Why Fluency Feels Like Competence
Humans read smoothness, structure, and tone as evidence of correctness, and AI produces those signals for free.

Run a small experiment in your own head. Picture two answers to a tax question. The first is hesitant, has a typo, hedges twice, and gets the answer right. The second is crisp, formatted with a clean numbered list, uses confident phrasing like "the rule is straightforward," and gets the answer wrong. Now ask which one a busy person forwards to a colleague without rereading. You already know. The second one. The polish did the persuading, and the polish was free of any obligation to be correct.
This chapter is about that reflex. Not about what the model knows, but about what the human infers from how the model talks. Because the gap that costs money is not between the model's knowledge and the truth. It is between the model's presentation and the model's knowledge, and then between that presentation and the human's willingness to check.
Fluency is a cheap signal, and we treat it as expensive
For most of human history, fluent, structured, confident expression correlated with competence. Producing a clear, well-organized, authoritative explanation took knowledge, effort, and usually some expertise. The signal was costly to fake, so we learned to trust it. A person who could explain your contract clearly probably understood your contract.
Language models break that correlation at its root. They are, at their core, machines optimized to produce fluent, plausible, well-structured text. Fluency is not a byproduct of their understanding. Fluency is the objective. A model can generate a beautifully organized, confidently worded, grammatically flawless explanation of something it has fundamentally misretrieved or fabricated, and it will spend exactly the same amount of effort doing so as it spends on a correct answer. The signal that used to be expensive is now free, and our trust heuristics have not updated.
This is the deep mechanism behind the whole book. We evolved and were socialized to read fluency as a proxy for competence. AI severs the link between the proxy and the thing it used to track, while leaving the proxy fully intact and, if anything, stronger. The model is often more fluent than the human expert, because it never hesitates, never qualifies out of genuine uncertainty unless told to, and never lets a typo through.
The processing fluency effect has a research record
This is not folk psychology. Cognitive psychology has a long line of work on what is called processing fluency, the subjective ease with which information is processed, and its effect on judgment. When something is easier to read or process, people judge it as more true, more likable, and more trustworthy, independent of its actual content.
The cleanest classic demonstration is Reber and Schwarz's work on perceptual fluency and truth judgments, which showed that statements presented in higher color contrast, and so easier to read, were rated as more likely to be true than identical statements in lower contrast. The effect is summarized well in the broader research program described in Alter and Oppenheimer's review, Uniting the Tribes of Fluency to Form a Metacognitive Nation, which catalogs how fluency leaks into judgments of truth, confidence, frequency, and risk across dozens of studies. The mechanism is simple and ancient: the brain uses ease of processing as a cue, because for most of our history, familiar and easy-to-process things really were safer and more likely to be true.
Generative AI is a processing-fluency engine. It produces text that is maximally easy to process: well-structured, confidently toned, free of the friction that genuine uncertainty introduces. So it pulls every one of the fluency levers that the research says inflate perceived truth, regardless of whether the content is true. The interface then adds its own fluency on top: clean typography, instant response, authoritative formatting. We have, without meaning to, built a system that is optimized along exactly the dimension that fools human truth judgment.
Confidence in language is a separate lever, and the model pulls it too
Beyond the ease of reading, there is the matter of expressed confidence. Humans use other people's expressed confidence as a strong cue to their competence and accuracy. We trust the doctor who says "this is appendicitis" more than the one who says "it might be appendicitis, I'd want to confirm," even though the second is often the better clinician.
There is experimental work on this too. Price and Stone, in research on what is sometimes called the confidence heuristic, showed that people prefer and place more weight on advisors who express higher confidence, and they continue to do so even when confidence is not well matched to accuracy. We are tuned to read confidence as competence. A language model, by default, expresses high linguistic confidence almost everywhere. It says "the answer is" rather than "the answer might be." It rarely volunteers the qualifications a careful human expert would add, because nothing in the default training objective rewards calibrated hedging over fluent assertion.
So you have two independent fluency levers, processing ease and expressed confidence, and the model pulls both, hard, on every answer, with no relationship to whether the underlying content deserves it. The human, reading both signals, infers competence. The inference is rational given our priors. It is just wrong now, because the priors were built for a world where those signals cost something.
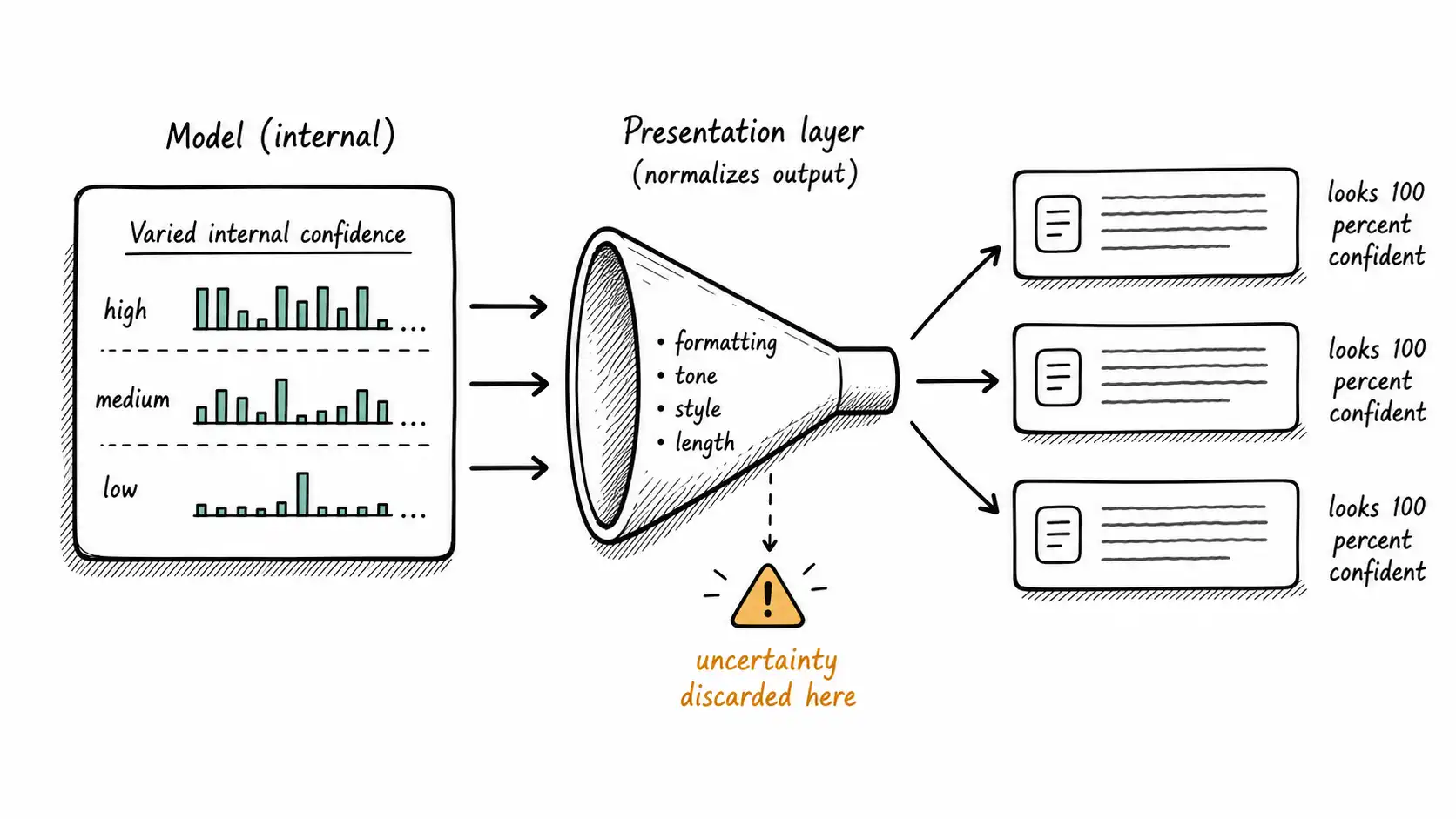
The internal uncertainty exists; the interface throws it away
Here is the cruel irony. The model frequently does have an internal sense of uncertainty. A classifier produces a probability. A language model produces a distribution over next tokens, and there are well-studied ways to extract token-level and sequence-level confidence signals. A retrieval system produces similarity scores. There is real uncertainty information flowing through the pipeline.
The problem is that the final presentation layer almost always discards it. The model's internal token probabilities, the retrieval similarity scores, the verifier's disagreement: all of it gets compressed into a single fluent paragraph that reads identically whether the system was 99 percent confident or guessing. The uncertainty was computed and then thrown away at the exact moment it mattered most, the moment of presentation to a human.
This is why I keep insisting the enemy is the interface, not the model. The model is often less wrong, internally, than its output suggests. The fluent presentation layer is where calibrated internal states get laundered into uniform external confidence. If you want to fix confidently wrong systems, the highest-use place to intervene is frequently not the model at all. It is the function that decides how the answer is rendered.
Worked example: the same wrong answer, three ways
To make this concrete and operational, here is a single wrong answer about a refund policy, rendered three ways. The content is identically wrong in all three. Only the presentation changes.
| Version | Copy | What the human infers |
|---|---|---|
| Maximum fluency | "Yes, you can request a refund within 90 days of purchase. Simply contact support with your order number." | This is settled. Forward it. |
| Stripped fluency | "i think it might be 90 days? not totally sure, you'd want to confirm" | Better check the policy page. |
| Calibrated | "The policy I found says 90 days, but I retrieved it from a help-center page last updated 14 months ago and could not confirm it against the current terms. Treat as unverified; I can route this to a human agent." | Verify before acting; escalation offered. |
Notice that the calibrated version is not the unconfident version. The stripped-fluency version is just sloppy, and sloppiness is its own problem because it makes the system look incompetent even when it is right, which feeds the algorithm aversion we will discuss later. The calibrated version is confident about what it knows (it found a page saying 90 days) and explicit about what it does not (whether that page is current). That distinction, between expressing low competence and expressing well-scoped uncertainty, is the entire craft. We will spend the rest of the book on it.
The asymmetry that makes this dangerous
There is a structural asymmetry worth naming. Fluency helps the model in exactly the cases where it should not.
When the model is right, fluency is fine. The answer is correct, the human trusts it, no harm done. When the model is wrong but obviously sloppy, fluency is low, the human's guard goes up, and they check. The dangerous quadrant is when the model is wrong but fluent. There, fluency actively suppresses the human's verification reflex precisely when verification was most needed. The presentation is doing harm in inverse proportion to the content's reliability.
This is why uniform high confidence is not a neutral default. It is a default that concentrates risk into the worst cases. A system that sounded uncertain at random would at least sometimes raise the alarm by accident. A system that sounds uniformly confident raises the alarm never, including when the building is on fire.
What this means for builders
A few consequences follow directly, and I will state them as commitments you can make this week.
First, treat the presentation layer as a safety-critical component, not a styling concern. The function that decides how to render an answer is making a risk decision. It deserves the same review you would give a function that decides whether to ship money.
Second, do not let your default output style express more confidence than your pipeline has earned. If you cannot attach an internal confidence signal to an answer, your default should be more hedged, not less. Polish should be earned by evidence, not granted by template.
Third, resist the temptation to fix fluency problems by reducing fluency globally. The answer is not to make the model sound dumber. A model that hedges on everything trains users to ignore hedging, the boy-who-cried-wolf failure, and it also feeds the well-documented tendency for people to abandon systems that look unsure. The answer is selective, evidence-linked confidence: sound certain when you have earned it, sound uncertain when you have not, and make the difference legible.
Fourth, instrument the gap. You can measure, today, the correlation between the confidence your interface displays and the accuracy of the underlying answers. If your interface displays roughly the same confidence everywhere, that correlation is approximately zero, which means your presentation is carrying no information about reliability. That is a finding you can put in front of leadership.
Practical exercise
Take one AI feature you ship. Pull twenty real outputs, ten correct and ten wrong, with the correctness labeled by a human. Strip the metadata and show the twenty answers to three colleagues who do not know which are which. Ask each colleague to rate, on a simple scale, how confident the answer sounds and how likely they would be to act on it without checking. Then compute the correlation between their "would act without checking" rating and the actual correctness.
If that correlation is near zero, your interface is fluent in a way that carries no information about truth. That is the precise failure this chapter describes, and you now have a number for it. Keep that number. We will use it as a baseline when we get to calibration measurement.
Summary
Humans read fluency, both ease of processing and expressed confidence, as a proxy for competence, because for most of history those signals were costly and correlated with knowledge. Language models produce both signals for free, severing the correlation while leaving the proxy intact. The research on processing fluency and the confidence heuristic explains exactly why polished wrong answers persuade. The model often computes real uncertainty, but the presentation layer discards it, laundering calibrated internal states into uniform external confidence. This concentrates risk into the worst quadrant, wrong but fluent, where presentation actively suppresses verification. The fix is not less fluency everywhere; it is selective, evidence-linked confidence, treating the presentation layer as a safety-critical component. Accuracy, Confidence, Calibration, and Authority names the four properties that casual conversation collapses - and shows why optimizing any one while ignoring the others is where products fail.
Key Takeaways
- Fluency used to be a costly, reliable signal of competence; language models make it free, breaking the correlation our trust heuristics depend on.
- Processing fluency research (Reber and Schwarz; Alter and Oppenheimer) shows ease of reading inflates judged truth independent of content.
- The confidence heuristic means people overweight confidently expressed advice even when confidence does not track accuracy.
- The pipeline computes real uncertainty, then the presentation layer throws it away at the exact moment it matters.
- Risk concentrates in the wrong-but-fluent quadrant, where polish suppresses verification precisely when it was most needed.
- The fix is selective, evidence-linked confidence, not globally dumber output, and the presentation layer should be reviewed as safety-critical.