The Operational Bill: Cost, Latency, Caching, and Pollution
> **Working claim:** A large context is not a free capability you switch on; it is a recurring operational cost paid on every request in three currencies: money, latency, and accuracy.

The operational bill of long context is paid in token cost, latency, cache strategy, and prompt pollution, so the right window size is an economic decision as much as a capability decision.
Working claim: A large context is not a free capability you switch on; it is a recurring operational cost paid on every request in three currencies: money, latency, and accuracy. Prompt caching changes the money math for stable context but not for the variable, retrieved context where the spend actually lives. And the third currency, accuracy, is the one teams forget: irrelevant context does not just cost more, it makes answers worse.
Key Takeaways
- Longer prompts increase more than token spend; they also increase latency, cache invalidation, debugging surface, and attention risk.
- Prompt caching helps only when stable prefixes, update cadence, and privacy boundaries are designed deliberately.
- The cheapest context is the context you can prove was needed for the decision.
Three currencies, paid every request
The mirage frames a large window as a capability you unlock once. The operational reality is that you pay for it on every single request, and you pay in three currencies that trade against each other:
- Money: you are billed per input token, so a large prompt sent at scale is a recurring line item, not a one-time cost.
- Latency: larger inputs take longer to process, raising time-to-first-token and total response time, which users feel directly.
- Accuracy: irrelevant tokens dilute attention and add distractors, so beyond some point more context lowers answer quality, as documented in Lost in the Middle (Chapter 5) and RULER (Chapter 6).
A mature team models all three explicitly before committing to a "just use the big window" architecture, because the bill compounds with traffic and the accuracy cost is invisible until you measure it. This chapter builds the worksheet.
The money currency: a worksheet, not a vibe
Start with the arithmetic, because it is the part teams hand-wave and then get a surprising invoice for. Cost per request is dominated by input tokens for context-heavy systems, and total cost scales with traffic:
from dataclasses import dataclass
@dataclass
class CostModel:
input_price_per_1k: float # USD per 1k input tokens
output_price_per_1k: float # USD per 1k output tokens
cached_input_price_per_1k: float # usually a large discount on cache hits
def request_cost(input_tokens, output_tokens, cached_tokens, m: CostModel):
fresh_input = max(input_tokens - cached_tokens, 0)
return (
fresh_input / 1000 * m.input_price_per_1k +
cached_tokens / 1000 * m.cached_input_price_per_1k +
output_tokens / 1000 * m.output_price_per_1k
)
def daily_cost(reqs_per_day, *args):
return reqs_per_day * request_cost(*args)Now run two architectures through it for the same workload: say 50, 000 requests a day, 400 output tokens each. Architecture A dumps a 200k-token corpus into every prompt. Architecture B retrieves ~6k tokens of relevant passages plus a 4k-token stable instruction prefix. Even before caching, A's input bill is roughly twenty times B's, for worse answers (per Chapter 6's effective-context result). The point of the worksheet is not the exact figure, prices change, but the ratio."Fits in the window" can mean "costs twenty times as much per request, forever." That is an architecture decision being made by accident.
The single most useful habit here: put the cost-per-successful-task on a dashboard, not the cost-per-request. A system that retries, falls back, or escalates because its bloated context produced a bad answer pays for the failed attempts too. The honest denominator is the resolved task.
The latency currency: input size is on the critical path
Latency has two components that behave differently. Time to first token (TTFT) is dominated by prefill, the model processing the entire input prompt before it can emit anything. Prefill cost grows with input length, so a giant prompt makes the user wait before the first word appears. Inter-token latency governs how fast the response streams once it starts, and depends more on output length and serving load than on input size.
The consequence: a large input prompt taxes the part of latency users notice most, the silence before the answer begins. A retrieval-based architecture that sends 10k tokens starts responding far sooner than one that sends 200k, even when the eventual answer is identical. For interactive products (copilots, chat, support), this TTFT difference is often the dominant UX factor, and it is paid every turn.
Serving-layer techniques soften the absolute numbers, PagedAttention / vLLM improved throughput and memory efficiency for LLM serving substantially, but they do not reverse the direction: longer input, longer prefill, longer wait. You manage latency the same way you manage cost, by sending less and reusing more.
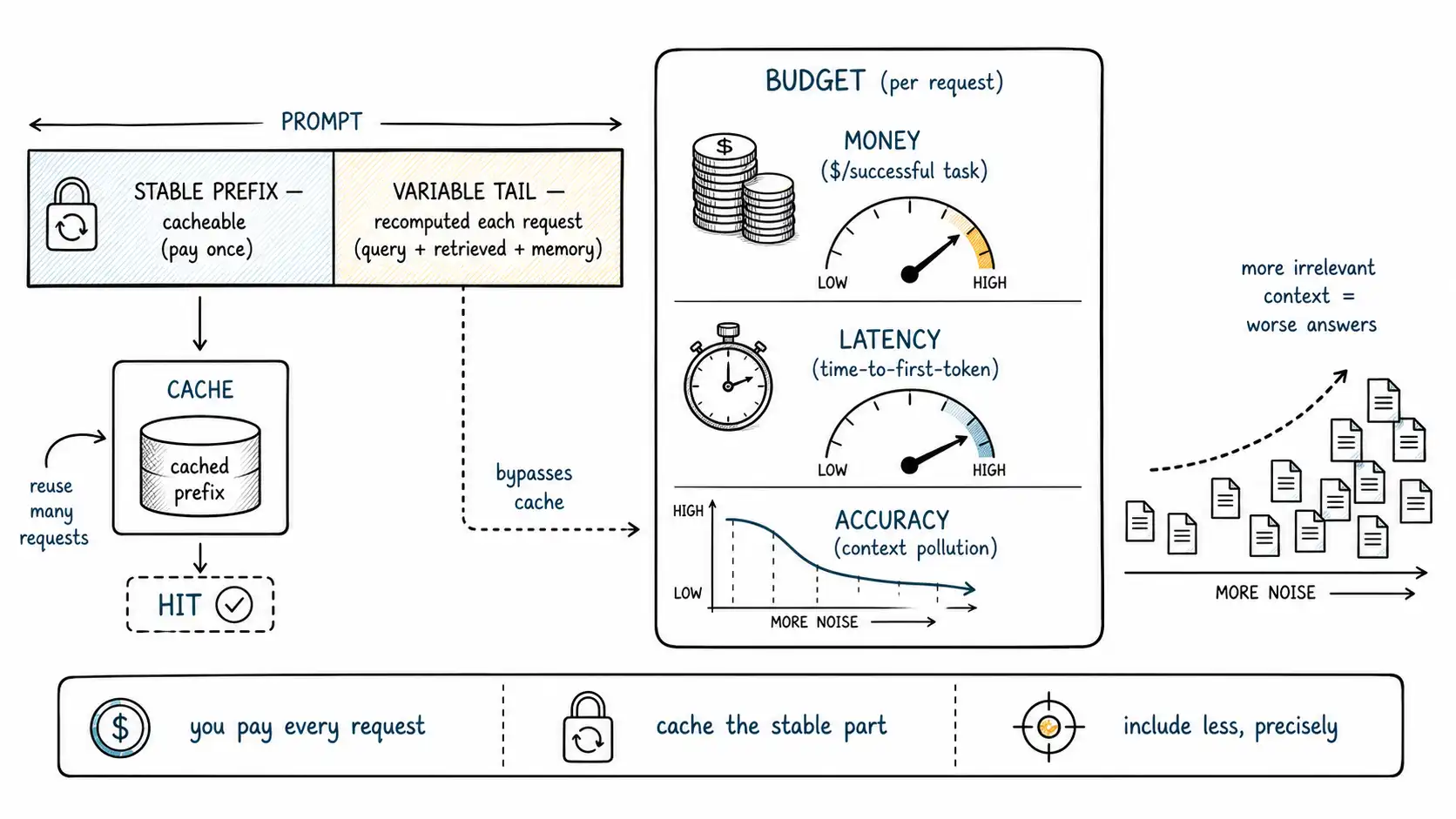
Caching: real use, on the stable part only
Prompt caching (Anthropic) and context caching (Google) are the most important cost-and-latency levers for context-heavy systems, and also the most misunderstood. The mechanism: if a prefix of your prompt is identical across requests, the provider can cache the model's internal representation of that prefix and skip recomputing it, charging a steep discount on the cached tokens and cutting prefill time for them.
The critical word is prefix, and it dictates how you must structure prompts to benefit:
- Caching works on stable prefixes. System instructions, schemas, policies, few-shot examples, a fixed long document you query repeatedly, these change rarely and can be cached, so you pay full price once and a fraction thereafter.
- Caching does not help the variable tail. Retrieved passages, the user's query, and recalled memory differ every request; they sit after the stable prefix and are recomputed each time. This is usually where most of the relevant tokens live.
- Order for cacheability. Put the stable, cacheable content first and the variable content last. A prompt that interleaves stable and variable content, or that puts the query first, defeats prefix caching and pays full price for everything.
[ cached prefix: system + policy + schema + stable few-shot ] <- pay once, reuse
[ variable tail: retrieved passages + recalled memory + query ] <- recomputed each callSo caching reshapes the money argument but does not reverse the chapter's thesis. It makes a stable large context (a fixed manual you answer questions about all day) economically reasonable, a genuine and important win. It does almost nothing for the variable bloat of dumping a different giant corpus subset into every request. And it changes none of the accuracy math: a cached distractor is still a distractor. Cheaper wrong context is still wrong context.
The accuracy currency: context pollution
Here is the currency teams forget, and the one that most directly serves the book's thesis. Adding irrelevant context does not merely cost money and latency; it degrades the answer. The mechanism is everything from Chapters 4-6: attention is finite and gets diluted across more tokens; irrelevant passages are distractors that compete for selection; and longer inputs push you past the effective context for your task. The result is context pollution, a measurable drop in quality as you add material that is not relevant.
This is counterintuitive and worth proving on your own stack, because it overturns the "more is safer" instinct that drives the mirage. The experiment is a pollution sweep: hold the relevant evidence and the question fixed, and add increasing amounts of irrelevant-but-plausible filler, measuring accuracy at each level.
def pollution_sweep(question, gold_passages, distractor_pool, model, judge,
levels=(0, 5, 20, 50, 100)):
"""Accuracy as a function of how many irrelevant passages we add."""
profile = {}
for n in levels:
distractors = distractor_pool[:n]
# Keep gold passages at strong positions so we isolate POLLUTION,
# not the positional effect from Chapter 5.
ordered = bracket_strong_positions(gold_passages + distractors)
prompt = build_prompt(question, ordered)
answer = model.complete(prompt)
profile[n] = judge(answer, gold_passages)
return profile # e.g. {0:0.95, 5:0.93, 20:0.88, 50:0.79, 100:0.68}A typical result curves downward: the same correct evidence, plus more noise, yields worse answers. The drop is your pollution sensitivity, and it puts a hard number on the cost of the "include it, it fits" reflex. The cleanest defense is the one we keep arriving at: retrieve and include less, precisely. Pollution is the accuracy-side reason that curation (Chapter 3) and reranking (Chapter 5) are not just efficiency moves, they are correctness moves.
A combined decision worksheet
Put the three currencies together and the "long context vs. retrieval" choice becomes a calculation instead of a preference. For a given task, estimate:
| Factor | Long-context-dump | Retrieval + small context |
|---|---|---|
| Input tokens / request | Whole corpus (e. g. 200k) | Relevant subset (e. g. 6k) |
| Cacheable share | High only if corpus is fixed across requests | Stable prefix cacheable; retrieved tail not |
| TTFT | High (large prefill every request) | Low |
| Money / request | High (unless fully cached fixed corpus) | Low |
| Accuracy | Risk of pollution + effective-context overrun | Higher, if retrieval recall is good |
| Operational dependency | None beyond the model | A retrieval/index system to build and maintain |
The honest reading: long-context-dump wins only in the narrow case of a fixed, stable, fully relevant corpus that you can cache and that fits inside the effective (not advertised) context for your task: the whole-set-reasoning case from Chapter 3. For the common case of a large, changing corpus where each query needs a different slice, retrieval plus a small, well-ordered, cache-prefixed context wins on all three currencies at once. Chapter 12 turns this into a full decision table including the "use both" hybrid; this chapter supplies the cost reasoning behind it.
Closing Movement II
Movement II set out to explain why the curation rule from Chapter 3 is necessary by studying how the window behaves when you violate it. Chapter 4 gave the mechanism: tokens, a stateless per-request bound, and finite position-sensitive attention. Chapter 5 showed the positional penalty, included is not attended to. Chapter 6 showed the effective-context collapse, fitting is not reasoning, and the usable length is far below the sticker, shrinking with task difficulty. This chapter added the bill: every token costs money and latency on every request, caching helps only the stable prefix, and irrelevant context degrades accuracy outright through pollution.
Put together, the four chapters retire the strongest form of the mirage for good. Even setting memory entirely aside, even asking only "how well does a model use the contents of one window?", the answer is: unevenly, expensively, and only across a length much shorter than advertised, with quality that falls as you add the very material the mirage tells you to add. Long context is a real and useful capability operated under real constraints. It is a constrained working set, not an archive. Movement III now builds the archive the mirage told you that you didn't need.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
A large context is a recurring operational cost paid every request in three currencies. Money: you are billed per input token, so corpus-dumping can cost an order of magnitude more per request than retrieval, and the honest metric is cost per successful task, not per request. Latency: large inputs lengthen prefill and thus time-to-first-token, taxing the silence users notice most, and serving optimizations soften but do not reverse this.Caching (prompt/context caching) is real use but only on a stable prefix, order prompts stable-first, variable-last; it makes a fixed large context affordable but does nothing for variable retrieved bloat and nothing for accuracy. Accuracy: the forgotten currency, irrelevant context causes measurable context pollution, so more is not safer, it is often worse, and curation/reranking are correctness moves, not just efficiency moves. A combined worksheet shows long-context-dump wins only for a fixed, stable, fully relevant, cacheable corpus inside the effective context; otherwise retrieval plus a small, ordered, cache-prefixed context wins on all three currencies. Movement II together retires the strongest mirage: even within one request the window is constrained, expensive, and task-sensitive, which is why the durable archive of Movement III is necessary.
A Working Taxonomy of Memory opens Movement III by naming the ten kinds of state that belong in the archive, the infrastructure the operational argument shows you cannot skip.