authority indicator do more than a bare link, because they communicate the quality dimensions the user would never reconstruct by clicking. They let the user calibrate without verifying.
Reserve high-authority presentation for high-quality evidence. Tie the source-quality rubric score to the presentation. A 3/3/3/3 source earns a clean, confident card. A low-quality source earns a hedged, visibly caveated answer or an abstention. The interface's authority becomes a function of the evidence's quality, which is the whole point.
Notice that none of these is "show sources." They are make evidence verified, visible, and load-bearing. The difference between citation-as-trust-badge and citation-as-working-evidence is the difference between theater and the real thing.
A short note on the legal stakes of unverified citation
If you need a reason to take entailment verification seriously beyond product quality, consider what happens when humans rely on AI citations downstream. In the Mata v. Avianca matter, lawyers submitted a brief citing cases that did not exist, generated by a language model that produced fluent, confident, fully-formatted citations. As reported in the court's sanctions opinion and widely covered, the cited cases were fabrications, complete with fake quotations and internal citations. The model produced the authority signal, real-looking citations, without the underlying support, real cases. The humans, reading the authority signal, did not verify. The sanctions followed.
That is the attribution failure at maximum stakes. The citations were the most authoritative-looking part of the document and the most fictional. A system that surfaced the actual supporting text, or that verified entailment before display, would have made the fabrication visible immediately, because there would have been no real passage to surface. "Show sources" would not have helped, because the sources looked perfect. Verifying that the sources existed and said what was claimed would have.
Practical exercise: audit your citations for the three failures
Pull fifty real answers from a RAG feature that shows sources.
For attribution, manually check whether the cited passage actually supports the specific claim. Record the failure rate. Most teams who run this are unpleasantly surprised.
For source quality, score the cited sources on the rubric above. Note how many high-stakes answers rest on low-authority or stale sources.
For verification behavior, instrument click-through on citations in production. If high-stakes answers have low citation click rates, your citations are functioning as trust badges, not verification, and you should move to surfacing supporting passages inline and verifying entailment before display.
Three numbers come out of this: attribution failure rate, source-quality distribution, and citation click rate. Together they tell you whether "we show sources" is verification or theater. In my experience it is mostly theater, and the fix is to make the evidence do the work the user will not.
Summary
"We show sources" hides three independent failures. Attribution failure: the cited source may not actually support the claim, a documented problem in RAG and attribution research, and an unsupported citation is worse than none because it adds authority without support. Source-quality failure: a real source can be stale, non-authoritative, or contradicted, so source quality must be scored and fed into confidence. Verification failure: users mostly do not click citations, and the citation's presence reduces verification by signaling rigor, consistent with automation-bias research. The fix is not showing links but making evidence verified, visible, and load-bearing: surface the supporting passage inline, verify entailment before display, show freshness and authority, and reserve confident presentation for high-quality evidence. The Mata v. Avianca fabricated citations show the attribution failure at maximum stakes. Designing the Calibrated Answer builds the full specification that enforces these requirements as a gate between generation and display.
Key Takeaways
- "We show sources" conflates three failures: the source may not support the claim, the source may be wrong or stale, and the user will not check.
- Attribution research shows citations and the claims they accompany routinely come apart; an unsupported citation adds authority without support and is worse than none.
- Score sources with a quality rubric (authority, freshness, specificity, corroboration) and feed that score into the answer's confidence and presentation.
- Citations function as trust badges; their presence reduces verification by signaling rigor, consistent with automation-bias findings.
- Replace "show a link" with verified, inline, load-bearing evidence: surface the supporting sentence, verify entailment before display, show freshness and authority.
- Mata v. Avianca shows the attribution failure at its worst: perfect-looking citations to cases that did not exist, which only entailment verification, not "showing sources," would have caught.