Lost in the Middle
> **Working claim:** Where you place information in a long prompt changes whether the model uses it. Relevant content at the beginning and end of a context is used reliably; the same content buried in the middle is used poorly.

Lost in the middle describes the failure mode where a model sees relevant information inside a long context window but uses it poorly because position still changes retrieval and reasoning strength.
Working claim: Where you place information in a long prompt changes whether the model uses it. Relevant content at the beginning and end of a context is used reliably; the same content buried in the middle is used poorly. Position is therefore a design variable you control, and treating it as an accident of concatenation order is how correct evidence gets ignored.
Key Takeaways
- A larger context window does not make all positions equally useful; placement remains part of system design.
- The fix is not only more tokens. It is better ordering, evidence selection, recency policy, and evaluation by position.
- If a fact is important enough to decide the answer, the context assembler should not bury it in the weakest part of the prompt.
The U-shaped curve
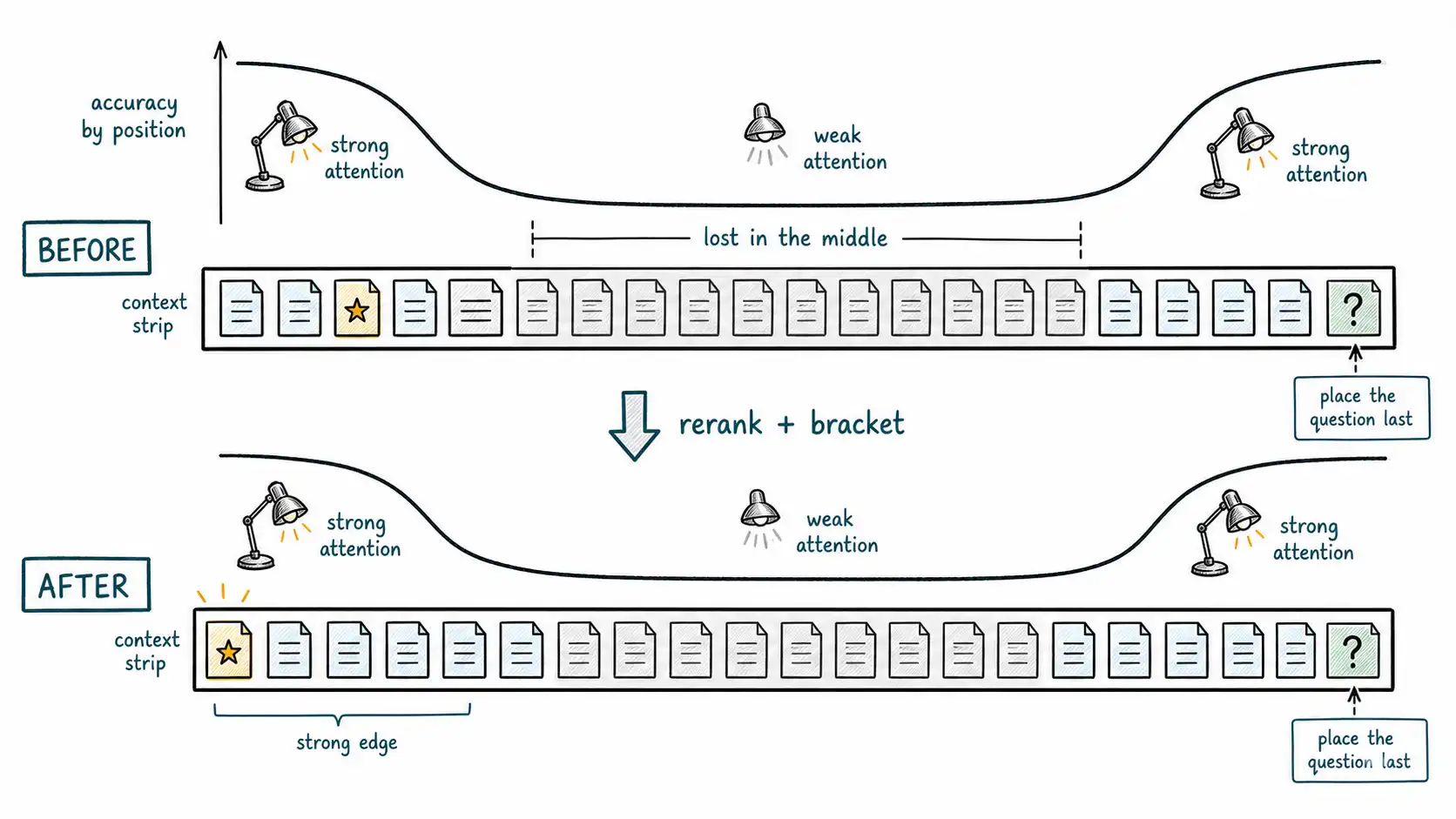
The single most important empirical result for anyone building long-context systems is also one of the easiest to state. In Lost in the Middle, researchers gave models a question whose answer sat in exactly one of many retrieved documents, and they systematically varied where in the ordering that answer-bearing document was placed. The finding, which has held up across model families and tasks, is a U-shaped performance curve: accuracy is highest when the relevant document is at the very start or the very end of the context, and it sags, sometimes dramatically, when the relevant document is somewhere in the middle.
Read that again with the Attention Is All You Need mechanism from Chapter 4 in mind and it stops being mysterious. Attention is finite and position-sensitive. The start of a sequence anchors the model's framing; the end is closest to the point where the next token is generated; the middle is the attention-poor trough. A document in the trough is included but not reliably attended to, rungs one and two of Chapter 2's ladder, prised apart and measured.
The result is uncomfortable because it contradicts the natural assumption that a model "reads everything equally." It does not. And the gap is not small or academic: in the original experiments, models could perform worse with the answer in the middle of many documents than they did with no documents at all and only their parametric knowledge. Adding the right information in the wrong place can be worse than not adding it.
Why "the middle" is not a fixed location
A trap worth flagging early: "the middle" is relative to the assembled prompt, not to any one document. As you add or remove content, the position of your critical passage shifts. A passage that was safely near the end of a short prompt slides into the trough when you prepend a large retrieved block. This is why position bugs are intermittent and maddening, they appear and vanish as the surrounding context changes size, and a fix that "worked yesterday" breaks when retrieval returns more documents today.
The implication is that position must be managed at assembly time, every time, as a function of the final prompt, not set once and forgotten. The context assembler in Chapter 11 does exactly this: it places high-priority evidence at the strong positions after the full prompt size is known, rather than letting concatenation order decide.
Measuring it on your own stack
You should not take the published curve on faith for your model, your prompt format, and your task. The phenomenon is real and general, but its magnitude varies, and the only number that matters is the one for your system. The test is cheap to build and belongs in your evaluation suite permanently. The idea: take one relevant paragraph and a fixed set of filler documents, hold the question constant, and sweep the relevant paragraph through every position in the ordering, recording accuracy at each.
from dataclasses import dataclass
@dataclass
class PositionalResult:
position: int # index where the gold passage was placed
n_positions: int
correct: bool
def positional_sweep(question, gold_passage, filler_passages, model, judge):
"""Place the gold passage at every slot among the fillers; record correctness."""
results = []
n = len(filler_passages) + 1
for pos in range(n):
ordered = filler_passages[:pos] + [gold_passage] + filler_passages[pos:]
prompt = build_prompt(question, ordered)
answer = model.complete(prompt)
results.append(PositionalResult(pos, n, judge(answer, gold_passage)))
return results
def positional_accuracy_profile(results):
"""Accuracy by normalized position bucket: start / middle / end."""
buckets = {"start": [], "middle": [], "end": []}
for r in results:
frac = r.position / max(r.n_positions - 1, 1)
key = "start" if frac < 0.2 else "end" if frac > 0.8 else "middle"
buckets[key].append(r.correct)
return {k: (sum(v) / len(v) if v else None) for k, v in buckets.items()}Run it across several questions and you get a profile like {"start": 0.94, "middle": 0.61, "end": 0.91}. The gap between the start/end numbers and the middle number is your positional penalty, and it is one of the most actionable metrics in the book: if it is large, your wins come from ordering before they come from a better model. Re-run it whenever you change models, prompt format, or typical context length, because all three move the curve.
Five design responses, in order of preference
Knowing the curve, the responses are clear, and they are worth ranking because teams often reach for the weakest one first.
1. Include less (the best response). The cleanest way to avoid the middle trough is to have a short enough context that there is no deep middle. If retrieval returns the three relevant passages instead of ninety, position barely matters, everything is near an edge. This is Chapter 4's "include less" lever, and it is the highest-use move because it attacks the cause (a long pile) rather than compensating for the symptom (poor middle attention).
2. Order by importance, not by source. When you must include several passages, place the most important at the start and the end, and let the least important occupy the middle, where weak attention does least damage. Many retrieval pipelines do the opposite by default, they sort by descending relevance score, dumping the second- and third-best passages into the middle. A simple reorder that brackets the top passages around the filler often recovers a meaningful slice of the positional penalty for free.
3. Put instructions and the query where attention is strong. The task instructions and the user's question are the highest-value tokens in any prompt. Placing the question near the end, right before generation, is a widely used and well-supported habit, because the end is an attention-strong position and keeps the task fresh at the point of answering. Some teams repeat the key instruction at both the start and the end of very long prompts for the same reason (the Anthropic long context tips make this recommendation explicit).
4. Re-rank and prune before assembly. A reranker that orders retrieved passages by genuine relevance lets you both shorten the context (drop the tail) and place the best material at the strong positions. Reranking is the most reliable single addition to a retrieval pipeline for this reason: it improves both the included rung (better top-k) and the attended-to rung (better ordering) at once.
5. Model-level mitigations (use, don't rely on). Research such as Found in the Middle explores positional-encoding adjustments that flatten the U-curve, and newer models advertise improved middle-context behavior. These help, and you should benefit from them, but they are not a license to stop managing position. The penalty shrinks; it rarely vanishes; and you do not control which model version a given request hits. Treat model improvements as reducing the size of a problem you still own, not as removing it.
A concrete before/after
Return one last time to the policy team. Their addendum failure was a textbook position bug stacked on a currency bug. The addendum was included (it was in the 580k-token pile) but landed in the deep middle by concatenation accident, while the longer exclusion clause occupied a more prominent position and won both attention and selection. Here is the difference a position-aware assembly makes, holding the model and the evidence constant:
# Before: concatenation order = file order. Addendum lands wherever, often the middle.
context = "\n\n".join(doc.text for doc in all_docs)
# After: retrieve current+relevant, rerank, bracket the best around the rest,
# and put the question last.
passages = retrieve(question, scope=user_scope, only_current=True, k=8)
ranked = rerank(question, passages) # best first
ordered = bracket_strong_positions(ranked) # [#1, #3, #5, ..., #4, #2]
prompt = (
instructions
+ render(ordered)
+ f"\n\nQuestion (answer using the passages above, cite source ids):\n{question}"
)bracket_strong_positions is a few lines, interleave so the top-ranked passages occupy the first and last slots, but combined with currency-filtered retrieval it converts the exact failure mode that produced a confidently wrong answer into a non-event. No new model. No bigger window. Just respect for the curve.
def bracket_strong_positions(ranked: list) -> list:
"""Place the highest-ranked items at the edges, weakest in the middle."""
front, back = [], []
for i, item in enumerate(ranked):
(front if i % 2 == 0 else back).append(item)
return front + list(reversed(back)) # strongest at start and endThe wider lesson: passing a recall test is not enough
It is tempting to read this chapter as "put important stuff at the edges" and move on. The deeper lesson sets up the next chapter. Lost in the middle measures a model's ability to retrieve a single fact as a function of position. That is the simplest possible long-context task, find one needle. Real work is harder: synthesize across several passages, follow a chain of reasoning that spans documents, hold a constraint stated early while applying it to content stated late. A model can pass a single-fact positional test and still fail these, because reasoning over a long context is more demanding than retrieving from it. Chapter 6 takes up exactly this gap, why passing needle-in-a-haystack tells you far less than it appears to, and what to measure instead.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
Models use information unevenly across position: the Lost in the Middle result shows a U-shaped accuracy curve where content at the start and end of a long context is used reliably and content in the middle is used poorly, sometimes worse than not including it at all. The mechanism is Chapter 4's finite, position-sensitive attention."The middle" is relative to the whole assembled prompt and shifts as context size changes, so position must be managed at assembly time, every time. Measure your own positional penalty with a sweep test and keep it in your eval suite. The design responses, ranked: include less so there is no deep middle; order by importance and bracket the best passages around the edges; put instructions and the query at strong positions, especially the end; rerank and prune before assembly; and benefit from model-level mitigations without relying on them. The policy team's failure was a position bug atop a currency bug, fixable by currency-filtered retrieval plus position-aware ordering, no new model required. The deeper lesson: positional recall is the easiest long-context task, and passing it predicts little about multi-passage reasoning, which is the subject of the next chapter.
Why Passing Needle-in-a-Haystack Is Not Enough tests the deeper limit, showing that perfect positional recall predicts almost nothing about multi-hop reasoning and aggregation, the tasks products actually perform.