Accuracy, Confidence, Calibration, and Authority
Four properties get collapsed into one in casual conversation, and the collapse is where AI products fail.

I once watched a vendor demo where the founder kept saying "our model is 94 percent accurate" as though that single number settled every question in the room. A risk officer across the table asked a sharper question than the founder expected: "When it's wrong, does it know it's wrong?" The founder did not have an answer, because the demo had never measured that. The 94 percent was an accuracy number. The risk officer was asking about calibration. They were talking about two completely different properties, and the confusion between them is the most expensive confusion in this entire field.
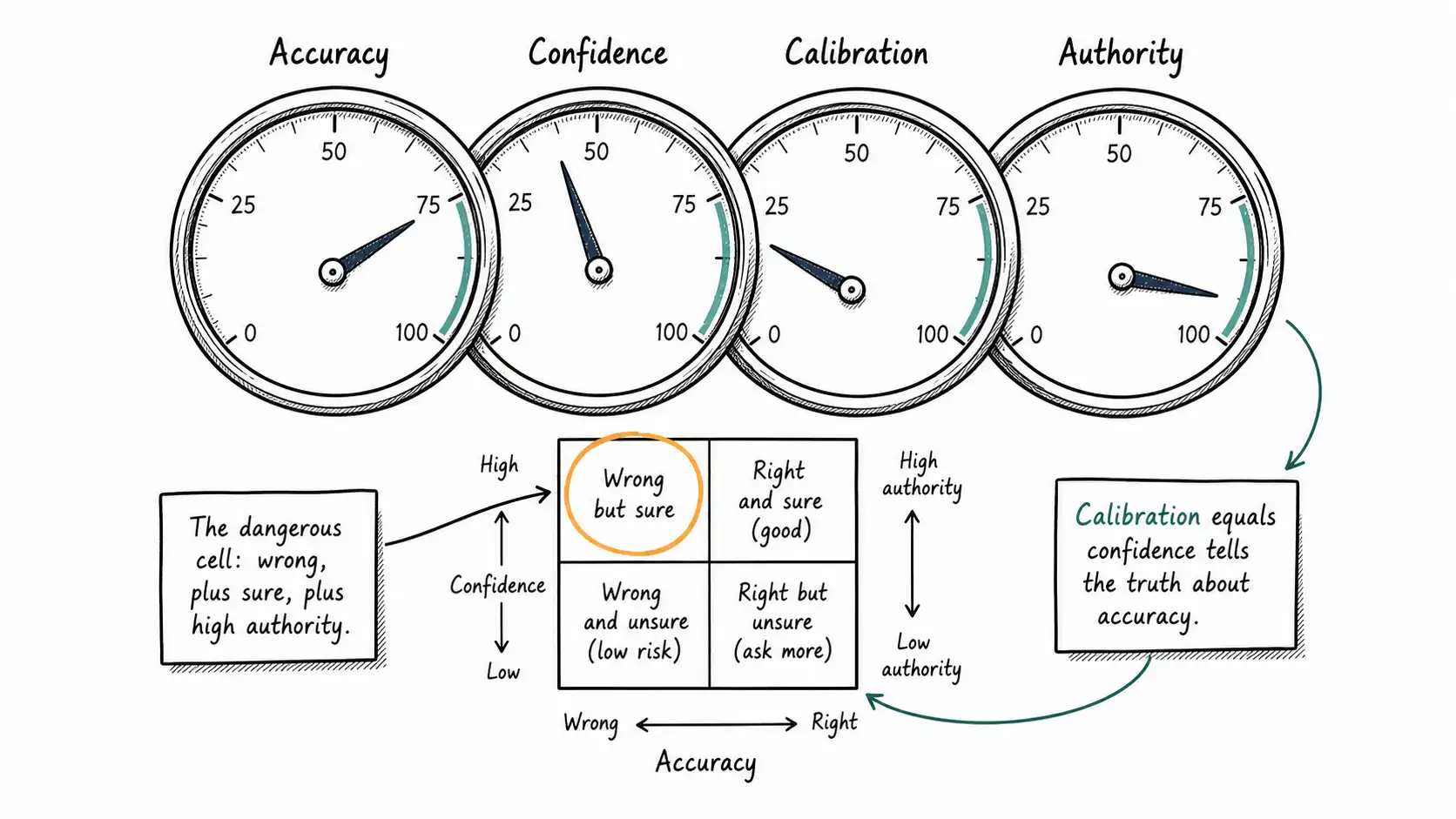
This chapter pulls apart four properties that everyday language smashes together: accuracy, confidence, calibration, and authority. They are independent. A system can have any combination. And almost every confidently-wrong disaster I have seen traces back to a team that optimized one of these while assuming they had gotten all four.
The four properties, defined precisely
Accuracy is how often the system is right. It is a property of outcomes, measured over many cases. "94 percent accurate" means that across some evaluation set, 94 percent of answers matched the truth. Accuracy says nothing about any individual answer and nothing about whether the system knows which 6 percent are wrong.
Confidence is how sure the system appears or reports itself to be, on a given answer. This splits into two kinds that teams constantly conflate. There is internal confidence, a number the system computes, such as a token probability, a softmax score, or a verifier's agreement signal. And there is expressed confidence, how sure the answer sounds to the human, which is a property of the presentation layer. The previous chapter was largely about the gap between these two. A model can have low internal confidence and high expressed confidence, which is the recipe for confident wrongness.
Calibration is the relationship between confidence and accuracy. A system is well calibrated if, among all the answers where it claims 80 percent confidence, it is actually right about 80 percent of the time. Calibration is not about being confident or being accurate. It is about confidence telling the truth about accuracy. This is the property the risk officer was asking for, and it is the property almost nobody measures.
Authority is something else entirely, and it lives almost entirely in the interface and the context. Authority is how much the answer's framing, branding, formatting, and placement signal that it should be trusted, independent of the content. The answer that appears inside your company's official tool, in clean typography, with a confident tone, carries authority that the identical text pasted into a chat window does not. Authority is borrowed trust. It is the interface lending the answer credibility that the evidence may not support.
These four are independent. Let me prove it with the cases that matter.
The combinations, and why most of them are traps
| Low authority | High authority | |
|---|---|---|
| Accurate, calibrated | Honest and trusted appropriately, but underused | The goal: right, knows when it isn't, trusted to the right degree |
| Accurate, miscalibrated | Right but sounds either too unsure (ignored) or falsely sure (overtrusted) | Right today, but uniform confidence is building overtrust for tomorrow's rare error |
| Inaccurate, calibrated | Wrong but flags its own uncertainty; least dangerous failure | Wrong but says so; authority is at least honest |
| Inaccurate, miscalibrated | Wrong and sounds sure, but low authority limits the damage | The catastrophe: wrong, sounds sure, wrapped in institutional trust |
The bottom-right cell is where the airline chatbot lived. The bottom-left cell is annoying but rarely catastrophic. The single most important move a product team can make is to get out of the bottom-right cell, and you cannot do it by improving accuracy alone, because the bottom-right cell is defined by miscalibration and authority, not by accuracy.
Modern neural networks are miscalibrated by default, and we have known since 2017
Here is a fact that should be load-bearing in every AI product strategy and almost never is. Modern neural networks are systematically overconfident, and this was documented carefully nearly a decade ago.
In On Calibration of Modern Neural Networks, Guo, Pleiss, Sun, and Weinberger showed that the deep networks that became standard around 2016 are far more poorly calibrated than the smaller networks that preceded them, and specifically that they are overconfident: their reported probabilities are systematically higher than their actual accuracy. The same architectural choices that improved accuracy, more depth, more width, batch normalization, less weight decay, made calibration worse. Accuracy and calibration moved in opposite directions.
Read that again, because it inverts the intuition most teams operate on. The improvements that made models more accurate made them more overconfident. So the natural product trajectory, ship a model, improve accuracy each quarter, is also, by default, a trajectory of increasing overconfidence unless you actively measure and correct calibration. You are not just failing to fix the confidence problem as you improve accuracy. You may be making it worse.
Guo and colleagues also offered a practical remedy worth knowing: temperature scaling, a single-parameter post-hoc adjustment that softens the model's probabilities to better match observed accuracy. It is cheap, it does not change the model's predictions, only its confidence numbers, and it works surprisingly well for classifiers. It will not save a generative system on its own, but it is the canonical example of treating calibration as a separate, tunable property rather than a free byproduct of accuracy. Later work, including Revisiting the Calibration of Modern Neural Networks by Minderer and colleagues, found that some newer architectures calibrate better out of the box, which is encouraging but does not change the operating rule: you must measure calibration on your own task, because it does not come for free and it does not transfer.
Why expressed confidence and internal confidence must be designed separately
Once you accept that internal confidence (a number the system computes) and expressed confidence (how sure the answer sounds) are different things, a design principle follows immediately. You must connect them deliberately, because by default they are disconnected.
The default generative system computes some internal signal, then ignores it when generating prose, and emits uniform expressed confidence. To fix this, you need an explicit mapping: a policy that takes the internal confidence signal and decides how the answer should sound and behave. That mapping is a product decision, not a model decision. It belongs to you.
Consider a simple, real version of such a mapping for a retrieval-backed support assistant.
internal_confidence = f(retrieval_score, source_freshness, verifier_agreement)
if internal_confidence >= HIGH:
express: direct answer, normal tone
elif internal_confidence >= MEDIUM:
express: answer + explicit caveat + source link + freshness
elif internal_confidence >= LOW:
express: tentative answer + "I could not verify this" + offer escalation
else:
abstain: do not answer; route to humanThe thresholds are yours to tune, and tuning them is exactly the calibration work. The point is that expressed confidence is now a function of internal confidence, instead of being a constant. That single architectural decision, making expressed confidence a function rather than a default, is most of what separates a calibrated product from a confidently-wrong one.
Authority is the multiplier, and you control more of it than you think
Authority deserves its own treatment because teams routinely add authority without realizing it, and authority multiplies the cost of every miscalibration.
Authority comes from placement (an answer inside the official enterprise tool versus a public chatbot), from branding (the company logo next to the answer), from formatting (bold text, numbered steps, a clean card), from tone (declarative versus tentative phrasing), and from absence of friction (an instant answer with no "verify this" prompt). Every one of these is a dial you control, and every one of them lends the answer trust independent of its evidence.
This is why "showing sources" so often fails to help, a point we will dismantle fully in a later chapter. A source citation adds authority. It looks rigorous. But if nobody clicks it, and the research says they usually do not, then the citation has increased authority without increasing verification. You have made the answer more trusted without making it more checkable in practice. Authority went up; calibration did not. That is exactly the wrong direction.
The discipline is to match authority to earned reliability. High-authority presentation should be reserved for high-confidence, well-evidenced answers. Low-confidence answers should be presented with deliberately reduced authority: softer tone, visible caveats, no false formatting of finality, an explicit path to a human. You are using the interface to tell the truth about how much the answer should be trusted.
A diagnostic you can run on any AI claim
When someone tells you a system is good, ask the four questions, in order, and refuse to be satisfied by an answer to one standing in for the others.
How accurate is it, on what evaluation set, and how representative is that set of production traffic? This is the question most teams can answer.
When it is wrong, does its confidence drop? In other words, is it calibrated, and how was that measured? This is the risk officer's question, and most teams cannot answer it.
How sure does it sound to the user, and is that expressed confidence a function of internal confidence or a constant? This is the interface question, and most teams have never separated the two.
How much authority does the interface lend the answer, and is that authority matched to the answer's earned reliability? This is the design question, and it usually surfaces dials nobody knew they were turning.
A system that scores well on accuracy but cannot answer the other three is precisely the kind of system that produces an expensive, confident, authoritative wrong answer on the day it finally errs. The 94-percent demo was a system like that. The risk officer was right to be unimpressed. Where Wrong Answers Get Expensive maps those four properties onto a decision tool for allocating calibrated doubt to every answer type in your product.
Practical exercise
Build a one-page scorecard for your highest-stakes AI feature with four rows: accuracy, calibration, expressed-confidence policy, and authority audit.
For accuracy, write the number and the evaluation set, honestly noting how well that set matches production.
For calibration, if you have never measured it, write "unmeasured" in red. That is the finding. The next chapter and the measurement chapter will give you the tools to fill it in.
For expressed-confidence policy, write down whether expressed confidence is currently a function of any internal signal or a constant. If it is a constant, you have located a high-use fix.
For authority, list every dial that lends the answer trust: placement, branding, formatting, tone, friction. Mark which ones are currently applied uniformly regardless of confidence. Each uniformly-applied authority dial is risk you are adding to your worst cases.
Bring that scorecard to your next product review. It reframes the conversation from "how accurate is our AI" to "does our AI tell the truth about how much to trust it," which is the conversation that actually prevents the expensive failure.
Summary
Accuracy, confidence, calibration, and authority are four independent properties that casual conversation collapses into one. Accuracy is how often the system is right; confidence splits into internal (computed) and expressed (how sure it sounds); calibration is whether confidence tracks accuracy; authority is borrowed trust from the interface. The catastrophic cell is inaccurate, miscalibrated, and high-authority. Guo and colleagues showed in 2017 that modern networks are systematically overconfident and that the changes which improve accuracy worsen calibration, so improving accuracy alone can make the confident-wrongness problem worse. The fix is to make expressed confidence an explicit function of internal confidence, and to match authority to earned reliability rather than applying it uniformly.
Key Takeaways
- Accuracy, confidence, calibration, and authority are independent; optimizing one while assuming the others is the core product mistake.
- Calibration is the relationship between confidence and accuracy: among answers claiming 80 percent confidence, the system should be right 80 percent of the time.
- Guo et al. (2017) showed modern networks are systematically overconfident, and the choices that raise accuracy lower calibration; accuracy and calibration can move in opposite directions.
- Internal confidence (computed) and expressed confidence (how it sounds) are different; default systems disconnect them, and you must map one to the other deliberately.
- Authority is borrowed trust from placement, branding, formatting, tone, and friction; match it to earned reliability instead of applying it uniformly.
- Ask four questions of any AI claim: how accurate, is it calibrated, is expressed confidence a function of internal confidence, and is authority matched to reliability.