A Working Taxonomy of Memory
> **Working claim:** "Memory" is not one thing, and the word's vagueness is itself a source of bugs. A production system has at least ten distinct kinds of state, each with a different lifetime, owner, trust level, and governance requirement.

A taxonomy of memory separates short-term context, conversation history, summaries, episodic memory, semantic memory, profile memory, procedural memory, application state, external knowledge, and audit state before one vague word becomes ten production bugs.
Working claim: "Memory" is not one thing, and the word's vagueness is itself a source of bugs. A production system has at least ten distinct kinds of state, each with a different lifetime, owner, trust level, and governance requirement. You cannot design memory until you have named its parts, because the parts have nothing in common except the careless label.
Key Takeaways
- Memory is not one store; a production AI system carries at least ten kinds of state with different lifetimes and owners.
- Application state, audit logs, user profile facts, and recalled evidence need separate schemas because they fail in different ways.
- The safest default is to name the memory type before choosing vector search, a database row, a summary, or a log.
The word that hides ten things
When a product manager says "the assistant should remember the customer, " they are, without realizing it, specifying ten different systems. They mean it should keep the conversation coherent within the session (short-term context). They mean it should recall what was said earlier in the chat (conversation history). They mean it should know the customer's standing preferences (profile memory). They mean it should know what happened in past sessions (episodic memory). They mean it should know durable facts the customer told it (semantic memory). They mean it should remember how to perform the customer's recurring workflow (procedural memory). They mean the open ticket should still be open (application state). They mean it should be able to look things up in the docs (external knowledge). And, though they will not say this until the auditor asks, they mean all of it should be logged (audit state) and none of it should leak to another customer or persist after a deletion request (governance).
Treating these as one thing called "memory" is the root cause of an entire class of failures. The team builds "memory" as a single vector store of past conversation snippets, and then discovers it cannot answer "what is the customer's current plan tier?" (that is structured application state, not a fuzzy snippet), cannot honor "forget what I told you last week" (no per-fact identity or deletion path), cannot prevent yesterday's resolved complaint from resurfacing as if current (no episodic-vs-semantic distinction, no expiry), and cannot explain why it said something (no provenance, no audit). One bucket, ten requirements, predictable collapse.
So before any code, the work is taxonomic. This chapter names the ten kinds, gives each its defining properties, and draws the lines between them. The next two chapters build the gates that write and read them.
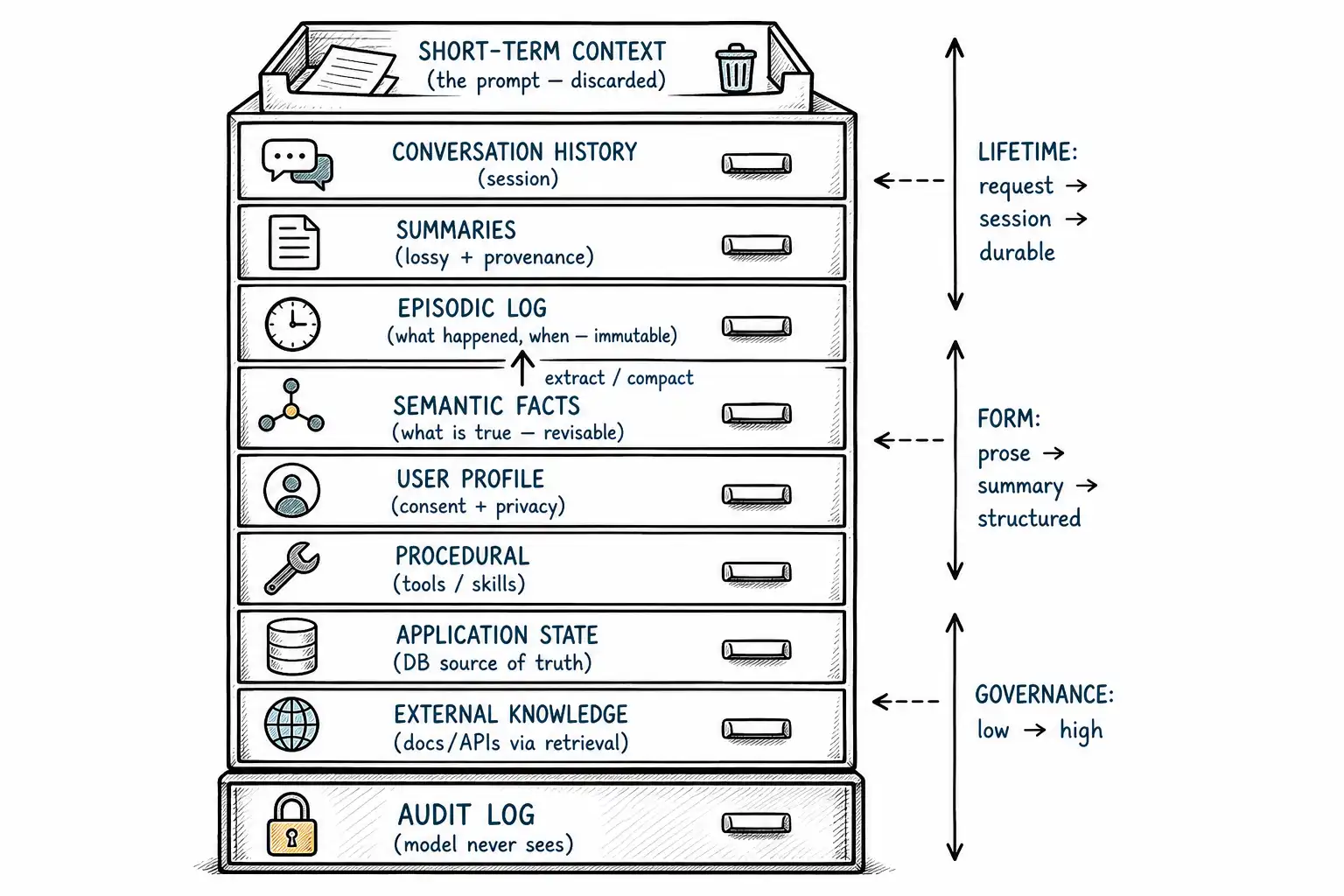
The ten kinds, and the three questions that separate them
Every kind of memory can be placed by answering three questions:
- Lifetime, how long does it live? One forward pass, one session, or across sessions indefinitely (until expired or deleted)?
- Form: is it transient prose, a structured record, a compressed summary, or an external resource?
- Governance, who owns it, who may see it, does it require consent, can it be deleted, and is the model allowed to see it at all?
Run the ten kinds through those questions:
| Kind | Lifetime | Form | Model sees it? | Governance weight |
|---|---|---|---|---|
| Short-term context | One request | The assembled prompt | Yes (it is the prompt) | Low, discarded immediately |
| Conversation history | One session (typically) | Turn records / transcript | Selectively, summarized | Medium, may contain PII |
| Summaries | Spans sessions | Lossy compressed text | Yes, when recalled | Medium, provenance risk |
| Episodic memory | Across sessions | Event records ("on X, Y happened") | Selectively, on recall | Medium-high, dated facts |
| Semantic memory | Across sessions, until revised | Durable extracted facts/claims | Selectively, on recall | High, drives behavior |
| User-profile memory | Long-lived | Preferences, attributes | Selectively | High, consent + privacy |
| Procedural memory | Long-lived | Tools, skills, routines, workflows | As capability, not text | Medium, correctness risk |
| Application state | As long as the entity | Structured DB rows (cart, case, ticket) | As read data | High, source of truth |
| External knowledge | Independent of the user | Documents, DBs, APIs | Via retrieval | Varies, permissioning |
| Audit state | Retention-policy bound | Append-only logs | No | Highest, compliance |
The table is the chapter in miniature. Notice that "the model sees it" is almost never an unqualified yes for anything durable, durable state is selectively recalled into the prompt, not permanently resident, which is the architectural expression of the desk/archive split. And notice that audit state is the one kind the model must never see: it exists for humans and compliance, and exposing it to the model is both a privacy hazard and a pollution source.
Walking the kinds, with the distinctions that matter
A few of these boundaries are where teams most often blur things, so they deserve prose.
Short-term context vs. conversation history. Short-term context is the prompt for this request. Conversation history is the record of prior turns, which may feed the prompt but is not the prompt. The distinction matters because history grows without bound while the prompt has a budget, so history must be selected from and summarized, never replayed whole (the anti-pattern from Chapter 3). History is archive; the slice you replay is desk.
Conversation history vs. episodic memory. History is verbatim turns within a session. Episodic memory is durable event records that outlive the session: "on 2026-03-04 the customer reported error E-22 and we issued a credit." Episodic memory is dated and specific; it is the system's diary. It is the substrate from which semantic memory is extracted.
Episodic vs. semantic memory. This is the most important distinction in the chapter, borrowed (carefully) from cognitive psychology and used heavily by Generative Agents and MemoryBank. Episodic memory is "what happened, when", events, tied to time. Semantic memory is "what is true", durable facts abstracted from events, no longer tied to a single occurrence."The customer emailed angrily on Tuesday" is episodic."The customer prefers email over phone" is semantic, perhaps inferred from several episodes. The reason to separate them: episodes are immutable historical records you should never edit (they happened), while semantic facts are revisable beliefs that can be confirmed, contradicted, updated, or expired. Storing a revisable belief as if it were an immutable event, or vice versa, breaks both correction and audit. Chapter 9's write gate enforces the split.
Semantic memory vs. user-profile memory. Profile memory is a specialized, high-value slice of semantic memory: stable attributes and preferences about a person (name, role, language, communication preferences, accessibility needs). It is broken out because it carries the heaviest consent and privacy obligations and is queried on almost every request, so it deserves its own store and its own access rules.
Procedural memory. This is the odd one: it is not facts but capabilities, tools, skills, learned routines, workflows the agent can execute. Voyager is the canonical demonstration, building a growing library of reusable skills an agent writes, stores, and recalls to solve new tasks; Reflexion is adjacent, storing verbal self-feedback that improves future attempts. Procedural memory enters the prompt not as recalled prose but as available tools or as retrieved routines, and its risk is correctness (a wrong learned routine misfires repeatedly) rather than privacy.
Application state. The one teams most often try to cram into "memory" and most often should not. A shopping cart, an open case, a ticket's status, a workflow's current step, these are structured source-of-truth data that belong in a database with transactions and constraints, read into the prompt as structured facts, never narrated into fuzzy prose the model must parse and re-parse. Modeling "the order is paid but not shipped" as a memory snippet rather than two boolean columns is how agents end up confidently wrong about state that the database knew exactly.
External knowledge. Documents, databases, and APIs that exist independently of the user and are reached via retrieval (the subject of the Embeddings, Honestly book in this series). Distinct from memory because it is shared, not personal, and governed by document-level permissions rather than per-user consent.
Audit state. Append-only logs of what the system did and why: which memories were written, which were recalled, what the model was shown, what it decided. The model never sees it. It exists so a human can reconstruct an incident, satisfy a regulator, and prove a deletion happened. Building it later is far harder than building it from the start, because you cannot reconstruct logs you never wrote.
The OS and database analogies, used honestly
MemGPT framed an LLM as something like an operating system managing a memory hierarchy: a small fast "main context" (the window) and larger "external context" (stores), with the system paging information in and out as needed, virtual memory for prompts. The analogy is genuinely useful and recurs through Movement IV: the window is RAM, the stores are disk, and the context assembler is the pager deciding what to fault in for this request.
But the analogies must be used honestly, with their limits stated, or they overclaim:
- Virtual memory pages exact bytes in and out losslessly. LLM "paging" summarizes and selects lossily, and what gets faulted in is chosen by imperfect relevance, not by a clean address. A summary is not a page; it is a compression with provenance risk.
- Caching assumes the cached value is still valid. A recalled memory may be stale (the currency rung), the cache-invalidation problem is harder for facts about a changing world than for deterministic computations.
- Database normalization gives you one authoritative copy of each fact. Memory systems accumulate multiple, possibly contradictory claims from different events and need explicit conflict resolution (Chapter 12), not a unique key.
- Event sourcing / log compaction maps beautifully onto episodic→semantic: episodes are the immutable event log, semantic facts are the compacted materialized view. This analogy is strong and we lean on it. But unlike a database projection, the compaction step is a fallible model extraction, so it needs a gate and a confidence score.
Use the metaphors as scaffolding for design and as a source of proven patterns (paging, compaction, invalidation). Do not use them to claim an LLM's memory is a computer's memory. It is lossier, less trustworthy, and governed by consent and privacy law in ways a page table never was.
Why the taxonomy is the prerequisite for everything that follows
It would be possible to skip this chapter and go straight to "here is a memory schema." That is exactly the mistake the one-bucket teams make. Without the taxonomy, the schema is wrong, because a single schema cannot serve an immutable dated episode and a revisable durable fact and a structured ticket and an append-only audit row, they have different lifetimes, different mutability, different governance, and different visibility to the model. The taxonomy tells you that you need several stores with several schemas and several gates, related by defined flows (episodes compact into semantic facts; semantic facts feed profile; everything writes an audit row).
The next chapter takes the highest-stakes, most error-prone flow, turning something stated in a conversation into a durable semantic fact, and builds the write gate that governs it: the three questions "is it true, should it persist, is it allowed, " made into schema and code. The chapter after that builds the read side: how to recall the right memories under recency, relevance, and policy filters without dragging in stale or unauthorized state. With the taxonomy in hand, both gates have a clear job, because we now know exactly what kind of thing is passing through them.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
"Memory" hides at least ten distinct kinds of state: short-term context, conversation history, summaries, episodic memory, semantic memory, user-profile memory, procedural memory, application state, external knowledge, and audit state. They share nothing but the label, each differs in lifetime (request / session / durable), form (prose / summary / structured / external), and governance (ownership, consent, deletability, and whether the model may see it at all). The critical distinctions: short-term context is the prompt while history is the replayable record; episodic memory is immutable dated events while semantic memory is revisable durable facts extracted from them; profile memory is the consent-heavy slice of semantic memory about a person; procedural memory is capabilities not facts; application state is structured source-of-truth data that does not belong in fuzzy memory; and audit state is the one kind the model must never see. OS and database analogies (virtual memory, caching, normalization, event sourcing/log compaction) are useful scaffolding, episodic→semantic maps cleanly onto event-log→compacted-view, but must be used honestly, because LLM memory is lossier, staler, and governed by consent in ways a page table is not. Naming the parts is the prerequisite for the write and read gates built next; the one-bucket "memory" store collapses precisely because ten requirements were forced into one design. The Memory Write Gate builds exactly that gate, the three-question filter that decides what enters the store at all.