The Million-Token Mirage
A large context window is a bigger desk, not an archive. It increases how much a model can be shown at once. It does nothing, by itself, to decide what should be kept, trusted, updated, permissioned, or recalled tomorrow.

The million-token mirage is the belief that a huge context window removes the need for retrieval, memory policy, summarization, ordering, and evaluation. It does not.
Working claim: A large context window is a bigger desk, not an archive. It increases how much a model can be shown at once. It does nothing, by itself, to decide what should be kept, trusted, updated, permissioned, or recalled tomorrow.
Key Takeaways
- A million tokens can increase what is visible while making selection, cost, latency, and attention failures harder to see.
- Long context is useful when the system has a reason to include each segment and a way to test whether it was used.
- The window does not replace memory. It raises the standard for context assembly.
The headline and the inference it invites
Every leap in context length arrives as a single number. Four thousand tokens became sixteen thousand, then a hundred and twenty-eight thousand, then a million, and a technical report describing context windows up to ten million tokens made the previous numbers feel quaint. The number is real and the engineering behind it is genuinely hard. The problem is not the number. The problem is the inference almost everyone draws from it on first contact.
The inference goes like this: *if the model can accept a million tokens, then I can put everything in, and the model will have everything it needs. * The first clause is true. The second does not follow from it. Between "the model can accept these tokens" and "the model will have what it needs" sit at least four separate questions, and a large window answers none of them. Will the model attend to the right part? Will it select that part as relevant over the louder, longer, more confident parts? Will the information still be true when it is read? And, the question this whole book turns on, will any of it survive into the next request, or does the system start from a blank slate every time?
A context window is a parameter of a single inference call. You assemble some tokens, the model runs a forward pass over them, it emits a response, and the tokens are gone. There is no drawer they fall into. The next call is independent unless your application explicitly reconstructs state and feeds it in again. This is the mechanical fact that the word "remembers" obscures every time it is used loosely. The model does not remember the last turn. Your code remembers the last turn, by storing the transcript and replaying it. The window is where replayed state is presented, not where it is kept.
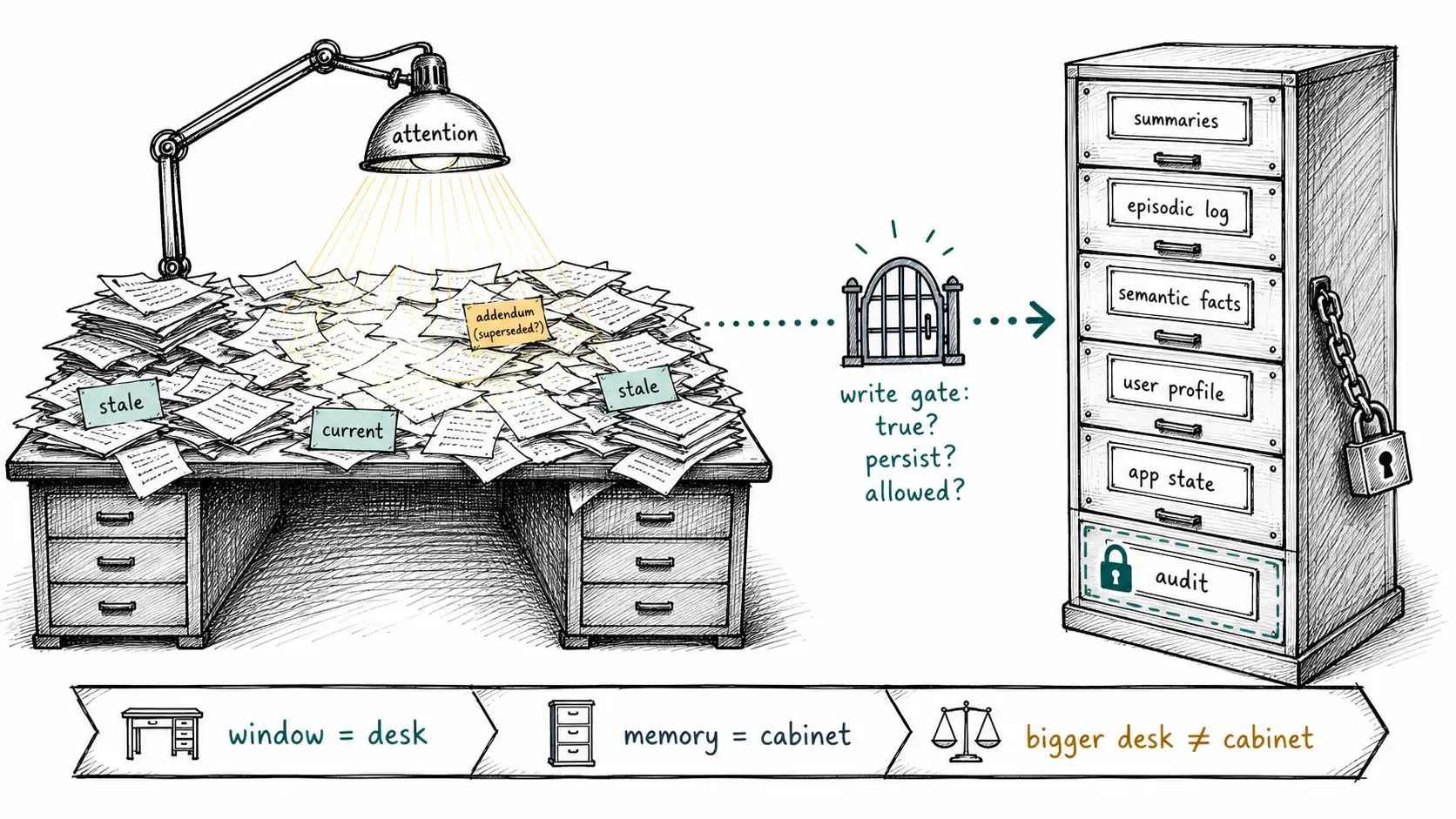
The desk, introduced properly
Picture a physical desk under a single small lamp. The desk is the context window. You can pile papers on it, a contract, three emails, a spreadsheet printout, a sticky note with the user's name. A bigger desk lets you pile more papers. That is the entire contribution of a larger context window: surface area.
The lamp is attention, and it is small. It illuminates the papers near the center of where you are working clearly, the edges adequately, and the deep middle of a tall stack poorly. We will make this precise in Chapter 5 with the Lost in the Middle research, but the intuition is already right: putting a paper on the desk does not guarantee the lamp falls on it.
And crucially, the desk is not the filing cabinet. the desk is cleared. Nothing on it is automatically filed. If a paper mattered, if it recorded a decision, a preference, a correction, a commitment, someone has to decide to file it, where to file it, who is allowed to see it later, when it expires, and whether it supersedes something already in the cabinet. The filing cabinet is memory. It is a different piece of furniture, in a different part of the room, with locks and labels and a retention policy. No amount of desk enlargement turns a desk into a filing cabinet. That sentence is the whole book compressed to one line, and the rest is elaboration and code.
What the window actually is, mechanically
It helps to be concrete about what gets passed in a single call, because "context" is used so loosely that people forget it is just an ordered sequence of tokens. A typical assembled prompt for a production assistant contains, in some order:
- a system instruction defining role and constraints,
- task instructions for the current operation,
- the user's current query,
- some retrieved documents or passages,
- some conversation history from prior turns,
- possibly tool or function outputs from earlier in this turn,
- a safety or policy block,
- an output-format specification.
All of it is concatenated into one sequence, tokenized, and run through the model once. The model has no idea which bytes came from a trusted system author and which came from an untrusted user message, except insofar as your formatting and the model's training give it hints. It has no notion that the retrieved document is "evidence" and the conversation history is "context" and the policy is "rules", those are your categories, enforced by your assembly logic, not properties the window understands. The window is flat. Meaning and trust and recency are things a system imposes on a flat sequence. The window will not impose them for you, and a larger window imposes them even less, because there is more flat sequence to get lost in.
Five things teams stop building when they believe the mirage
The mirage is costly not because long context is bad, but because believing in it as memory causes teams to delete or never build the components that actually provide reliability. Here is the recurring pattern.
| Component skipped | The mirage's excuse | What breaks in production |
|---|---|---|
| Retrieval / indexing | "Everything fits, so why rank it?" | Model answers from the wrong document among many; cannot find the current version; cost scales with corpus, not with relevance. |
| A write gate for memory | "The window is the memory." | Nothing persists across sessions; users repeat themselves; or everything persists and the store fills with junk and contradictions. |
| Provenance tracking | "The text is right there in the prompt." | When the answer is wrong, no one can say which source produced it; summaries lose their origin. |
| Permission boundaries | "It's all in one prompt anyway." | One user's state leaks into another's session; deprecated or restricted documents are quoted as authority. |
| Freshness / supersession | "The latest doc is in there somewhere." | The policy-team failure: obsolete text out-argues the current addendum because nothing marks it as superseded. |
Every row is a real incident pattern, and every one of them is invisible in a demo. A demo uses one clean, current, authorized document and asks one well-posed question. Production uses six hundred documents of varying age and authority, asks ambiguous questions, runs across many users, and is legally obligated to forget some things on request. The components in that table are how you survive the gap. The mirage tells you they are obsolete. They are not; the window simply made them optional to skip and easy to regret.
A concrete reconstruction of the failure
Return to the policy team from the introduction and look at it as a system, not a story. Their pipeline, stripped to essentials, was this:
def answer(question: str) -> str:
# The entire corpus, concatenated once at startup.
corpus = load_all_policy_documents() # ~580k tokens
prompt = (
"Answer using only the policy below.\n\n"
f"{corpus}\n\n"
f"Question: {question}"
)
return model.complete(prompt)Read against the five-question test, the design fails four of them before the model is even invoked:
- Attended to? No control. The current addendum sits wherever it happened to land in concatenation order, here, the middle, the worst place.
- Selected? No control. The model weighs a long, detailed, confident exclusion clause against a short addendum and picks the louder one.
- Trusted / current? No signal at all. Nothing in the prompt tells the model that document A supersedes document B. They are peers in a flat sequence.
- Remembered? Irrelevant by design. There is no persistence, so a correction an analyst makes today is gone tomorrow.
Contrast with a version that treats the window as a desk and builds the missing furniture around it:
def answer(question: str, user_scope: str) -> Answer:
# Retrieve only passages the user is allowed to see, current versions only.
passages = retrieve(
question,
scope=user_scope,
only_current=True, # supersession enforced here, not hoped for
k=8,)
if not passages:
return Answer(text="No current, authorized policy covers this.",
abstained=True)
# Order by relevance, tag each with source + version + effective date.
context = render_with_provenance(passages)
prompt = build_prompt(question, context, instruct="Cite the source id for each claim.")
draft = model.complete(prompt)
return verify_citations(draft, passages) # claims must map to a passageThe model is the same. The window is the same size or smaller. The difference is entirely in the system around the window: retrieval enforces permission and currency, provenance makes the answer auditable, the abstention path handles "no good evidence, " and citation verification catches the model when it wanders. None of this is exotic. All of it is exactly what the mirage tells you that you no longer need.
"It fits" is the wrong success criterion
The deepest damage the mirage does is to the definition of success. When a team's mental model is "fit everything in, " the milestone becomes the corpus fits in the window, and that milestone is reached the day the context limit clears the document size. It feels like an achievement. It measures nothing about reliability.
The right criteria are different and harder:
- Does the system retrieve the relevant and current material, not merely all material?
- When evidence is insufficient, does the system abstain instead of inventing?
- Can you trace any answer back to the specific source that produced it?
- Are permission boundaries enforced before retrieval and before any action?
- Does anything worth keeping actually persist, with consent and expiry, and can it be deleted on request?
Notice that a million-token window helps with exactly none of these directly. It enlarges the desk. The criteria are about the filing cabinet, the lamp, the labels, and the locks. We will spend the rest of the book building those.
What this chapter changes about how you build
If you take one operating habit from this chapter, make it this: stop measuring whether content fits, and start measuring whether content is selected, trusted, current, and, separately, retained. The window's size is a budget, not a strategy. Treating it as a strategy is how the policy team shipped a confidently wrong answer two weeks after a flawless demo.
The next chapter sharpens the vocabulary that this one leaned on. We used six words, included, attended to, selected, trusted, current, remembered, as if their differences were obvious. They are not, and the gaps between them are where systems fail. Chapter 2 takes them one at a time.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
A large context window increases surface area, not understanding and not persistence. It is a desk, not a filing cabinet. The headline token number invites a false inference, that fitting everything in means the model has everything it needs, but four independent questions sit in that gap: will the model attend to the right part, select it over louder distractors, trust the right version as current, and retain anything afterward. Believing the mirage causes teams to delete the very components (retrieval, write gates, provenance, permissions, freshness) that provide reliability, and those failures are invisible in demos and expensive in production. The fix is not a smaller window or a bigger one; it is building the furniture around the desk and changing the definition of success from "it fits" to "it is selected, trusted, current, and correctly retained", a design discipline grounded in how context windows actually behave and what prompt caching and long-context APIs can and cannot provide.
Six Words That Are Not Synonyms sharpens the vocabulary this chapter leaned on, turning the desk/archive intuition into six precisely-named, separately-failing states.