Reading Memory: Recency, Relevance, and Policy
> **Working claim:** Recall is not a lookup; it is a ranked, filtered, policy-gated query that decides which durable facts deserve a place on the desk for *this* task.

Reading memory is a policy decision before it is a retrieval decision: the system has to decide which remembered facts are recent enough, relevant enough, and allowed enough to enter the prompt.
Working claim: Recall is not a lookup; it is a ranked, filtered, policy-gated query that decides which durable facts deserve a place on the desk for this task. A memory store that returns everything it knows about a user is as useless as no memory at all, it just moves the context-pollution problem from documents to facts.
Key Takeaways
- Memory retrieval should filter by permission and policy before similarity gets a vote.
- Recency and relevance solve different problems; a new irrelevant memory is still noise, and an old authoritative fact may still matter.
- The read gate protects the prompt from stale, unauthorized, duplicated, or over-personalized context.
The symmetric danger
Chapter 9 argued that writing is the dangerous operation. Reading is the frequent one, it happens on every request, and its failure mode is quieter but just as corrosive. The write gate keeps junk out of the store. The read gate keeps junk out of the prompt. Even a perfectly curated store will wreck answers if recall dumps all of it onto the desk, because everything Movement II taught applies to memory facts exactly as it applies to documents: finite attention, the middle trough (as Lost in the Middle documented for documents, and the same physics apply to facts), distractors, pollution. A hundred true facts about a user, recalled indiscriminately, is a hundred-fact pollution problem.
So recall must do for memory what retrieval does for documents: return a small, relevant, current, permitted slice, ranked and positioned deliberately. The structure of a good recall query has four stages, applied in this order: filter by policy, filter by currency, rank by relevance-and-recency, then trim to budget. Order matters, you filter before you rank because ranking an unfiltered set wastes effort and risks surfacing forbidden facts, and you trim last because trimming before ranking discards facts you have not yet scored.
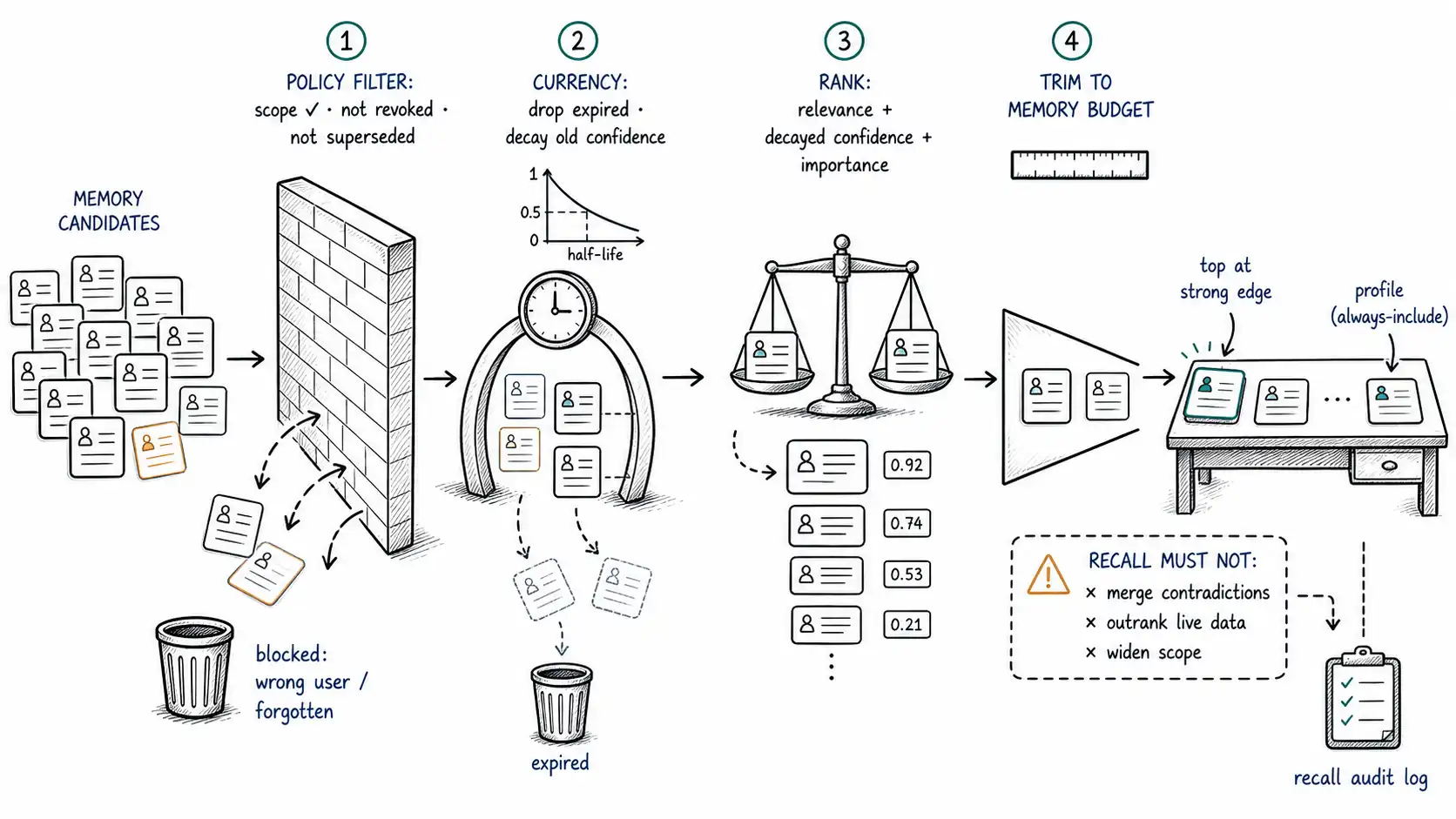
Stage one: policy filter (non-negotiable, first)
The very first thing recall does is exclude what this requester is not allowed to see, and what has been revoked. This is not a ranking signal you can trade off; it is a hard boundary applied before anything else, because a relevance score can never justify surfacing a memory the user has no right to, an expression of the purpose-limitation and data-minimisation principles in GDPR Article 5. The cross-user leak, recalling user A's stored fact into user B's session, is prevented here, structurally, in the WHERE clause, not in the prompt and not in the model's good behavior.
-- Stage 1+2: hard filters. Nothing past this point can be unauthorized or stale.
SELECT memory_id, claim, category, confidence, source_event_id,
created_at, last_confirmed_at, expires_at
FROM durable_memory
WHERE subject =:subject_key -- this user/entity only
AND visibility_scope IN (:allowed_scopes) -- requester is permitted
AND revoked_at IS NULL -- not forgotten
AND superseded_by IS NULL -- only current head of correction chain
AND (expires_at IS NULL OR expires_at > now()); -- not expired (currency)Four of those clauses are the read-side payoff of the schema built in Chapter 9. visibility_scope enforces permission; revoked_at IS NULL enforces erasure; superseded_by IS NULL enforces correction (you recall the current belief, not the replaced one); expires_at enforces currency. None of these can be left to the model. They are the difference between a memory system and a privacy incident.
Stage two: currency, and the decay of confidence
Currency is partly handled by expires_at above, but there is a subtler signal: a fact that was true and has not been re-confirmed in a long time should be trusted less, even if it has not formally expired. Generative Agents and MemoryBank both model memory with a recency/decay component for exactly this reason: older, un-reinforced memories should weigh less in recall.
The right way to express this is an effective confidence that decays with time since last confirmation, rather than mutating the stored confidence:
import math
def effective_confidence(mem, now, half_life_days_by_category) -> float:
"""Stored confidence decayed by time since last confirmation.
Stable attributes decay slowly; volatile facts decay fast."""
hl = half_life_days_by_category.get(mem.category, 180)
age_days = (now - (mem.last_confirmed_at or mem.created_at)).days
decay = 0.5 ** (age_days / hl)
return mem.confidence * decayThe half-life is category-specific, which matters: "user's name" should barely decay (a stable attribute), while "user is currently traveling" should decay within days (a volatile fact that probably should have had a short expires_at anyway). Decay is a soft companion to the hard expires_at: expiry removes a fact from consideration entirely; decay quietly lowers its rank so fresher, re-confirmed facts win the limited slots on the desk.
Stage three: rank by relevance and recency together
With the permitted, current set in hand, recall ranks by how relevant each memory is to the current task, combined with effective confidence and recency. Relevance is typically a semantic match between the memory's claim and the current query (the embeddings machinery from the sibling book), but the recall score blends several signals:
def recall_score(mem, query_embedding, now, weights, half_lives) -> float:
relevance = cosine(mem.embedding, query_embedding) # task fit
conf = effective_confidence(mem, now, half_lives) # trust, decayed
importance = IMPORTANCE_BY_CATEGORY.get(mem.category, 0.5) # profile > aside
return (weights.relevance * relevance +
weights.confidence * conf +
weights.importance * importance)The three-way blend mirrors Generative Agents' retrieval function (relevance + recency + importance), and MemGPT's analogous paging heuristics for which memories to fault into the main context, and is worth keeping rather than collapsing to pure semantic relevance, because a highly relevant but low-confidence, decayed memory should not outrank a slightly less relevant but rock-solid profile fact. Tuning the weights is an evaluation task (Chapter 13), not a guess; the structure, however, should be this blend.
One category deserves a bypass: profile facts (name, language, accessibility needs, communication preferences) are relevant to almost every request and cheap to include, so many systems always inject a small, fixed profile block regardless of semantic match, and rank only the episodic/semantic memories by relevance. This is a deliberate exception, justified because profile facts are few, stable, and broadly applicable, the opposite of the pollution risk.
Stage four: trim to budget, and position deliberately
Finally, recall trims the ranked list to the memory budget, the slice of the prompt's token allowance assigned to durable memory by the context assembler (Chapter 11). This is where memory recall connects to everything in Movement II: the recalled facts are tokens on the desk, subject to the same finite-attention and positional rules as documents. So recall does not just return facts; it returns a small set and hands the assembler enough information to position them well (profile facts and the single highest-scoring memory near a strong position, per Chapter 5).
def recall(subject_key, allowed_scopes, query, assembler_budget, store, now):
candidates = store.hard_filtered(subject_key, allowed_scopes, now) # stages 1-2
profile = [m for m in candidates if m.category == "profile"][:MAX_PROFILE]
rankable = [m for m in candidates if m.category!= "profile"]
ranked = sorted(rankable,
key=lambda m: recall_score(m, embed(query), now, W, HL),
reverse=True)
chosen = trim_to_tokens(profile + ranked, assembler_budget.memory_tokens)
log_recall(subject_key, query, [m.memory_id for m in chosen]) # audit the read
return chosenNote the log_recall call. The read is audited just as the write was: which memories were surfaced for which query. When an answer is wrong, recall logs let you ask "was the right memory available but not recalled (a ranking miss) or recalled but ignored (a model/position problem)?", the Chapter 2 ladder applied to memory.
What recall must refuse to do
A few behaviors are tempting and wrong, and naming them prevents the most common recall bugs.
It must not silently merge contradictions. If two non-superseded memories conflict (they shouldn't, if the write gate did its job, but stores drift), recall must not concatenate both into the prompt as if both are true, that hands the model a distractor pair and lets position decide which "wins." It should surface the conflict for resolution (Chapter 12), or recall only the higher-confidence one and flag the other. Concatenating contradictions is how an assistant cites two different return policies in one answer.
It must not treat recalled memory as more authoritative than current evidence. A recalled memory is a belief about the past; a freshly retrieved document or a live application-state read is current ground truth. When they disagree, memory says "user is on the Pro plan, " the billing database says "Free", the live source wins, and the stale memory should be flagged for re-confirmation or supersession. Chapter 12 builds this conflict hierarchy; recall's job is to carry the provenance (this came from memory, that came from the live DB) so the assembler and the model can tell them apart, rather than flattening everything into undifferentiated prose.
It must not expand scope to be "helpful." A recall that, finding few relevant memories, broadens the visibility_scope or the subject key to return something has just created a leak vector. Returning fewer facts, even zero, is correct when nothing permitted and relevant exists. Empty recall is a valid, safe result; scope creep to avoid it is a bug.
Closing Movement III
Movement III built the archive the mirage said you did not need. Chapter 8 named the ten kinds of memory and the lines between them, most importantly the immutable-episode / revisable-semantic split and the model-never-sees-it audit log. Chapter 9 built the write gate that turns provisional candidate facts into governed durable memories through three questions, is it true, should it persist, is it allowed, and built correction (supersession) and erasure (revocation) into the schema from the start. This chapter built the read gate: a four-stage query, policy filter, currency filter, blended relevance/recency/importance ranking, trim to budget, that puts a small, permitted, current, well-positioned slice of memory onto the desk and refuses to merge contradictions, outrank live data, or widen scope.
Together the three chapters establish the thesis's constructive half. Memory is a system: stores with schemas, gates with policies, flows between tiers, provenance on every record, and audit on every write and read. None of it is the context window, and none of it is provided by making the window bigger. The window is where the recalled slice is presented; the system is what decides the slice. Movement IV now assembles the full desk, instructions, evidence, this recalled memory, tool results, constraints, under a token budget, which is where context engineering becomes a discipline rather than a habit.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
Recall is a ranked, filtered, policy-gated query, not a lookup, and its failure mode, dumping everything known about a user onto the desk, recreates Movement II's pollution problem with facts instead of documents. A good recall runs four stages in order: a policy filter first (scope, not revoked, not superseded, the structural prevention of cross-user leaks and the enforcement of erasure and correction), a currency filter (drop expired facts; decay the effective confidence of old, un-reconfirmed ones by a category-specific half-life), a ranking that blends relevance to the current task with decayed confidence and category importance (mirroring Generative Agents' relevance+recency+importance function), and a trim to the memory budget with deliberate positioning, profile facts always included as a justified exception. Reads are audited like writes, so a wrong answer can be diagnosed as a ranking miss versus an ignored recall. Recall must refuse three temptations: merging contradictions into the prompt, treating stale memory as more authoritative than live evidence (live ground truth wins; carry provenance so they can be told apart), and widening scope to avoid an empty result (empty recall is safe; scope creep is a leak). Movement III thus delivers the constructive thesis, memory is a governed system of stores, gates, flows, provenance, and audit, none of which the context window provides.
The Context Assembler takes the recalled slice and every other component and builds the full prompt, the explicit, budgeted, policy-driven component that replaces the f-string.