Conclusion: Doubt Is an Interface for Truth
A confident answer borrows trust from the interface before it earns it from the evidence, and the whole job is to make confidence honest.

Research spine: this chapter stays grounded in risk-coverage tradeoff and A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification, then applies that evidence to the operating judgment in the book. Read this alongside the Cost Of Wrong book, the AI-Native thesis, and the full book library when you want the surrounding argument. I want to return to the contract that opened this book, the one that did not auto-renew the way the assistant said it did, and ask a different question about it. Not "how do we make the model more accurate," which was the wrong question, but "what would have made the procurement lead check." The answer is not a better model. The answer is an interface that, instead of bolding the cancellation window, said: I retrieved this from a contract template I could not confirm is the current version; treat as unverified; open the source. That sentence would have cost the company nothing and saved it six figures. It is the whole book in one missing sentence.
That sentence is doubt, designed. And doubt, designed, is not a hedge or an apology or a disclaimer. It is the interface through which an honest system tells the truth about the boundary of what it knows. A confident answer borrows trust from the interface before it earns trust from the evidence. The entire project of this book has been to stop that loan, to make the interface lend confidence only in proportion to what the evidence has actually earned.
What we built
We started by naming the enemy precisely, because a vague enemy produces vague fixes. The enemy is not hallucination and it is not the model. It is fluent interfaces that turn uncertainty into confidence and make wrong answers feel finished. The dangerous failure is not being wrong; it is being wrong in a form that makes humans stop checking. Everything followed from that.
We separated four things casual language collapses: accuracy, confidence, calibration, and authority. Accuracy is how often you are right. Confidence splits into the internal signal the system computes and the external confidence it expresses, and the gap between them is where confident wrongness lives. Calibration is whether confidence tells the truth about accuracy. Authority is borrowed trust from the interface. The catastrophe is the combination, wrong, sounds sure, wrapped in institutional authority, and Guo and colleagues showed us that the trends which improve accuracy can worsen calibration, so you do not get out of the catastrophe by accuracy alone.
Then we built the tools. The Confidence-Cost Matrix to allocate scarce doubt to the danger zone where errors are expensive and confidence is high. The DOUBT pattern, Detect uncertainty, Offer boundaries, Use evidence, Branch safely, Trigger escalation, as the runtime pipeline. The Calibrated Answer Contract, source, scope, freshness, confidence behavior, actionability, escalation rule, as the checkable specification a verifier-policy layer enforces between generation and display. And the Doubt UX Ladder, from subtle cue to human escalation, to express uncertainty in proportion to confidence and stakes without crying wolf.
We grounded those tools in research and in machinery. Showing sources is not enough, because citations add authority without verification and can fail at attribution, source quality, or user behavior; the fix is verified, inline, load-bearing evidence. Abstention and escalation rest on selective prediction and conformal methods that give you a tunable, even guaranteed, risk-coverage tradeoff. Calibration is measured with reliability diagrams and proper scoring rules, each with a trap that lets you fool yourself, and it must be sliced because aggregate calibration hides danger-zone miscalibration. Retrieval quality is a confidence signal that should cap the answer, because weak evidence must be allowed to veto fluent generation. Human review reduces risk only when it is evidence-based, targeted, expert, and has teeth; otherwise it is theater that launders machine output into accountability while adding the illusion of safety. And the economics show that calibrated doubt attacks the one term, the probability of a wrong answer being acted on uncaught, that accuracy cannot reach, while enabling the durable trust that makes high-stakes AI viable at all.
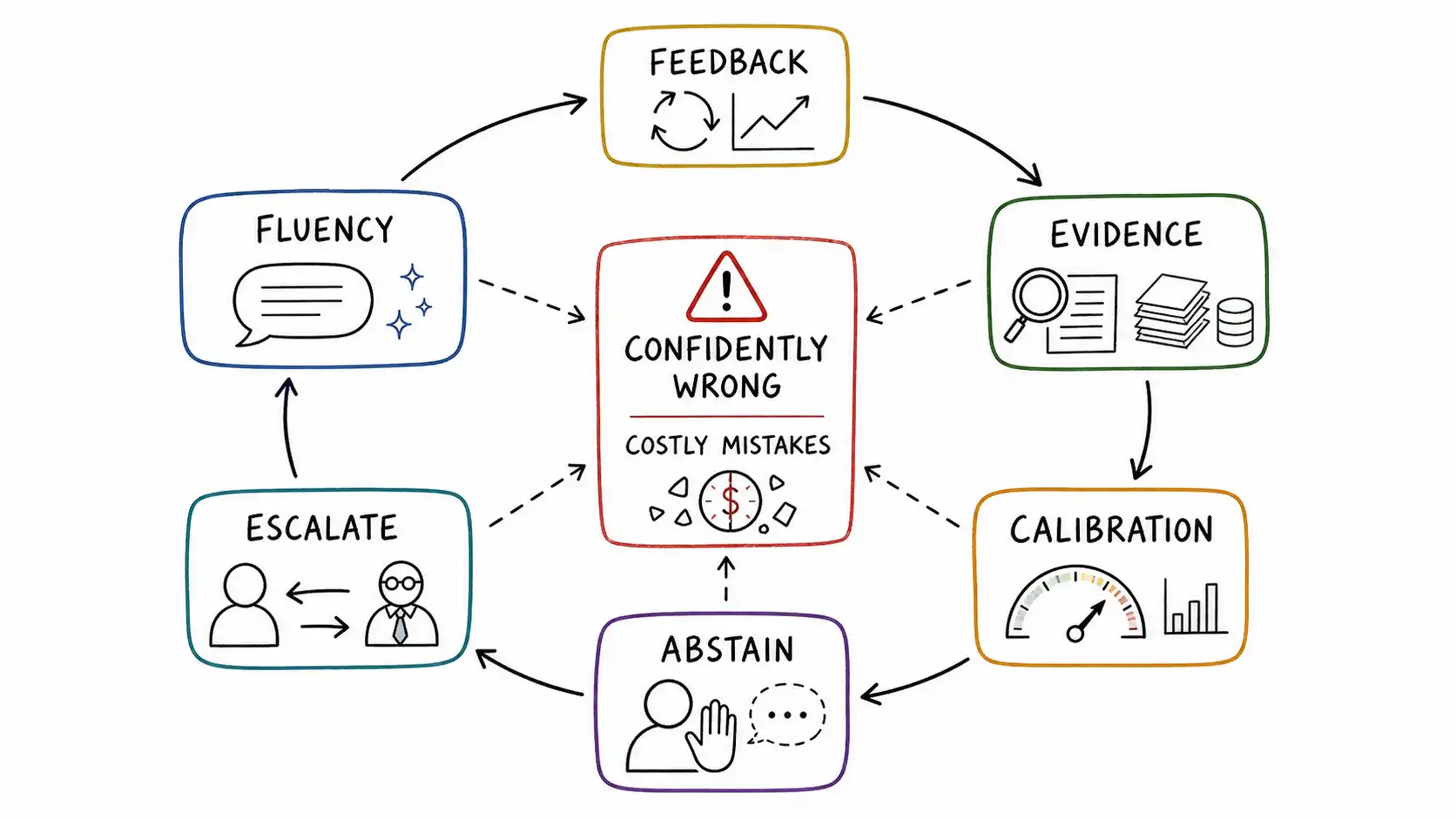
The Calibrated Doubt Checklist
This is the artifact to keep. Run it on any AI feature that produces answers people act on. It is organized by the question each item answers, and every item traces back to a chapter.
Stakes and allocation.
- Have you placed this feature on the Confidence-Cost Matrix, scoring cost of error by reversibility, magnitude, frequency, detectability, and liability?
- For danger-zone features (high apparent confidence, high cost of error), is calibrated doubt treated as mandatory rather than optional?
Confidence and calibration.
- Is expressed confidence a function of an internal confidence signal, or a constant? If constant, that is your first fix.
- Have you built a reliability diagram, looked at the high-confidence bins for overconfidence, and computed calibration per high-stakes slice rather than only in aggregate?
- Do you include a proper scoring rule that punishes confident errors, and do you recompute calibration after every model change?
Evidence.
- Do you verify that cited sources actually support the claim (entailment), rather than just attaching a link?
- Do you score source quality (authority, freshness, specificity, corroboration) and feed it into confidence?
- Do you surface the supporting passage inline so verification does not depend on a click that will not happen?
Retrieval (for RAG).
- Do you read retrieval signals, top match, separation, answer-bearing, freshness, before deciding how confidently to present?
- Does retrieval confidence cap the answer's expressed confidence, so weak evidence vetoes fluent generation?
Doubt expression.
- Do you express uncertainty with a graded ladder (cue, caveat, clarify, options, abstain, escalate) chosen by confidence and stakes, not a single warning banner?
- Is your uncertainty copy well-scoped (specific boundaries) rather than low-competence (vague apology)?
Abstention and escalation.
- Can the system decline to answer below a confidence floor, with an explained reason and a forwarded-context handoff?
- Is there an escalation map with triggers, destinations, and forwarded context, so not every abstention floods a human queue?
Human review.
- If you rely on human review, does the reviewer see evidence and uncertainty, is review targeted, do reviewers have time and expertise, does it have teeth and a feedback loop, and do you measure reviewer accuracy, not just throughput?
- Have you checked that human review is even the right control here, versus abstention or automated verification?
Economics and governance.
- Have you priced the expected cost of a confident wrong answer (P(wrong) x P(acted on uncaught) x six-component incident cost) and put it on the product team's own scorecard?
- Can you produce calibration evidence, diagrams, sliced ECE, scoring-rule trends, escalation rates, as concrete documentation that your AI risk controls work, in the sense the NIST AI RMF Measure and Manage functions expect?
A feature that passes this checklist is not a feature that never errs. No such feature exists. It is a feature that, when it errs, errs in a form that does not make humans stop checking, that flags its own uncertainty, that routes the hard cases to where they get resolved, and that has told the truth, all along, about how much it should be trusted. That is the achievable goal, and it is the right one.
Doubt is not the opposite of confidence
I will leave you with the reframing that I hope outlasts every framework in this book. We tend to think of doubt as the enemy of confidence, as weakness, as the thing that makes a product feel unfinished. That instinct is exactly backwards for AI systems, and it is the instinct that produces confidently wrong products.
In an AI product, doubt is not the opposite of confidence. Doubt is what makes confidence mean something. A system that is confident everywhere is confident nowhere, because its confidence carries no information; you cannot tell the answer it would stake its reputation on from the answer it is guessing. A system that doubts in the right places, that says "this one I am sure of, this one I am not, this one I will not answer, this one needs a human," has confidence that is worth something precisely because it is not universal. Calibrated doubt is what converts confidence from decoration into signal.
So the work is not to make AI sound less sure. It is to make AI sound exactly as sure as it deserves to sound, and to build the interface, the evidence, the abstention, the escalation, and the review so that the sureness is honest. Doubt, designed well, is an interface for truth, because it lets a system tell you what it does not know. It is an interface for safety, because it routes the dangerous cases away from blind action. And it is an interface for trust, because trust, the durable kind that survives the rare error and keeps users coming back, is built only by systems whose confidence has, over time, turned out to be true.
The cost of being confidently wrong is paid by the people who acted on an answer that borrowed more trust than it earned. The whole job, the entire discipline this book has tried to assemble, is to stop the borrowing. Make the confidence honest. Make the doubt visible. Make the evidence do work. And when the system does not know, build it so it can say so. That sentence the procurement assistant never said is the most important feature you can ship.
Key Takeaways
- The dangerous failure is being wrong in a form that stops humans from checking; the fix is making confidence honest, not making the model perfect.
- The four tools compose: the Confidence-Cost Matrix allocates doubt, the DOUBT pattern runs it, the Calibrated Answer Contract specifies it, the Doubt UX Ladder expresses it.
- The Calibrated Doubt Checklist runs across stakes, calibration, evidence, retrieval, doubt expression, abstention, review, and economics; a passing feature errs in catchable, flagged, escalated forms.
- Showing sources, adding a human, and improving accuracy are each insufficient alone; verified evidence, targeted real review, and calibrated doubt are what work.
- Doubt is not the opposite of confidence; it is what makes confidence carry information, converting it from decoration into signal.
- Designed doubt is an interface for truth, safety, and trust; the whole job is to stop answers from borrowing more trust than the evidence has earned.