Introduction: The Answer That Sounded Finished
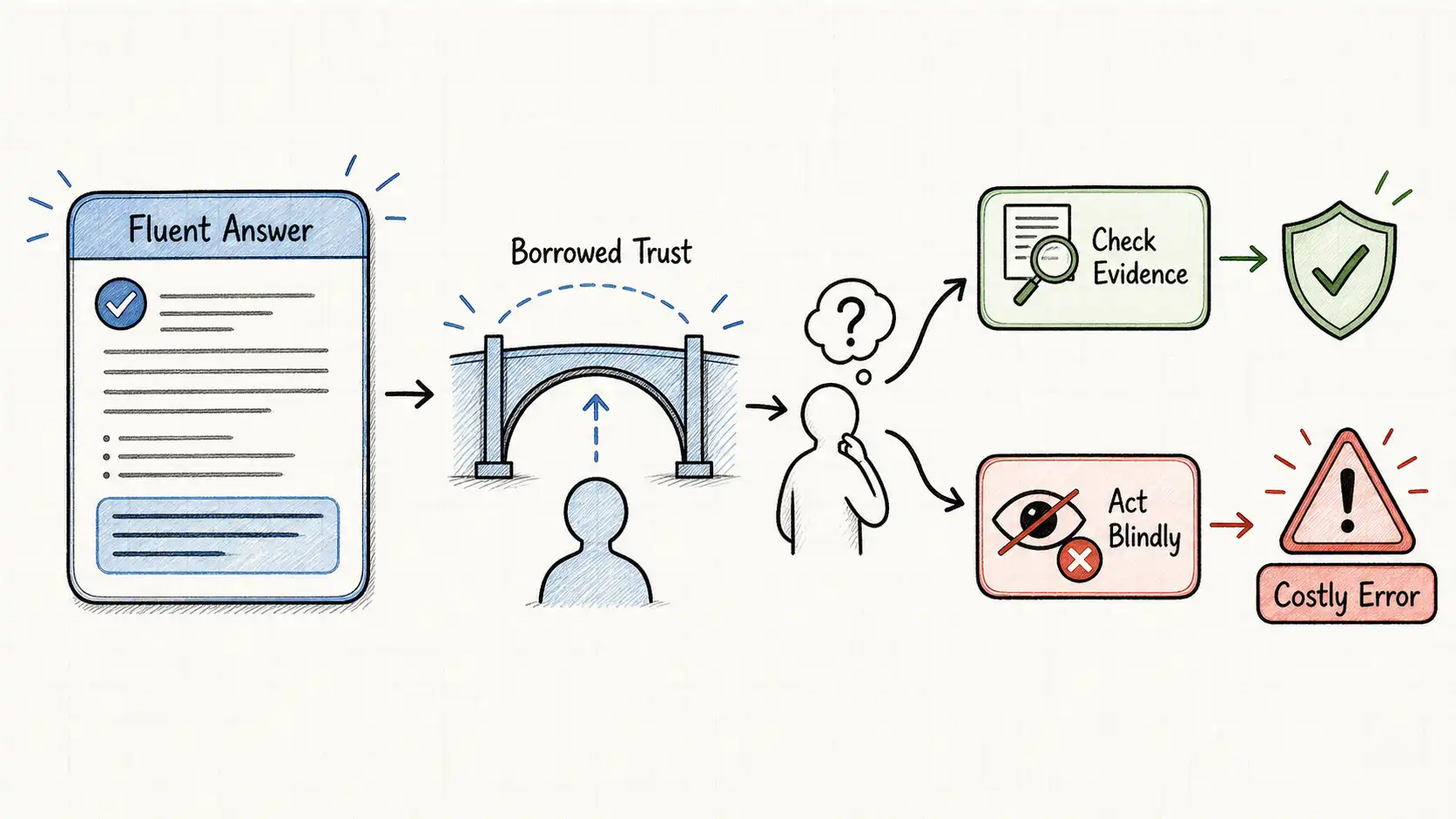
The dangerous AI failure is not being wrong, it is being wrong in a form that makes people stop checking.

A procurement lead at a mid-market manufacturer asked the company's new AI assistant a narrow question: does our master services agreement with a particular cloud vendor auto-renew, and what is the notice window to cancel. The assistant answered in four crisp sentences. It said the contract auto-renewed annually, that the cancellation notice window was sixty days, and that the next renewal date was in March. It even formatted the notice window in bold. The procurement lead forwarded the answer to finance, finance planned around the March date, and nobody opened the actual contract.
The contract did not auto-renew annually. It auto-renewed for a three-year term, the notice window was ninety days, and the relevant date had already passed. The company was locked into another three years at a rate it had intended to renegotiate. The cost of the mistake ran into six figures. The assistant had retrieved the wrong document, an older template that had been superseded, and presented its summary with the same fluent confidence it used for everything else.
Here is the part worth sitting with. The model was not malfunctioning. It produced a grammatical, well-structured, plausible answer. The retrieval system returned a real document. The interface rendered it cleanly. Every component did roughly what it was built to do. The failure was not in any single part. It was in the seam between a system that sounded certain and a human who, reading that certainty, decided not to check. The bold formatting did real damage. It signaled finality. A confident answer borrows trust from the interface before it earns trust from the evidence.
The enemy of this book
This is not a book about hallucination in the narrow sense. Hallucination, the generation of fluent false content, is a real phenomenon and it has been studied carefully. But framing the problem as hallucination quietly locates the fault inside the model and implies the fix is a better model. That framing is incomplete and, for the people who build and deploy these products, mostly useless.
The real enemy is broader and more uncomfortable. It is fluent interfaces that turn uncertainty into confidence and make wrong answers feel finished. The damage is done in the gap between what the system knows and how the answer is presented. A model can be uncertain internally, the retrieval can be weak, the source can be stale, and none of that reaches the user, because the output layer flattens every state into the same calm, complete, well-formatted paragraph. The interface is where uncertainty goes to die.
That is why a better model does not, on its own, solve this. A more accurate model that is still presented with uniform confidence simply moves the errors to rarer and higher-stakes cases, where the human has been trained by thousands of correct answers to stop checking entirely. Accuracy without calibration can make the failure mode worse, not better, because it builds exactly the overtrust that the rare error then exploits.
What this book is not
I want to be precise about scope, because adjacent books have already been written and I am not writing them again.
This is not a generic hallucination explainer. I assume you already know language models produce confident false text. The interesting question is what to do at the product and interface level.
This is not a mathematical uncertainty textbook. We will use calibration, proper scoring, selective prediction, and conformal methods, and I will cite the primary literature so you can go deeper. But the math is in service of decisions, not the other way around.
This is not a prompt list. You will not find twenty prompts that reduce hallucinations. Prompting is a tactic inside a system, not a strategy for the system.
This is not a compliance-only book. Governance frameworks like the NIST AI Risk Management Framework matter and we will use them, but a book that ends at the audit checklist has not helped the engineer choosing what to render at 2 a.m.
And this is not an anti-AI book. I deploy these systems. I have sold them, debugged them, and sat in the meeting where one of them cost real money. The argument here is that doubt, designed well, is what makes AI products trustworthy enough to deploy at all.
The thesis
The dangerous AI failure is not merely being wrong. It is being wrong in a form that makes humans stop checking.
Everything in this book follows from that sentence. If the worst failures are the ones that suppress human verification, then the design target is not only accuracy. It is the relationship between how confident an answer appears and how reliable it actually is. When those two things track each other, the human checks exactly when they should. When appearance outruns reliability, you have manufactured overtrust, and overtrust is a liability that compounds silently until the day a rare, expensive error lands and nobody catches it.
The decision researchers Raja Parasuraman and Victor Riley gave us the vocabulary for this decades before language models existed. In their foundational 1997 paper Humans and Automation: Use, Misuse, Disuse, Abuse, they describe misuse as overreliance on automation that leads to failures of monitoring, and they trace it to a mismatch between how much an operator trusts a system and how much the system deserves. The aviation and medical automation literatures have spent thirty years documenting that mismatch. Generative AI did not invent the problem. It industrialized it, gave it a fluent voice, and shipped it to every knowledge worker at once.
The promise
This book teaches teams how to design uncertainty, abstention, evidence, escalation, and calibrated doubt into AI products. Concretely, by the end you should be able to do the following.
You will be able to separate four things that get collapsed in casual conversation: accuracy, confidence, calibration, and authority. Most product failures I have seen come from treating these as one quantity.
You will be able to map any AI feature onto a Confidence-Cost Matrix, plotting how confident the system appears against how expensive its errors are, and use that map to decide where calibrated doubt is mandatory rather than nice to have.
You will have a set of repeatable patterns. The DOUBT pattern for the answer pipeline: Detect uncertainty, Offer boundaries, Use evidence, Branch safely, Trigger escalation. The Calibrated Answer Contract for specifying what a good answer must carry: source, scope, freshness, confidence behavior, actionability, escalation rule. And the Doubt UX Ladder for choosing how strongly to express uncertainty, from a subtle cue all the way to human escalation.
You will be able to measure calibration with reliability diagrams and proper scoring rules, and read those measurements without fooling yourself.
And you will be able to tell the difference between human review that reduces risk and human review that is theater, a checkbox that launders machine output into human accountability without anyone actually checking anything.
How to read this book
The chapters are sequenced but not rigidly dependent. The first three build the conceptual core: why fluency reads as competence, the four-way distinction between accuracy and confidence and calibration and authority, and the matrix that tells you where doubt is worth paying for. The middle chapters are about design and interface: why showing sources is not enough, how to build calibrated answers, how to make doubt a feature rather than an apology, and how abstention and escalation actually work. The later chapters are about measurement, the false comfort of review, the structure of wrong-answer incidents, and the economics that decide whether any of this gets funded.
Each chapter carries its own research spine. I do not recycle the same citations across chapters, because the argument in a UX chapter should be shaped by human-factors research, and the argument in a measurement chapter should be shaped by the calibration literature, and pretending one source list covers both is how books get decorative instead of useful.
The frameworks recur on purpose. The Confidence-Cost Matrix, the DOUBT pattern, the Calibrated Answer Contract, and the Doubt UX Ladder show up again and again in different contexts, because a framework you define once and abandon is just jargon. A framework you use to make ten different decisions is a tool.
A note on the procurement story
I opened with the contract because it is unglamorous, and unglamorous is where the money is. The dramatic AI failures get the headlines: the lawyers who filed a brief full of cases that did not exist, the airline ordered to honor a refund its chatbot invented. We will examine both, carefully, with sources. But the bulk of the cost of being confidently wrong is not dramatic. It is a thousand small forwarded answers that nobody checked, each one a little decision to trust the formatting over the evidence.
The fix is not to make the AI sound less helpful. It is to make the AI sound exactly as confident as it deserves to sound, and to design the surrounding product so that doubt, when it is warranted, is visible, actionable, and routed to the right place. That is the whole project. Doubt is not a weakness in an AI product. Designed correctly, doubt is the interface through which an honest system tells the truth about what it does not know. Let us build it. Why Fluency Feels Like Competence is where that project begins.
Key Takeaways
- The dangerous failure is being wrong in a form that stops humans from checking, not being wrong as such.
- The enemy is fluent interfaces that flatten internal uncertainty into uniform confidence and make wrong answers feel finished.
- Accuracy without calibration can worsen overtrust, because long streaks of correct answers train people to stop verifying.
- The overtrust problem predates language models; Parasuraman and Riley named it misuse of automation in 1997.
- This book delivers four reusable tools: the Confidence-Cost Matrix, the DOUBT pattern, the Calibrated Answer Contract, and the Doubt UX Ladder.
- Doubt, designed well, is not a weakness. It is the interface through which an honest system tells the truth about what it does not know.