Operating Memory in Production
> **Working claim:** A memory system is not shipped when it works; it is shipped when it is *observable, governed, and recoverable*, when you can see what it remembers, prove you can delete it, and respond to the incident where it acts on a false belief.

Memory in production is an operating system problem: every write, read, expiry, correction, deletion, and audit event needs ownership before the model can safely personalize behavior.
Working claim: A memory system is not shipped when it works; it is shipped when it is observable, governed, and recoverable, when you can see what it remembers, prove you can delete it, and respond to the incident where it acts on a false belief. The last mile of "long context is not memory" is operational: the archive needs the same monitoring, runbooks, and retention policy as any other production datastore, because that is exactly what it is.
Key Takeaways
- Production memory needs runbooks, dashboards, deletion paths, and ownership, not only a vector store of remembered snippets.
- The hard work is lifecycle control: write, verify, recall, supersede, expire, revoke, and audit.
- A memory system that cannot explain why a fact was recalled is already too opaque for high-stakes workflows.
The production architecture, end to end
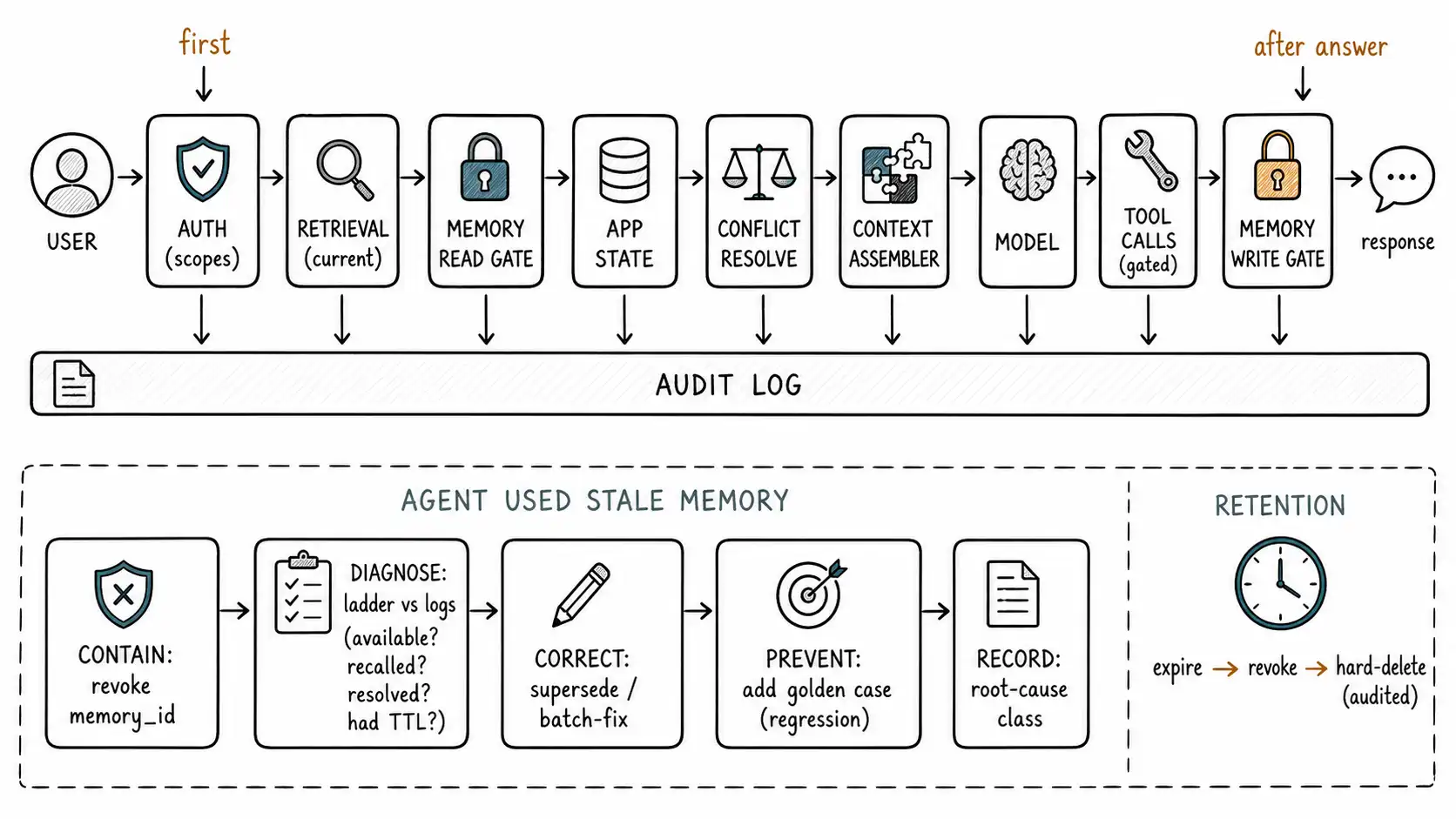
Before monitoring, fix the shape of the running system, because you can only monitor what is wired explicitly. Every request flows through the same governed pipeline, and the order is the security and correctness order, not a convenience:
user request
-> AUTH resolve identity + permitted scopes (before anything reads)
-> RETRIEVAL current+permitted documents (currency filter, Ch.12)
-> MEMORY READ GATE policy-filtered, ranked, budgeted recall (Ch.10)
-> APP STATE LOAD structured source-of-truth (Ch.8)
-> CONFLICT RESOLUTION single attributed values, losers flagged (Ch.12)
-> CONTEXT ASSEMBLER budget, priority, order-for-attention+cache (Ch.11)
-> MODEL one forward pass over the assembled desk
-> TOOL CALLS gated; untrusted text never reaches a privileged action
-> MEMORY WRITE GATE candidate facts -> three gates -> durable memory (Ch.9)
-> LOGS / AUDIT every read, write, drop, conflict, cache outcome
-> responseTwo placements are non-negotiable. Auth is first, so permission scopes the entire request; nothing is retrieved or recalled that the requester cannot see. And the memory write gate is after the response, operating on the completed turn, so persistence is a deliberate post-hoc decision, never a side effect of generation. Everything between is the machinery of the preceding chapters, now arranged as one observable flow. The audit log is not a step; it is written at every step, which is what makes the next sections possible.
The monitoring schema
You cannot operate what you do not measure, and the metrics for this system are specific. A per-request monitoring record should capture enough to diagnose any rung of the Chapter 2 ladder and to track the operational currencies of Chapter 7:
CREATE TABLE request_telemetry (
request_id TEXT PRIMARY KEY,
user_id TEXT,
ts TIMESTAMPTZ NOT NULL,
-- Context composition (the desk, by source)
context_tokens_total INT,
retrieved_tokens INT,
memory_tokens INT,
summary_tokens INT,
app_state_tokens INT,
blocks_dropped TEXT[], -- which priority blocks the allocator cut
-- Memory behavior
memories_recalled INT,
memories_written INT,
memory_write_rejections INT, -- candidates the gate refused
conflicts_detected INT, -- resolve_conflict fired
-- Grounding / trust
answer_citations INT, -- claims mapped to a source
uncited_claim_flag BOOLEAN, -- model asserted something unsupported
abstained BOOLEAN,
-- Operational currencies (Ch.7)
cache_hit_tokens INT, -- prefix cache hits
cache_miss_tokens INT,
model_latency_ms INT,
ttft_ms INT,
model_cost_usd NUMERIC(10,5)
);From this one table fall the dashboards that matter:
- Stale-memory rate: derived by joining
conflicts_detected(where a memory lost to live data) over total recalls. A rising rate is the early warning that memory is drifting from reality, before it produces a visible incident. - Memory write/reject ratio: a sudden spike in writes (or a collapse in rejections) signals the write gate has been weakened or an extraction change is over-extracting. A spike in rejections may signal a poisoning attempt (Chapter 13).
- Cache hit rate:
cache_hit_tokens / (hit + miss). A falling hit rate means something is leaking variable content into the cacheable prefix (Chapter 11) or the prefix is changing; it directly raises cost and latency, so it is a money metric, not just a curiosity (see the Anthropic prompt caching documentation for the mechanics of measuring and maintaining the cache boundary). - Uncited-claim rate and abstention rate: interpreted together, per Chapter 2's trust rung: a low abstention rate with a rising uncited-claim rate means the system is getting more confident and less grounded, the opposite of what you want.
- Cost and latency per successful task: the honest denominators from Chapter 7, with
blocks_droppedavailable to explain a quality dip ("relevant evidence was budgeted out on these requests").
Metrics are interpreted together, never alone. A low stale-memory rate is not automatically good, it may mean the system rarely consults memory at all. A high cache hit rate is not automatically good, it may mean prompts are over-static and not personalizing. The unit of health is the safe, grounded, current, successful task, not any single counter.
The incident you will have: stale memory
Every memory system eventually acts on a belief that was true once and is not now. Because this incident is predictable, the runbook should be written before it happens, not during. A worked runbook:
INCIDENT: Agent acted on stale memory
Trigger: User reports the assistant used outdated info; or stale-memory-rate alert fires.
1. CONTAIN
- Identify the offending memory_id from recall logs for the request_id.
- REVOKE it immediately (revoked_at = now): stops all recall instantly.
- If the fact drove an action (a tool call), assess and reverse the action.
2. DIAGNOSE (use the Chapter 2 ladder against the logs)
- Was the current truth available? (retrieval/app-state logs)
- If available, was it recalled/retrieved? -> ranking or currency-filter miss
- If recalled, was the conflict resolved? -> conflict hierarchy gap
- Was the stale memory missing an expires_at? -> write-gate TTL gap
- Did it lose to a louder distractor? -> positioning / pollution
3. CORRECT
- Supersede the stale memory with the current value (preserve chain).
- If a class of memories shares the defect (no TTL), batch-fix the class.
4. PREVENT (the regression rule, Ch.13)
- Add a stateful golden case reproducing this exact staleness; it must pass.
- If currency-filter gap: tighten retrieval supersession.
- If TTL gap: set category expiry so this fact type self-expires.
- If conflict gap: add the source pair to the precedence table.
5. RECORD
- Write an incident entry with root cause class and the prevention added.The shape mirrors the embeddings book's incident discipline but the root-cause classes are memory-specific: currency-filter miss, ranking miss, conflict-hierarchy gap, missing-TTL, positioning/pollution. Classifying the root cause is what stops fashionable non-fixes, swapping the model does not repair a missing expires_at, and a bigger window does not repair a conflict-hierarchy gap. The fix matches the class or it is theater.
Human review for high-risk writes
Chapter 9's write gate can queue for review rather than auto-commit, and production is where you decide which categories trigger that. The principle, consistent with the NIST AI RMF risk posture: the review requirement scales with the blast radius of a wrong memory. A wrong UI-color preference is harmless; a wrong stored medical allergy, financial authorization, or access grant is dangerous and persistent. So:
- Auto-commit low-stakes, easily-reversible, low-confidence-tolerant categories (cosmetic preferences, topic interests).
- Queue for human review high-stakes categories (commitments with financial or legal weight, safety-relevant facts, anything that grants access or authorizes action) before they become durable.
- Never auto-write categories that policy or law prohibits storing at all (certain special-category personal data), the gate rejects, it does not queue.
The reviewer is not checking grammar; they are confirming the three gates' verdict on something the system judged risky. This is the memory analogue of the review queue that the embeddings book argued is a pressure valve, not a weakness: it lets the system be useful while admitting that some persistence decisions are too consequential to make probabilistically.
Retention and deletion as a standing policy
The write gate gave every memory an expires_at and a revoked_at; production turns those fields into a standing, automated policy, not a manual scramble when a request arrives. The components:
- Scheduled expiry sweep. A job that revokes memories past
expires_atand hard-deletes revoked memories past their retention window, on a schedule, with each action audited. Memory that nobody re-confirms should age out automatically, the decay of Chapter 10 made it rank low; expiry removes it entirely. - On-demand erasure. An erasure request (a GDPR Article 17 right, or simple user request) must be honored end to end: revoke immediately (recall stops at once), hard-delete on the policy schedule, and record in the audit log that erasure occurred and what scope it covered. The deletion path must be tested (Chapter 13's deletion test) and fast, because "we are working on being able to delete it" is not a defensible answer.
- Retention limits by category. Different memory categories have different lawful and sensible retention periods. Encode them; do not keep everything forever by default. The default for a fact with no business reason to persist is a short life, not an unbounded one.
def expiry_sweep(store, now, retention_by_category):
for m in store.iter_active():
if m.expires_at and m.expires_at <= now:
store.revoke(m.memory_id, reason="expired", at=now) # stops recall
for m in store.iter_revoked():
window = retention_by_category.get(m.category, DEFAULT_RETENTION)
if m.revoked_at and (now - m.revoked_at) > window:
store.hard_delete(m.memory_id)
audit.record("hard_delete", memory_id=m.memory_id, at=now) # the act, not the dataThe broader architecture this chapter describes, a governed memory pipeline with explicit write/read gates, follows the design patterns proposed by Generative Agents and formalized operationally by MemGPT, now extended with the retention, compliance, and monitoring layer that production requires. The reason this is a standing policy rather than a feature is that retention obligations are continuous and auditable. A regulator does not ask "can you delete data?" once; they ask "show me that expired and erased data is actually gone, on a schedule, with records." A memory system that cannot demonstrate that is a liability regardless of how well it answers questions.
The book, closed
This chapter ends the argument by grounding it. A memory system in production is a datastore: it has a pipeline with auth at the front and a write gate at the back, telemetry on every request, dashboards whose unit of health is the successful grounded task, a runbook for its predictable failure, a human-review queue sized to blast radius, and a standing retention-and-deletion policy you can prove to an auditor. None of that is provided by a context window of any size. The window holds the desk for one forward pass; everything in this chapter is the room around the desk: the locks, the labels, the logs, the cleaning schedule, the recovery plan.
Which returns us, last, to the sentence the book opened with. The policy team's assistant gave a confidently wrong answer because the system mistook a desk for an archive: it put the current truth and the obsolete truth on the same surface, under a small lamp, with no gate to decide which was current, no provenance to trace the error, no monitoring to catch the drift, and no memory of the correction once a human noticed. Every one of those gaps has now been named, designed, coded, and measured. The window is not the problem and never was; the absence of the room around it is. Build the room. The desk will do its job, holding what you deliberately place on it, for exactly as long as the work takes, and not one request longer.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
A memory system ships when it is observable, governed, and recoverable, because it is a production datastore, not a model feature. The production architecture is a single governed pipeline with auth first (scoping the whole request) and the memory write gate after the response (persistence as a deliberate post-hoc decision), with the audit log written at every step. The monitoring schema captures context composition by source, memory read/write/reject counts, conflicts, grounding (citations, uncited-claim and abstention flags), and the operational currencies (cache hit rate, latency, cost), yielding the dashboards that matter, above all the stale-memory rate, the early warning of drift, all interpreted together against the unit of health: the safe, grounded, successful task. The predictable incident (agent acted on stale memory) gets a pre-written runbook: contain by revoking, diagnose by running the Chapter 2 ladder against the logs, correct by supersession, prevent via the regression rule, and record a memory-specific root-cause class so the fix matches the cause instead of swapping the model.Human review is required for write categories whose blast radius is large, prohibited entirely for unlawful categories, and skipped for harmless ones.Retention and deletion are a standing automated policy, scheduled expiry sweeps, on-demand erasure honored end to end and fast, and per-category retention limits, provable to an auditor. The room around the desk, locks, labels, logs, recovery, is the memory system; the window of any size is not.
Appendix A: Back Matter closes the book with the full glossary, implementation checklist, and source register, the reference artifact to keep beside the production system this chapter just grounded.