Retrieval Quality as a Confidence Signal
In a RAG system the retrieval step often knows the answer is shaky before the model speaks, and that signal is usually thrown away.

A production incident taught me this chapter. A RAG-backed internal assistant gave a confidently wrong answer about an HR policy. When we traced it, the model had done nothing unusual. The failure was upstream: the retrieval step had returned three documents, none of which actually contained the policy in question, with similarity scores that were mediocre and clustered, no clear winner. The model, handed three weakly-relevant documents and asked to answer, did what models do: it produced a fluent, confident answer by stitching together plausible-sounding fragments. The retrieval step had effectively already failed, and it had a number that said so, a weak top score with no separation, and that number was never looked at. The model spoke with full confidence over a foundation that retrieval already knew was shaky.
This chapter is about treating retrieval quality as a first-class confidence signal. In a retrieval-augmented system, the retrieval step frequently knows the answer is going to be unreliable before the generator writes a word. That knowledge is one of the cheapest and most valuable uncertainty signals you have, and most systems discard it.
Retrieval is where grounding succeeds or fails, and it has its own failure modes
The premise of RAG is that grounding the model in retrieved documents makes answers faithful. But grounding can only be as good as the retrieval, and retrieval fails in specific, detectable ways that the generator then papers over with fluency.
No good match. The query is about something not well covered in the corpus. Retrieval returns the best it can, but the best is weak. The top similarity score is low. This is the clearest signal: if nothing matches well, you should not answer confidently, and the score tells you.
No separation. Retrieval returns several documents with similar, mediocre scores and no clear winner. This often means the query is ambiguous or the corpus does not contain a single authoritative answer. The generator, handed several weakly-relevant passages, will confidently synthesize, which is exactly the HR-policy failure above. Low separation between the top results is a distinct and important signal, separate from a low top score.
Relevant but not answer-bearing. The retrieved document is genuinely about the topic but does not contain the specific answer. This is the attribution problem from the sources chapter, viewed from the retrieval side. The document is relevant; it just does not say the thing. Similarity scores can be high here, which is why score alone is insufficient and you also need answer-bearing checks.
Stale or contradictory retrieval. Retrieval returns a real, relevant, answer-bearing document that is out of date, or returns two documents that contradict each other and surfaces one. These map to the freshness and corroboration dimensions of the source-quality rubric.
The lesson is that retrieval produces several distinct quality signals, and they fail in distinct ways. Collapsing them into a single "we retrieved something" boolean throws away most of the information. The research on the limitations of retrieval-augmented generation, including work on when RAG helps and when it misleads, consistently finds that retrieval quality, not just the model, governs answer reliability. A useful entry point is the broad survey literature on retrieval-augmented generation such as Retrieval-Augmented Generation for Large Language Models: A Survey by Gao and colleagues, which catalogs retrieval failure modes and the techniques, reranking, query rewriting, retrieval evaluation, that exist precisely because retrieval is the fragile step.
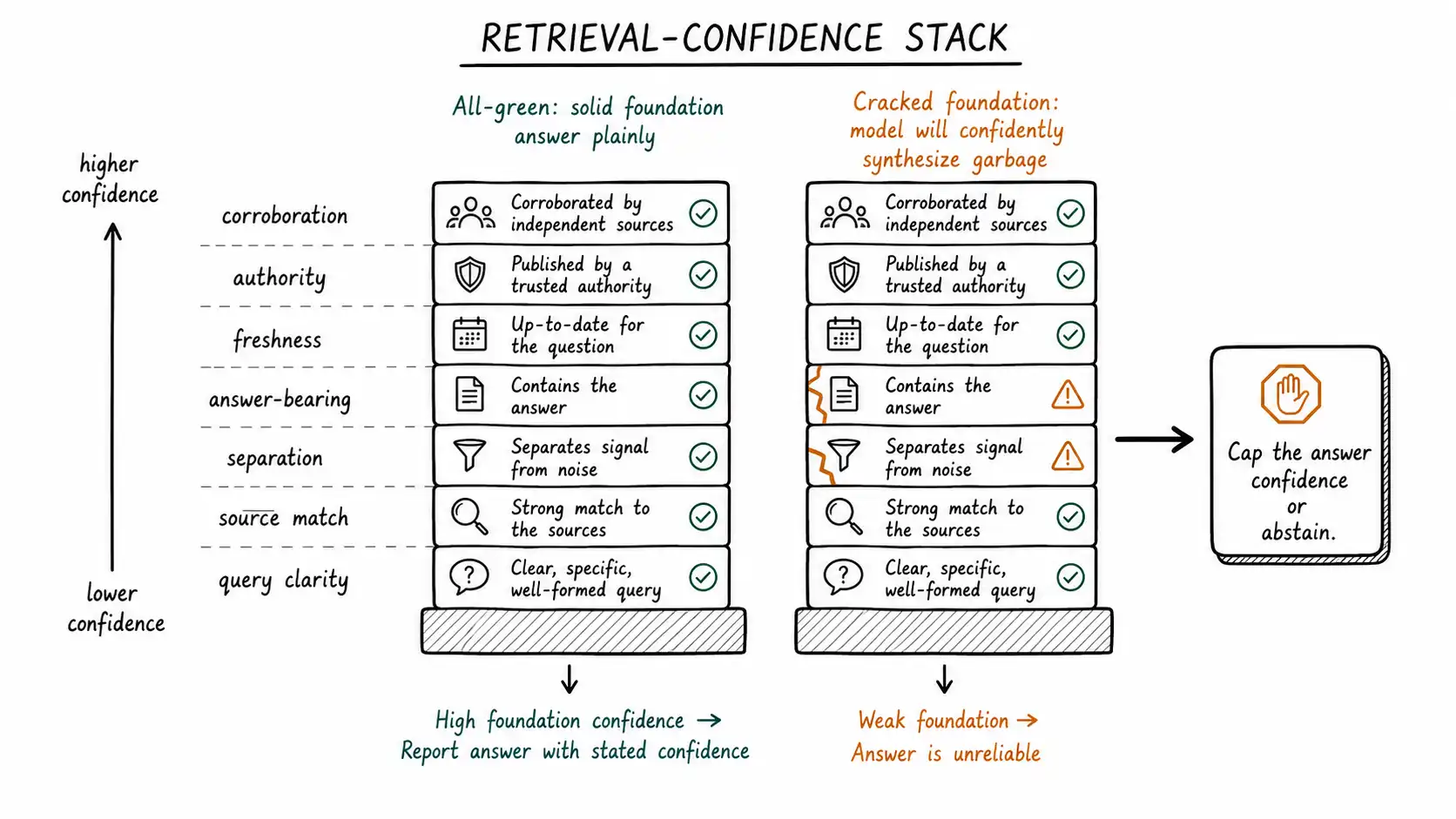
The retrieval-confidence stack
To use retrieval as a confidence signal, decompose it into a stack of measurable layers, each contributing to the internal confidence score that drives the answer contract and the Doubt UX Ladder.
| Layer | Question it answers | Signal |
|---|---|---|
| Query clarity | Is the question well-formed and unambiguous? | Query length, presence of resolvable references, detected ambiguity |
| Source match | Did we retrieve anything that strongly matches? | Top-k similarity scores |
| Separation | Is there a clear winner, or a muddle of weak matches? | Gap between top score and the rest |
| Answer-bearing | Does the top passage actually contain the answer? | Entailment / extraction check |
| Freshness | Is the matched source current enough? | Source update date vs freshness window |
| Authority | Is the source trustworthy for this question? | Source-quality rubric score |
| Corroboration | Do multiple sources agree? | Cross-source consistency |
Read the stack top to bottom and you have a structured, multi-signal picture of whether the foundation under the answer is solid. A high score on source match but a failed answer-bearing check is the relevant-but-not-answer-bearing failure. A muddle on separation is the no-clear-winner failure. Each layer's weakness suggests a different response, and crucially, weakness at any layer should cap the confidence the answer is allowed to express, no matter how fluent the generator is.
The cap principle: retrieval confidence is a ceiling, not just an input
Here is the design move that matters most. Retrieval confidence should function as a ceiling on the answer's expressed confidence, not merely as one input among many that gets averaged. The reasoning is asymmetric. A model can be fluently, internally confident about an answer it synthesized from weak retrieval; that internal fluency is exactly the danger. So you do not want to average a high model confidence with a low retrieval confidence and land in the middle. You want the weak retrieval to cap the answer.
Concretely: if the retrieval stack shows no good match, or no separation, or a failed answer-bearing check, the answer's expressed confidence is capped at "low" regardless of how confident the model sounds. The retrieval weakness vetoes the model's fluency. This is the architectural expression of "a confident answer borrows trust from the interface before it earns it from the evidence." Retrieval confidence is the evidence's vote, and a weak evidence vote should be able to overrule a strong fluency vote, because fluency without evidence is precisely what produces confident wrongness.
In the HR-policy incident, a cap principle would have caught it. Retrieval showed a weak top score and no separation. Under the cap, the answer's confidence would have been forced to low, which would have triggered a caveat or an abstention with escalation, instead of the fluent, confident, wrong answer that actually shipped. The signal existed. The architecture just did not let it win.
Implementing the cap
A minimal implementation that makes retrieval confidence load-bearing:
retrieval_conf = combine(
top_score,
separation = top_score - second_score,
answer_bearing = entailment_check(top_passage, query),
freshness = freshness_ok(top_source),
authority = source_quality_score(top_source)
)
// the cap: weak retrieval vetoes fluent generation
effective_conf = min(model_conf, retrieval_conf)
// weakest-layer diagnosis for the right response
if not answer_bearing: reason = "no passage actually answers this"
elif separation < SEP_FLOOR: reason = "no clear authoritative source"
elif top_score < MATCH_FLOOR: reason = "nothing matched well"
elif not freshness: reason = "source may be out of date"
map effective_conf -> answer-contract band -> ladder rung -> escalationThe min is the cap. The weakest-layer diagnosis is what lets your abstention or caveat be specific rather than generic, the "explain why" requirement from the abstention chapter. "I could not find a document that directly answers this" is far better than "I'm not sure," and the retrieval stack hands you that specific reason for free, because it knows which layer failed.
Improving retrieval is part of calibrating the system
Because retrieval quality caps answer confidence, improving retrieval directly raises the ceiling and lets you answer more cases confidently and correctly. This reframes retrieval engineering as calibration work, not just relevance work.
Better chunking and indexing raise source-match and answer-bearing scores, so more answers clear the cap legitimately. Reranking improves separation, distinguishing a clear winner from a muddle. Query rewriting improves query clarity, reducing the ambiguity that produces low-separation retrieval. Maintaining corpus freshness and pruning stale documents directly addresses the freshness layer. Each of these is a standard RAG improvement technique, but framed through the cap principle, their value is not just "more relevant results"; it is "higher legitimate confidence ceiling, so we abstain less and answer correctly more." That is a more honest and more fundable framing than generic relevance improvement, because it ties retrieval work directly to the reliability outcome leadership cares about.
The inverse is also a discipline: do not raise the cap you cannot support. If you cannot improve retrieval for a given high-stakes answer type, the correct response is to keep the confidence capped and abstain more, not to let the generator's fluency paper over the weak foundation. The temptation, especially under pressure to show coverage, is to loosen the cap. Loosening the cap is choosing confident wrongness, and it should require an explicit, owned decision, not a quiet threshold tweak.
Retrieval confidence and the broader uncertainty signal
Retrieval confidence is one input to the multi-signal detection from the abstention chapter, but in a RAG system it is often the dominant one, because RAG answers are supposed to be grounded in retrieval, so weak retrieval undermines the entire premise. The other signals, model confidence, consistency, verifier agreement, remain important, especially verifier agreement, which overlaps with the answer-bearing layer. The clean mental model: retrieval confidence tells you whether the foundation is solid; verifier agreement tells you whether the building matches the foundation; model confidence tells you how sure the builder feels, which you trust least of the three. Combine them, but let the foundation cap the height.
One more connection worth making explicit. The retrieval stack is also a diagnostic for your corpus, not just for individual answers. If a particular answer type consistently produces low source-match or failed answer-bearing checks, your corpus is missing content, not just your retrieval is weak. The same signals that protect individual answers, aggregated over time, tell you exactly where your knowledge base has holes. That makes retrieval confidence a product-improvement signal as well as a safety signal: the cases you keep abstaining on are a prioritized list of content to go create.
Practical exercise: the retrieval-confidence audit
Take a high-stakes RAG answer type and pull a sample of answers, ideally with correctness labels.
For each answer, record the retrieval stack: top similarity score, separation between top and second, whether the top passage actually answers the question, source freshness, source authority. Then correlate these with correctness.
You are looking for the relationship between retrieval quality and answer correctness. In almost every system I have audited, the correlation is strong: the wrong answers cluster in the weak-retrieval cases, low top score, low separation, failed answer-bearing. That correlation is your evidence that retrieval confidence is a usable signal, and it tells you where to set the cap thresholds.
Then ask the diagnostic question: does your current system look at any of these retrieval signals before deciding how confidently to present the answer? If the answer is no, that the model generates and presents with uniform confidence regardless of retrieval quality, you have found a high-use fix that requires no model change at all. You are already computing the signals; you are just throwing them away at the moment of presentation, which is the central crime of this entire book.
Summary
In a RAG system, retrieval frequently knows an answer will be unreliable before the model speaks, and that signal is usually discarded. Retrieval fails in distinct, detectable ways: no good match, no separation among weak matches, relevant-but-not-answer-bearing passages, and stale or contradictory sources. Decompose retrieval into a confidence stack, query clarity, source match, separation, answer-bearing, freshness, authority, corroboration, each measurable and each capping the answer's allowed confidence. The cap principle is the key move: retrieval confidence is a ceiling, not an averaged input, so weak retrieval vetoes fluent generation rather than splitting the difference. Improving retrieval raises the legitimate confidence ceiling, reframing retrieval engineering as calibration work, and the cases you keep abstaining on are a prioritized list of corpus gaps. The fix usually requires no model change, only looking at signals you already compute. Human Review Theater Versus Real Review examines what happens when those signals reach a human reviewer - and why the review usually fails unless it is engineered against automation bias.
Key Takeaways
- Retrieval often knows an answer is shaky before the model speaks; that signal is one of the cheapest and most-discarded uncertainty signals in RAG.
- Retrieval fails in distinct ways: no good match, no separation, relevant-but-not-answer-bearing, and stale or contradictory sources; each needs a different response.
- Decompose retrieval into a confidence stack (query clarity, source match, separation, answer-bearing, freshness, authority, corroboration), each measurable.
- The cap principle: retrieval confidence is a ceiling on expressed confidence, not an averaged input, so weak evidence vetoes fluent generation.
- Improving retrieval raises the legitimate confidence ceiling, making retrieval engineering a form of calibration work, not just relevance work.
- The fix is usually free of model changes: you already compute these signals, you are just discarding them at presentation, and persistent abstentions map your corpus gaps.