Why Passing Needle-in-a-Haystack Is Not Enough
> **Working claim:** The most-cited long-context benchmark, find one planted sentence in a huge document, measures the easiest thing a long context can do and predicts almost nothing about the hard things.

Needle-in-a-haystack tests prove that a model can recover one planted fact from a long prompt; they do not prove that the system can use messy, conflicting, permissioned evidence in production.
Working claim: The most-cited long-context benchmark, find one planted sentence in a huge document, measures the easiest thing a long context can do and predicts almost nothing about the hard things. A model can score a perfect needle retrieval and still fail at multi-hop reasoning, aggregation, and holding constraints across distance. Buy the window on the marketing number and you will be surprised in production.
Key Takeaways
- A needle test is a useful smoke test, not a production memory or context evaluation strategy.
- Real systems need tests for conflict, source authority, staleness, permissions, distractors, summarization loss, and downstream decisions.
- If the eval does not resemble the failure you fear, a passing score is mostly theater.
The test everyone runs and what it actually proves
The "needle in a haystack" test is irresistible because it produces a clean, viral picture: plant a single odd sentence ("the secret code is 7492") somewhere in a 200, 000-token document of unrelated text, ask the model to recall it, and chart success across depths and lengths. A wall of green squares looks like proof that the model "uses its whole context." Vendors publish these charts. Teams screenshot them into decision documents. And then they ship.
What the test actually proves is narrow: the model can locate and copy one verbatim, lexically distinctive span from a long input. That is a real capability and a meaningful one, it is rung two of the Chapter 2 ladder (attended to) measured under stress. But it is the floor of long-context competence, not the ceiling, for three reasons that compound:
- The needle is lexically distinctive. "The secret code is 7492" shares no vocabulary with the surrounding filler, so attention has an easy target. Real evidence is topically embedded in similar-sounding text, the relevant clause looks like the irrelevant clauses around it, which is the hard case (the distractor problem from Chapter 2).
- One needle is not many needles. Real tasks need several facts found and combined. Finding fact A and fact B and computing their relationship is categorically harder than finding either alone, and needle tests with a single needle never probe it. This was the central finding of Lost in the Middle, even locating a single-fact answer degrades predictably with position, before we add the harder requirement of combining several.
- Retrieval is not reasoning. Copying a span is not the same as using it under a constraint, aggregating it with others, or following it through a multi-step inference. A model can ace copy and fail compute.
The RULER benchmark was built precisely to expose this gap, and its central finding deserves to be on the wall of every team buying a long-context model.
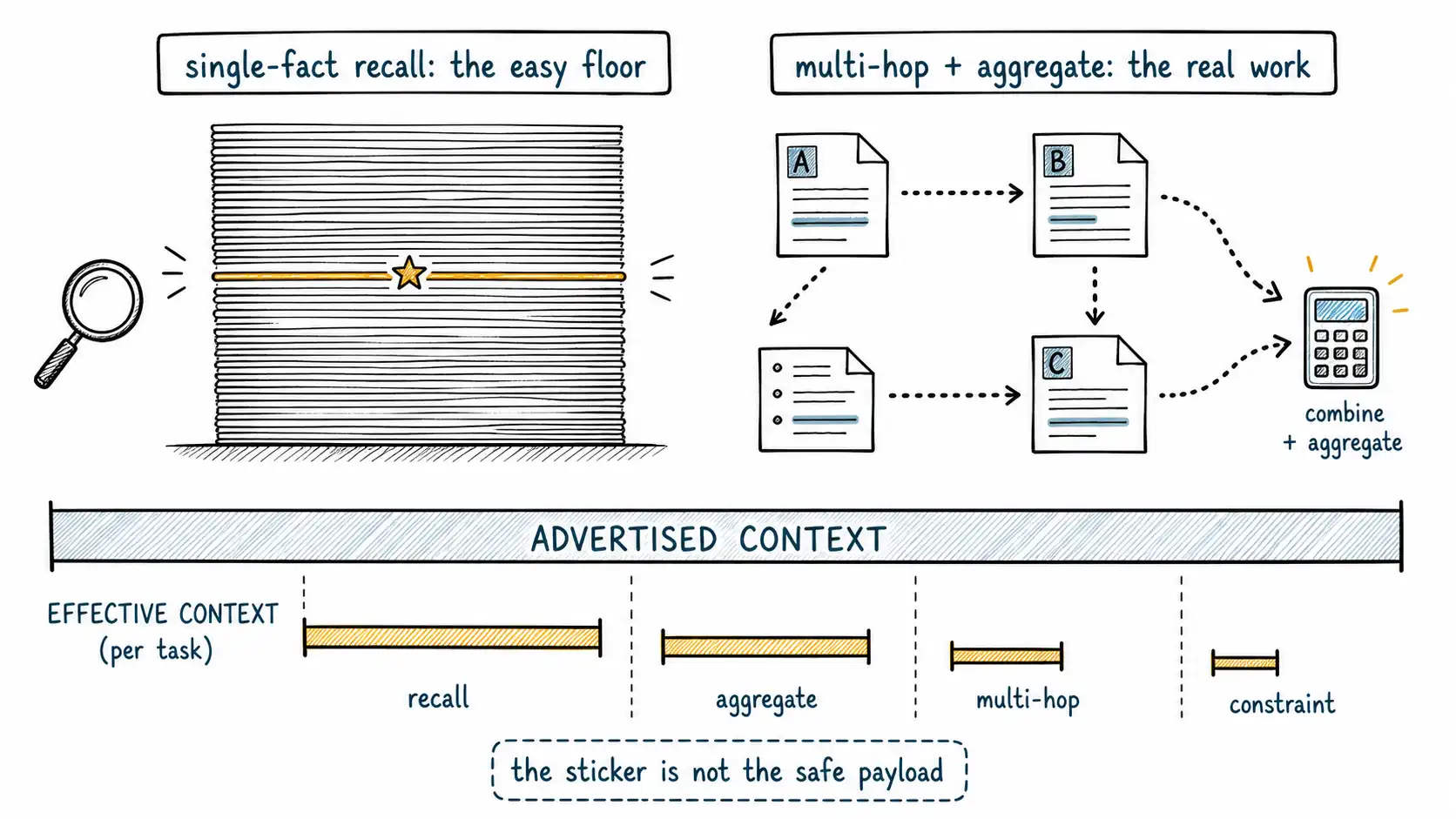
RULER: the "real" context size is shorter than the sticker
RULER extends the needle idea into a battery of tasks of increasing difficulty: multiple needles, needles you must aggregate, needles among hard distractors, variable tracking (follow a value as it is reassigned through the text), and question answering that requires combining scattered information. The headline result is blunt: models that claim very large context windows maintain acceptable performance only up to a length far shorter than their advertised maximum, and the more demanding the task, the shorter that effective length becomes.
In other words, there are two numbers. The advertised context is the physical token bound. The effective context is the length at which the model still performs the task you actually have above some quality threshold, and for anything past simple recall, the effective number is routinely a fraction of the advertised one. A model sold at "1M tokens" might hold multi-hop QA reliably only across a much smaller span. The sticker measures the cargo volume; RULER measures the safe payload.
This single distinction reframes every long-context architecture decision."It fits in the window" (Chapter 1's discredited success criterion) is doubly wrong: not only does fitting not guarantee the model attends and selects, it does not even guarantee you are inside the effective context for your task. The right question is empirical and task-specific: at the context length I actually use, for the task I actually have, what is my measured quality?
What real-world long-context benchmarks add
Needle and RULER are synthetic, controlled, diagnostic, and a little artificial. LongBench and its successor LongBench v2 come at the problem from the other side, with realistic long-context tasks: multi-document QA, long-document summarization, code repository understanding, long in-context learning, and more, across multiple languages. ∞Bench pushes evaluation past the 100k-token mark with similarly realistic tasks.
The value of these for a builder is that they sample the kinds of work you actually deploy, synthesis, summarization, code understanding, rather than a planted-sentence game. And they reinforce RULER's lesson from the realistic side: scores on genuine multi-step long-context tasks fall well short of what the needle charts imply, and they degrade with length. LongBench v2 in particular emphasizes tasks demanding deep reasoning and long-range dependency, exactly the regime where a clean needle score is most misleading.
The practical takeaway is not "use LongBench as your metric", public benchmarks are for comparing models, not for validating your system. It is that the shape of these benchmarks should shape your own evals: include multi-hop, aggregation, and constraint-holding tasks, not just recall.
A taxonomy of long-context tasks, easiest to hardest
To pick the right eval and set the right expectation, it helps to name the difficulty ladder explicitly. Each step demands strictly more than the one below it, and the effective context length shrinks as you climb.
| Task type | What it requires | Needle test covers it? | Effective context vs. advertised |
|---|---|---|---|
| Single-fact recall | Find and copy one distinctive span | Yes (this is the needle) | Closest to advertised |
| Embedded recall | Find one span among topically similar text | Barely | Shorter |
| Multi-needle retrieval | Find several relevant spans | No | Shorter |
| Aggregation | Combine/count/compare several spans | No | Much shorter |
| Multi-hop reasoning | Chain inferences across spans (A→B→C) | No | Much shorter |
| Constraint-holding | Apply a rule stated early to content stated late | No | Much shorter |
| Variable tracking | Follow a value through reassignments | No | Among the shortest |
The column that matters is the last one. As tasks climb the ladder, the length over which the model stays reliable collapses. A system designed for single-fact recall at 500k tokens may be operating far outside its effective context if the real task is multi-hop reasoning. The needle chart told you about row one. Your product probably lives in rows four through seven.
Building evals that probe the hard rungs
Since public benchmarks compare models rather than validate your system, you need task-shaped evals over your data at your lengths. The construction mirrors Chapter 5's positional sweep but varies task difficulty and length together. A compact harness:
from dataclasses import dataclass
@dataclass
class LongContextCase:
question: str
gold: str
task_type: str # "recall" | "aggregate" | "multihop" | "constraint"
context_tokens: int # length the case was rendered at
def build_cases(corpus, lengths=(8_000, 32_000, 128_000)):
cases = []
for n in lengths:
ctx = pad_to_length(corpus, n) # real filler, not lorem
cases += [
make_recall_case(ctx, n), # row 1
make_multineedle_case(ctx, n), # row 3
make_aggregation_case(ctx, n), # row 4: "how many X mention Y?"
make_multihop_case(ctx, n), # row 5: A->B->C across docs
make_constraint_case(ctx, n), # row 6: rule early, apply late
]
return cases
def effective_context(results, threshold=0.85):
"""Largest length at which each task type stays above the quality bar."""
out = {}
for task in {r.task_type for r in results}:
rows = sorted((r for r in results if r.task_type == task),
key=lambda r: r.context_tokens)
ok = [r.context_tokens for r in rows if r.score >= threshold]
out[task] = max(ok) if ok else 0
return out # e.g. {"recall": 128000, "multihop": 32000, "constraint": 8000}The output, an effective context length per task type, is the number you should put in your architecture decision, not the vendor's sticker. If multihop holds only to 32k but your prompts routinely run to 200k of retrieved context, you have found, before your users did, that the system is operating outside its reliable range and needs decomposition (break the multi-hop task into smaller steps), better retrieval (bring the relevant spans close together and short), or both.
Why this matters for the memory argument
This chapter is the empirical heart of Movement II's contribution to the book's thesis. The mirage says: the window is big, so dump everything in and let the model figure it out. RULER and LongBench answer: even for reading and reasoning within a single request, the model's reliable capacity is much smaller than the window, and it shrinks fast as the task gets harder than copying a sentence. So even on the rungs below the single-request/across-request line (Chapter 2), "bigger window" does not deliver "uses everything well."
That demolishes the strongest version of the mirage before we even get to memory. If long context were perfectly reliable across its full advertised length for arbitrary tasks, one could at least argue that within a session, stuffing the window is fine and only cross-session persistence needs a separate system. But it is not reliable across its full length even within a session. The effective context is short, harder tasks make it shorter, and irrelevant content (next chapter) makes it shorter still. Curation, retrieval, ordering, and decomposition are necessary within a request, before we ever ask the separate question of what should persist across requests. The window is a constrained, expensive, task-sensitive working set on every axis, which is exactly why the durable, governed archive of Movement III is not optional.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
The needle-in-a-haystack test measures the easiest long-context task, locating one lexically distinctive, planted span, and a perfect score on it predicts almost nothing about the hard tasks a product actually performs. RULER shows that a model's effective context (the length at which it still performs a given task above threshold) is far shorter than its advertised context, and shrinks as tasks climb a difficulty ladder from recall to embedded recall, multi-needle retrieval, aggregation, multi-hop reasoning, constraint-holding, and variable tracking. LongBench, LongBench v2, and ∞Bench confirm the same gap on realistic tasks. The builder's move is to measure effective context length per task type over your own data at your own lengths, and to put that number, not the vendor sticker, into architecture decisions, reaching for decomposition and better retrieval when the task exceeds the reliable range (the Google Gemini long-context documentation provides practical task-categorization guidance for deciding when its extended window helps versus when retrieval should own the work). This result demolishes the strongest form of the mirage: long context is a constrained, task-sensitive working set even within a single request, which is precisely why curation and retrieval are necessary before the prompt, and why a separate durable archive is necessary across requests.
The Operational Bill: Cost, Latency, Caching, and Pollution follows the reliability evidence with the economics, quantifying what that constrained working set costs in money and latency, and when caching makes the large desk worth paying for.