The Economics of Doubt
Calibrated doubt is an expected-value decision, and the rare confident wrong answer usually dwarfs the value of the marginal answers you decline to give.

Research spine: this chapter stays grounded in risk-coverage tradeoff and A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification, then applies that evidence to the operating judgment in the book. Every argument in this book eventually meets a budget meeting. Someone with a spreadsheet asks why they should pay, in latency, engineering, friction, and coverage, for doubt machinery that makes the product slower and less impressive in the demo. This chapter answers that person on their own terms, with expected-value math and incident accounting, because the case for calibrated doubt is not moral, it is economic. The teams that under-invest in doubt are not being bold; they are mispricing a tail risk, and tail risks are exactly the ones that look free until they are not.
The expected-cost equation
Start with the equation that should govern the decision. For a given AI answer type, the expected cost of being wrong is, roughly:
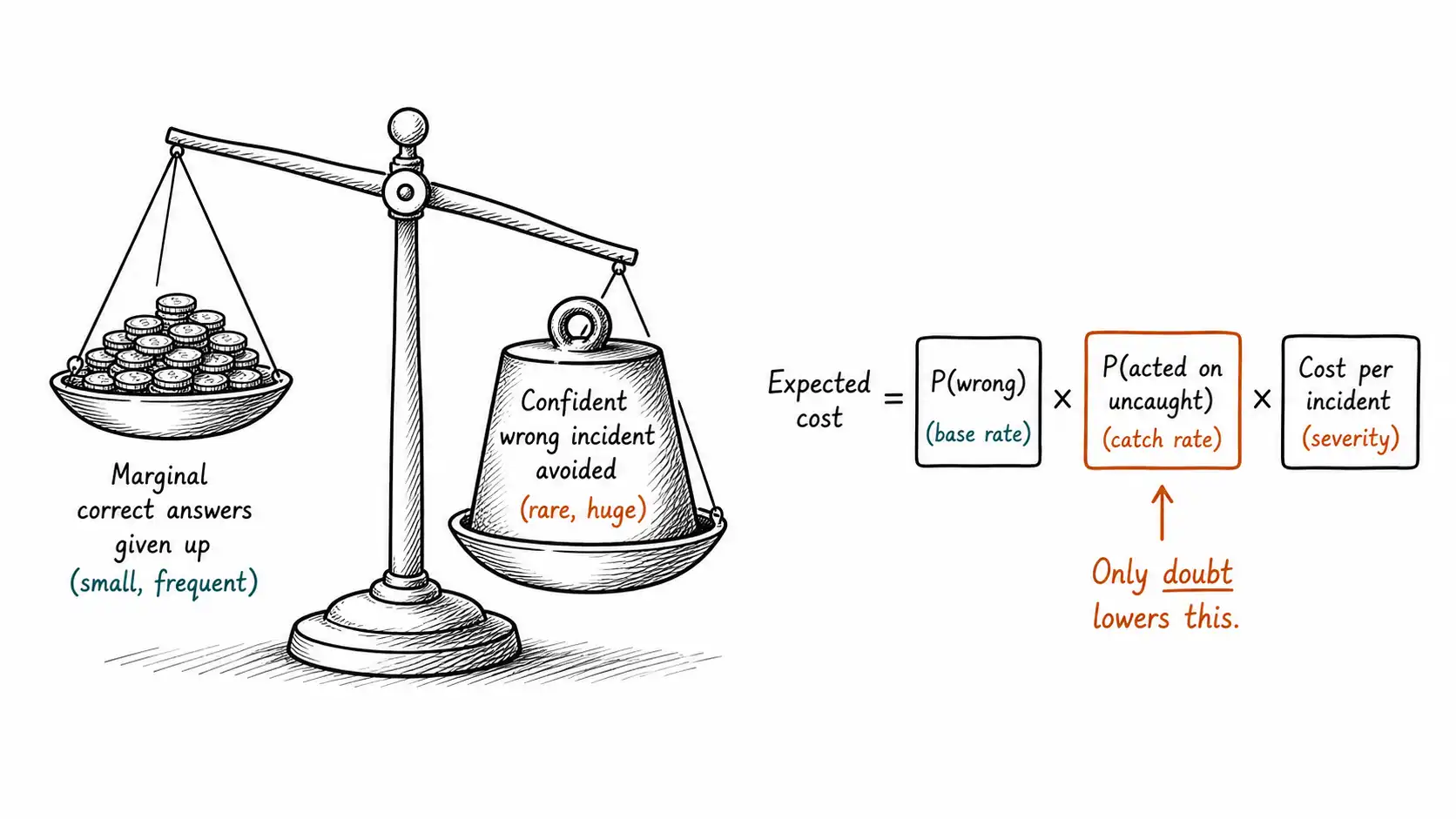
expected_cost_of_error = P(wrong) x P(acted on without catching) x cost_per_incidentThree terms, and the whole book has been about manipulating them. P(wrong) is reduced by accuracy and by retrieval quality. P(acted on without catching), the probability that a wrong answer is acted on without anyone catching it, is the term the fluent interface inflates and that calibrated doubt, abstention, evidence, and real review reduce. Cost per incident is set by the stakes, the reversibility, the magnitude, and the liability, the decomposition from the Confidence-Cost Matrix.
The crucial insight is the middle term. Most teams focus entirely on P(wrong), trying to make the model more accurate. But the fluent-interface problem is that P(acted on without catching) is near 1 in a confidently-wrong system, because the whole point of confident wrongness is that nobody catches it. So a system with low P(wrong) but P(acted on without catching) near 1 still carries large expected cost on its rare errors, and improving accuracy alone leaves that middle term untouched. Calibrated doubt is the only lever that drives the middle term down, by making the wrong answers catchable, hedged, abstained, or escalated. That is why doubt is not a nice-to-have on top of accuracy. It attacks a term that accuracy cannot reach.
The asymmetry that justifies abstention
Now the abstention economics promised earlier. Abstaining means declining to answer some cases, which has a cost: the lost value of the correct answers you would have given among the cases you abstained on. The skeptic frames this as pure loss. The expected-value frame shows it is usually a bargain in the danger zone.
Consider a high-stakes answer type. Suppose answering correctly is worth a modest amount per case, call it the value of automating that interaction. Suppose a confident wrong answer that gets acted on costs a large amount, the Air Canada-style liability, the six-figure contract, the regulatory exposure. Now suppose you tighten your abstention threshold so you decline the least-confident 5 percent of cases, the cases where most of your errors live. You lose the value of the correct answers within that 5 percent (small per case, and only a fraction of that 5 percent would have been correct anyway). You avoid a disproportionate share of your expensive wrong answers, because errors concentrate in the low-confidence cases, that is what calibration means.
The trade is: give up a small, frequent, low-magnitude value to avoid a rare, high-magnitude cost. When the cost per incident dwarfs the value per answer, which is the definition of the danger zone, this trade is overwhelmingly positive in expectation. The coverage you give up is mostly the coverage you were going to get wrong. Abstention is not lost value; it is risk avoided, and in the danger zone risk avoided is worth far more than the marginal coverage. This is the rigorous version of the claim from the abstention chapter, and it is the slide that wins the budget meeting: a simple expected-value table showing that for high-stakes answer types, the avoided-incident cost exceeds the lost-coverage value by a wide margin.
The cost of doubt is real, so price it honestly
I am not going to pretend doubt is free. It has four real costs, and an honest economic case prices all of them, because a one-sided case loses credibility the moment the skeptic names the cost you ignored.
Latency. Verification, source-quality scoring, and conformal computation add milliseconds to seconds. For interactive products this matters, and you pay it only where the stakes justify it, which is again why the Confidence-Cost Matrix exists: full doubt machinery in the danger zone, lighter elsewhere.
Engineering cost. The verifier-policy layer, the calibration measurement, the escalation routing, the review surfaces, all of it is real engineering. It is, however, build-once, reuse-across-features infrastructure, not per-feature cost, which improves the economics substantially once you have it.
Friction and perceived capability. Caveats, abstentions, and escalations make the product feel less magical in the demo, and a poorly-designed version (the yellow banner) genuinely hurts adoption. This is the cost the doubt-UX chapter addresses: well-scoped uncertainty builds trust, sloppy uncertainty destroys it, so the friction cost is largely a design-quality problem, not an inherent one.
Lost coverage. The abstained cases, priced above. Real, but in the danger zone dominated by the avoided-incident value.
Add these up and you have the cost side. The point is not that doubt is free; it is that in the danger zone the cost is small relative to the tail risk it removes, and outside the danger zone you should not be paying most of it anyway. An honest accounting wins more budget meetings than an enthusiastic one, because the skeptic with the spreadsheet trusts the person who already counted the costs they were about to raise.
Why the cost is systematically underpriced
The tail risk of confident wrongness is underpriced for predictable behavioral-economics reasons, and naming them helps you make the case to leadership.
The errors are rare and the successes are frequent, so the track record is dominated by successes, which makes the system feel safe, the overtrust mechanism applied to the organization itself. The team sees thousands of correct answers and one rare error feels like an anomaly rather than an expected tail event.
The errors are invisible until they cause harm, by the fluent-interface mechanism, so they do not show up in the metrics teams watch. A confident wrong answer that gets acted on does not throw an exception or spike an error rate; it succeeds, in the system's terms, and fails only in the world. So the cost is incurred off the dashboard and arrives as a surprise.
The incident, when it comes, is often someone else's line item, legal, a customer refund, a regulatory fine, reputational damage, not the product team's. The team that under-invested in doubt is rarely the team that pays for the incident, which is a classic externality and a classic source of under-investment. The fix is organizational: put the expected cost of confident wrongness on the product team's own scorecard, so the incentive to prevent it lands where the prevention work happens.
And the cost is a distribution, not a point. Most of the time the under-invested system is fine, which makes the under-investment look smart right up until the tail event, at which point it looks like negligence. Mispricing a tail risk feels like prudence until the tail arrives.
A worked incident accounting
Let me make the cost-per-incident term concrete with the components an actual confident-wrongness incident generates, drawn from the public cases and from incidents I have seen.
Direct cost: the immediate financial consequence, the refund honored, the contract locked in, the wrong figure that had to be corrected.
Remediation cost: the engineering and operational scramble to find every other instance of the same error, fix the system, and re-verify affected outputs. One confident wrong answer is rarely alone; the same flaw produced others you now have to hunt down.
Liability and legal cost: as in Moffatt v. Air Canada, the deploying company owns the answer. Legal time, damages, and the precedent set are all real, and the precedent compounds across future cases.
Reputational cost: the hardest to quantify and often the largest. The Mata v. Avianca lawyers are a cautionary tale partly because the reputational damage vastly exceeded the sanction. A widely-reported confident-wrongness incident damages trust in the product and the brand in ways that suppress adoption long after the direct cost is paid.
Trust-recovery cost: after an incident, users (internal or external) stop trusting the system, which destroys the value the system was supposed to create. You may have to add so much friction and review to rebuild trust that the product's economics never recover. This is the cruelest cost: the incident does not just cost the incident, it can cost the entire value proposition.
Sum these and the cost per incident for a danger-zone answer type is rarely small. Putting even a rough number on each component, in a budget meeting, reframes the doubt investment from "overhead that slows the demo" to "cheap insurance against a cost we can now actually see." Most teams have simply never done this accounting, which is why the doubt investment looks optional. It is not optional; it is unpriced.
The ROI framing that funds the work
To get doubt funded, translate it into the language budgets respond to. The investment in calibrated doubt, the verifier-policy layer, calibration measurement, escalation, real review, has a return equal to the expected incident cost it avoids, plus the trust-driven adoption it enables, minus the doubt costs priced above.
The adoption term deserves emphasis because it is the positive case that the defensive framing misses. A calibrated product that users learn to trust gets used more, because trust drives usage, and a product that users have learned to distrust after an incident gets used less. So calibrated doubt is not only insurance against the downside; it is an enabler of the upside, because durable adoption requires durable trust, and durable trust requires that the system's confidence be honest. The teams that win long-term in high-stakes AI are not the ones with the most impressive demos; they are the ones whose users have learned, over time, that the system tells the truth about what it knows, including when it does not know. That earned trust is the moat, and calibrated doubt is how you build it.
So the ROI story has two halves: downside avoided (the expected incident cost) and upside enabled (durable, trust-driven adoption). Framed that way, calibrated doubt stops being a cost center and becomes the thing that makes a high-stakes AI product viable at all. A confidently-wrong product in a high-stakes domain is not a cheaper version of a calibrated one; it is a liability with a demo, and the demo's appeal is exactly the trap.
Practical exercise: build the doubt business case
For your highest-stakes answer type, build a one-page expected-value case.
Estimate the three terms of the expected-cost equation: P(wrong) from your calibration measurement, P(acted on without catching) honestly (in a confidently-wrong system, near 1), and cost per incident using the six-component accounting above. Multiply for the expected cost of error per period.
Then estimate the doubt investment: the engineering (build-once), the latency and friction (priced where it applies), and the lost coverage from your chosen abstention operating point.
Put them side by side. For a genuine danger-zone answer type, the expected cost of error should dwarf the doubt investment, and the abstention trade, small frequent value given up for rare huge cost avoided, should be clearly positive. If it is not, you have learned something important: either this answer type is not actually high-stakes, or your accuracy is high enough that the tail is small, in which case do not over-invest. Either way, you have replaced intuition with a number, which is what gets the work funded or correctly de-prioritized.
Summary
The case for calibrated doubt is economic. The expected cost of error is P(wrong) times P(acted on without catching) times cost per incident, and the fluent interface inflates the middle term to near 1, which accuracy improvements cannot touch but calibrated doubt can. Abstention trades small, frequent, low-magnitude value for rare, high-magnitude cost avoided, a strongly positive trade in the danger zone because errors concentrate in low-confidence cases. Doubt has real costs, latency, engineering, friction, lost coverage, and an honest case prices all of them, but in the danger zone they are small relative to the tail risk removed. The tail is systematically underpriced because errors are rare, invisible until harm, often someone else's line item, and distributional. A six-component incident accounting (direct, remediation, liability, reputational, trust-recovery) shows cost per incident is rarely small. The ROI has two halves: downside avoided and durable trust-driven adoption enabled, making calibrated doubt the thing that makes high-stakes AI viable. The conclusion assembles the full Calibrated Doubt Checklist and articulates the design stance that holds it together.
Key Takeaways
- Expected cost of error is P(wrong) x P(acted on without catching) x cost per incident; the fluent interface inflates the middle term, which only calibrated doubt can lower.
- Abstention trades small, frequent value for rare, huge cost avoided, a strongly positive trade in the danger zone because errors concentrate in low-confidence cases.
- Doubt has real costs (latency, engineering, friction, lost coverage); an honest case prices all of them, and in the danger zone they are dominated by the avoided tail risk.
- The tail is underpriced because errors are rare, invisible until harm, often charged to another team, and distributional; put the expected cost on the product team's own scorecard.
- Cost per incident has six components, direct, remediation, liability, reputational, trust-recovery, and trust-recovery can cost the entire value proposition.
- Calibrated doubt is both insurance against the downside and an enabler of durable, trust-driven adoption; a confidently-wrong high-stakes product is a liability with a demo.