The Context Assembler
> **Working claim:** A production prompt should be *assembled*, not concatenated. The assembler is a real component with a budget, a priority order, and a policy, it decides what goes on the desk, in what order, and what gets cut when the budget is exceeded.

A context assembler is the part of the system that decides what evidence, memory, state, policy, and recent conversation enter the prompt, in what order, and under what token budget.
Working claim: A production prompt should be assembled, not concatenated. The assembler is a real component with a budget, a priority order, and a policy, it decides what goes on the desk, in what order, and what gets cut when the budget is exceeded. Teams that do not have an assembler have one anyway; it is just implicit, undocumented, and wrong under pressure.
Key Takeaways
- Context assembly is an architecture component, not an f-string with unlimited appetite.
- The assembler should apply permission, relevance, ordering, compression, and budget rules before the model sees anything.
- Good context assembly makes long windows cheaper, safer, and easier to debug because every included item has a reason.
From string concatenation to a component
Most prompts begin life as an f-string: some instructions, plus the retrieved text, plus the history, plus the question. It works in the demo and then fails silently the first time the inputs are large, because an f-string has no budget and no priorities. When the retrieved text is huge, the f-string does not drop the least important block, it sends everything, blows the window, and either errors or gets truncated by the provider at an arbitrary boundary that may sever your golden fact. The f-string is an assembler with no policy, and "no policy" is itself a policy: *include everything, fail unpredictably. *
The fix is to make the assembler explicit. A context assembler is a function that takes the available components, a token budget, and a policy, and returns a final prompt that respects the budget by deliberate choices about priority, ordering, and compaction. It is the software embodiment of Chapter 3's curation rule and the place where every lever from Movements II and III is pulled. MemGPT's framing of the LLM as an OS managing a memory hierarchy is exactly this: the assembler is the pager that decides what to fault into the limited "main context" for this request.
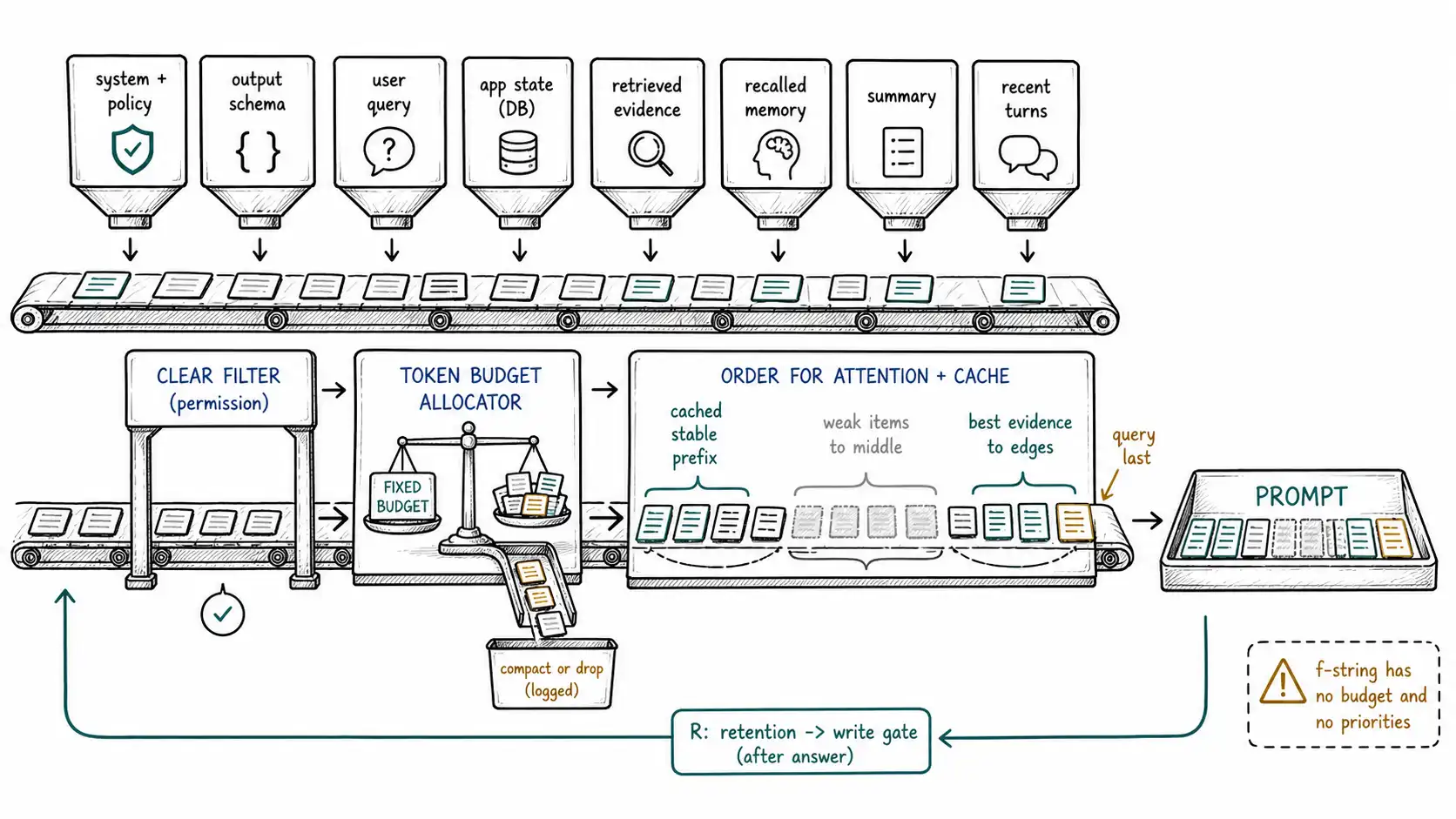
The CLEAR pass
Before allocating tokens, the assembler runs the CLEAR pass from the front matter, five questions that determine what is even eligible for the desk:
- C: Current task. What is being asked now? This sets the relevance target for retrieval and recall and the output schema.
- L: Legal/permission boundary. What may this requester see and what may be recalled? This is applied before retrieval and recall, so forbidden content is never even a candidate (the structural enforcement from Chapters 9-10).
- E: Evidence sources. Which documents, records, APIs, and memories support the task? The assembler gathers candidates from each.
- A: Attention budget. What fits, and what should be excluded even though it fits? This is the allocator, below.
- R: Retention decision. What should persist after this answer? This queues candidate facts for the write gate (Chapter 9) after the response.
CLEAR is not a template that appears in the prompt; it is the assembler's control flow. C and E gather, L filters, A allocates and orders, R schedules the write-back. Hold that shape, gather, filter, allocate, schedule, as the assembler's skeleton.
The priority order
When the budget is tight, something gets cut, and the order in which things get cut is the most consequential policy decision in the system. A sane default priority, highest to lowest (highest survives truncation, lowest is sacrificed first):
| Priority | Component | Why this rank | Cut behavior |
|---|---|---|---|
| 1 | System instructions / safety policy | Defines role and hard constraints; never optional | Never cut |
| 2 | Output schema / format spec | Without it the answer is unusable | Never cut |
| 3 | Current user query | It is the task | Never cut |
| 4 | Critical application state | Source-of-truth facts (plan tier, case status) | Never cut; it's small |
| 5 | Top-ranked retrieved evidence | The grounding for the answer | Cut from the tail (lowest-ranked first) |
| 6 | Recalled durable memory | Personalization, preferences | Cut low-scoring first; keep profile |
| 7 | Conversation summary | Continuity | Compress further before cutting |
| 8 | Recent verbatim turns | Local coherence | Reduce count |
| 9 | Older verbatim history | Largely redundant with summary | Cut first |
The principle: cut redundancy and low-rank tails before you cut instructions, the query, or source-of-truth state. The f-string's implicit policy gets this exactly backwards, under truncation it tends to drop whatever is at the end, which is often the query or the most recent, most relevant material. An explicit allocator drops the right things.
The budget allocator
Now the allocator itself. It works in passes: reserve the non-negotiable blocks (priorities 1-4 and output headroom), then distribute the remaining budget across the negotiable blocks (5-9) in priority order, compacting or trimming each to fit. Tokens are measured, never estimated (Chapter 4), using the target model's tokenizer, such as the OpenAI tiktoken library.
from dataclasses import dataclass
@dataclass
class Block:
name: str
priority: int # 1 = highest
content: str
cuttable: bool # can we trim/compress this block?
min_tokens: int = 0 # floor below which the block is useless
def allocate(blocks: list[Block], window: int, output_reserve: int,
count, compact) -> list[Block]:
input_budget = window - output_reserve
blocks = sorted(blocks, key=lambda b: b.priority)
# Pass 1: reserve non-cuttable blocks. If they alone overflow, that's a
# design error worth raising loudly, not truncating silently.
fixed = sum(count(b.content) for b in blocks if not b.cuttable)
if fixed > input_budget:
raise ContextError(f"Non-cuttable content ({fixed}) exceeds budget "
f"({input_budget}). Fix priorities or output_reserve.")
remaining = input_budget - fixed
out = []
for b in blocks:
if not b.cuttable:
out.append(b); continue
cost = count(b.content)
if cost <= remaining:
out.append(b); remaining -= cost
elif remaining >= b.min_tokens:
b.content = compact(b.content, target_tokens=remaining) # summarize/trim
out.append(b); remaining -= count(b.content)
else:
log(f"Dropped '{b.name}' (priority {b.priority}): no budget") # audited
return outThree properties make this trustworthy. It raises loudly when the non-negotiable content alone overflows, instead of silently truncating something critical, a class of bug that otherwise hides for months. It compacts before dropping, so a block that does not fit verbatim can still contribute a summary. And every drop is logged, so when an answer is poor you can check whether the relevant block was budgeted out. The allocator turns "the prompt got too big and something disappeared" from a mystery into a logged, attributable event.
Ordering for attention and for cache
Allocation decides what is on the desk; ordering decides where, and Movements II taught that both matter, for accuracy (positional penalty, Chapter 5) and for cost (cache prefix, Chapter 7). These two goals mostly align, and the assembler serves both with one ordering rule:
[ 1. cacheable stable prefix ] system instructions · safety policy · output schema · stable few-shot
[ 2. strong-position evidence ] highest-ranked retrieved passage · profile facts
[ 3. middle (attention-poor) ] lower-ranked evidence · summary · older turns
[ 4. strong-position close ] second-highest evidence · critical app state · recent turns
[ 5. the query, last ] the current user question + restated key instructionThe stable prefix goes first so prompt caching can reuse it across requests (Chapter 7). The highest-value evidence is bracketed at the two strong positions (start of the variable region and just before the query), with the weakest material parked in the attention-poor middle where it does least harm, the Lost in the Middle U-curve (Chapter 5), extended by RULER's finding that effective usable length collapses fast for complex tasks (Chapter 6). The query goes last, at the strongest position, immediately before generation. One ordering, two wins: cheaper and more accurate.
There is a small tension worth naming: caching wants the prefix byte-identical across requests, while positional ordering wants the best variable content at strong positions. They do not actually conflict, because the cacheable prefix is the stable content (instructions, schema) and the position-sensitive content is the variable content (evidence, query) that sits after the cache boundary. Keep the boundary clean, never let variable content leak into the cached prefix, or you destroy the cache hit, and both goals are satisfied.
Compaction with provenance
Several blocks (conversation summary, lower-ranked evidence) are compacted to fit. Compaction is lossy by definition, and the danger is that it loses the one thing you most need: where the content came from. A summary that says "the customer had a billing issue" has thrown away which ticket, when, and what resolution, so if the model uses it, you cannot trace the claim. Compaction must therefore preserve provenance outside the prose:
@dataclass
class CompactedBlock:
summary: str # the lossy text the model reads
provenance: list[str] # source ids the summary was derived from
covers_turns: tuple[int, int] # or doc ids, date range, etc.
lossy: bool = True # flag so downstream knows not to over-trust
def compact_history(turns, target_tokens, summarizer) -> CompactedBlock:
text = summarizer(turns, target_tokens=target_tokens)
return CompactedBlock(
summary=text,
provenance=[t.event_id for t in turns],
covers_turns=(turns[0].index, turns[-1].index),)The summary text goes on the desk; the provenance stays attached as metadata (and in the audit log). When the model produces an answer derived from the summary, you can still trace it back to the originating turns, the same traceability principle the memory schema enforced in Chapter 9, applied to transient compaction. A summary without provenance is a rumor with good grammar.
Putting it together: the assemble function
The full assembler is just the CLEAR shape wired to the allocator, the ordering rule, and compaction:
def assemble(task, user, store, retriever, model_window, token_count) -> str:
# C + E: gather candidates for this task.
scopes = permitted_scopes(user, task) # L: permission first
evidence = retriever.search(task.query, scope=scopes, only_current=True, k=12)
evidence = rerank(task.query, evidence) # best-first
memories = recall(user.subject_key, scopes, task.query,
assembler_budget=MEMORY_BUDGET, store=store, now=now())
app_state = load_state(task.entity_id) # structured source of truth
blocks = [
Block("system", 1, SYSTEM_PROMPT, cuttable=False),
Block("schema", 2, task.output_schema, cuttable=False),
Block("query", 3, task.query, cuttable=False),
Block("state", 4, render_state(app_state), cuttable=False),
Block("evidence", 5, render(evidence), cuttable=True, min_tokens=200),
Block("memory", 6, render(memories), cuttable=True, min_tokens=50),
Block("summary", 7, render(task.summary), cuttable=True, min_tokens=80),
Block("recent", 8, render(task.recent_turns),cuttable=True),]
# A: allocate under budget, then order for attention + cache.
kept = allocate(blocks, model_window, OUTPUT_RESERVE, token_count, compact)
prompt = order_for_attention_and_cache(kept, query_block="query")
# R: schedule retention AFTER the answer (not shown) via the write gate.
return promptRead against the f-string it replaces, the difference is not cleverness; it is accountability. Every component has a priority, a measured cost, a cut behavior, and an audit trail. When this prompt produces a bad answer, you can answer every rung of the Chapter 2 ladder from the assembler's logs: was the fact included (did it survive allocation?), where was it positioned, was a distractor included, was a stale memory recalled. The f-string can answer none of these. The assembler is how context engineering stops being a vibe.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
A production prompt should be assembled by an explicit component, not concatenated by an f-string, because an f-string has no budget and no priorities, so under pressure it overflows or truncates at an arbitrary point that may sever critical content. The assembler runs the CLEAR control flow: gather candidates for the Current task from Evidence sources, filter by the Legal/permission boundary before retrieval and recall, Allocate the attention budget, and schedule the Retention write-back after the answer. A documented priority order decides what survives truncation, instructions, schema, query, and source-of-truth state are never cut, while low-ranked evidence tails and old verbatim history are sacrificed first. The budget allocator measures tokens, reserves non-cuttable blocks (raising loudly if they alone overflow), compacts before dropping, and logs every drop.Ordering serves accuracy and cost together: a byte-stable cacheable prefix first, the best evidence bracketed at strong positions, weak material in the attention-poor middle, and the query last.Compaction preserves provenance outside the prose so summarized content stays traceable. The payoff over the f-string is accountability: every rung of the Chapter 2 ladder becomes answerable from the assembler's logs.
Conflicts, Recency, and Knowing Which Tool to Reach For addresses what the assembler does when its sources disagree, the conflict-resolution logic that prevents the prompt from carrying contradictory ground truth.