Introduction: The Sentence in the Middle
A team I will call the policy team, the details are composited from several real projects, but the shape is exact, had a problem that sounded like a solved problem. They ran compliance support for a mid-sized insurer.

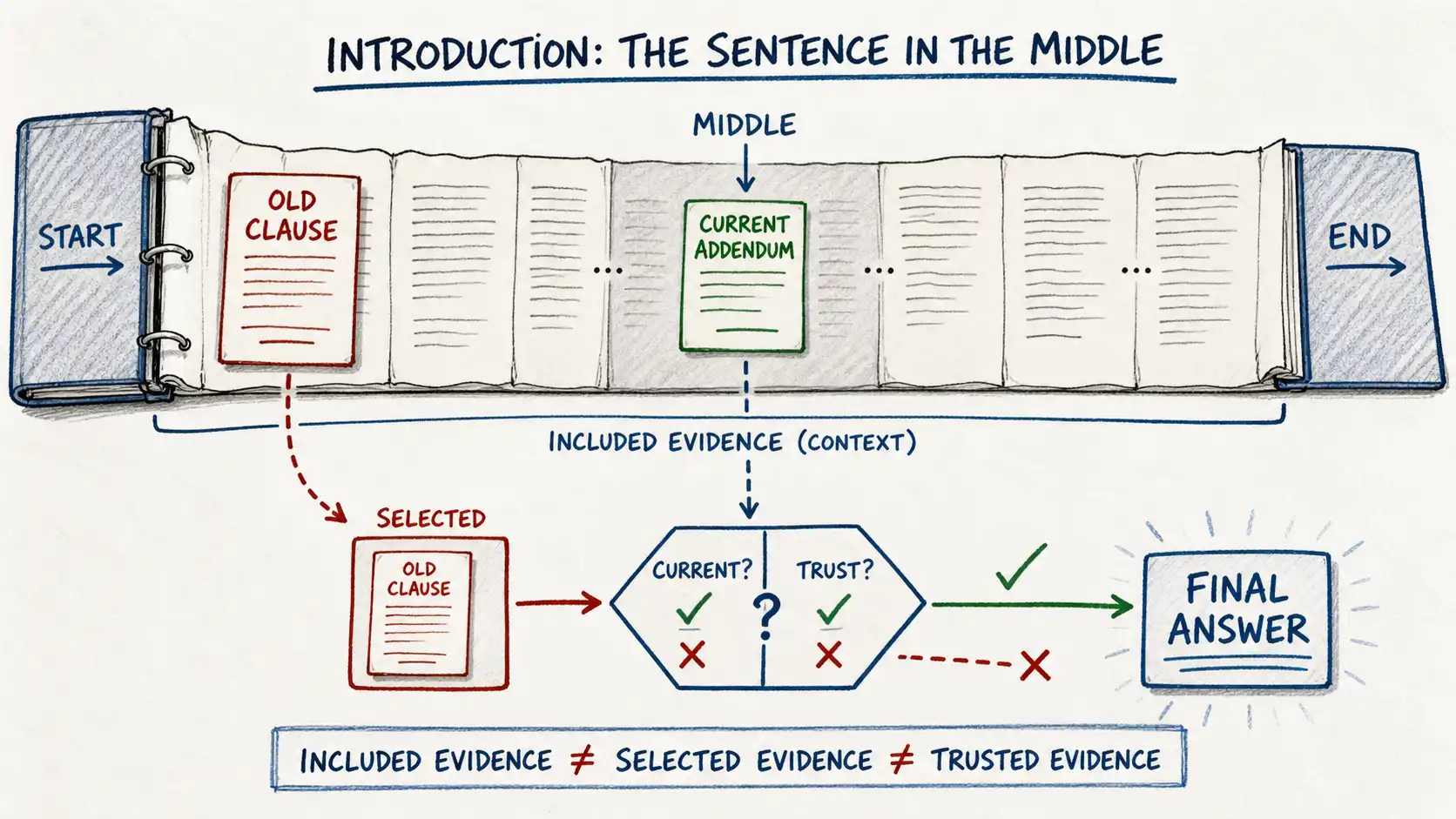
The sentence in the middle is the warning label for long context: information can be present in the prompt and still fail to influence the answer when attention, ordering, and relevance are wrong.
A team I will call the policy team, the details are composited from several real projects, but the shape is exact, had a problem that sounded like a solved problem. They ran compliance support for a mid-sized insurer. When a customer or an internal agent asked a question, the answer lived somewhere in roughly six hundred pages of underwriting policy, regulatory addenda, and internal memos. The documents changed. The answer for a given question last quarter was sometimes the wrong answer this quarter.
When long-context models arrived with windows large enough to swallow the entire binder, the team felt the relief of a deadline lifting. The old system had been a fragile retrieval pipeline: chunking, embeddings, a vector store, a reranker, a dozen knobs that all had to be tuned together. Now they could delete most of it. They concatenated every document into one enormous prompt, prepended the instruction "Answer using only the policy below, " appended the user's question, and sent it to the model. The first demo was glorious. Someone asked a question that would have taken a human analyst twenty minutes to chase across four documents, and the model answered in nine seconds, correctly, with a quotation.
The system went to a limited pilot. Within two weeks it produced an answer that was confidently, specifically wrong. A customer had asked about coverage for a particular category of water damage. The model quoted a policy paragraph verbatim and explained the exclusion clearly. The paragraph was real. It was also superseded, there was an addendum, dated four months earlier, that reversed the exclusion for that category. The addendum was in the prompt. It had been concatenated along with everything else. The model had been given the current truth and the obsolete truth in the same breath, and it answered from the obsolete one because the obsolete one was longer, more detailed, more confidently worded, and sat near the middle of the document where, as we will see, models attend least reliably.
Nobody had lied to the model. Nobody had withheld the right answer. The right answer was included. It simply was not selected, not trusted, and the system had no concept of current. The model had read everything and remembered nothing, because reading is not remembering, and a window is not a memory.
That gap, between what is present in a prompt and what a system actually knows, trusts, and carries forward, is the subject of this book.
Key Takeaways
- Passing more text is not the same as preserving the right evidence at the point of decision.
- The middle of a long prompt is where important facts often become technically present but operationally weak.
- A context assembler must choose, order, compress, and prove context rather than dumping the archive into the window.
Why this confusion is so easy to fall into
The confusion is not a sign of a careless team. It is the predictable result of a real and impressive capability arriving faster than the vocabulary to reason about it. When a vendor announces a million-token context window, the headline number invites a specific, wrong inference: that the window is a place where information lives. It is not. The window is the working set for a single forward pass. It is assembled, consumed, and discarded. The next request starts from nothing unless something outside the model deliberately reconstructs the state.
We have words for the things a window is not, retrieval, indexing, caching, state, persistence, governance, but in casual usage these words collapse into one another."The model remembers our conversation" usually means "our application replays the transcript into the prompt each turn." "The model knows our docs" usually means "we retrieve and inject relevant passages." "The model learned my preference" usually means "we stored a row in a table and re-inject it." None of these are the model remembering anything. They are an application doing the work and crediting the model.
This matters because the moment you credit the model with memory it does not have, you stop building the parts of the system that actually provide it. You skip the write gate that decides whether a stated fact deserves to persist. You skip the retrieval layer that finds the current addendum instead of relying on the model to notice it among six hundred pages. You skip the policy boundary that prevents one user's stored state from surfacing in another's prompt. You skip the deletion path that a privacy regulation will eventually require you to have. The mirage of memory is expensive precisely because it makes the real work look unnecessary.
What this book argues
The argument has five movements, and they build on each other.
The misunderstanding comes first. We separate six words that get used as synonyms and are not: included, attended to, selected, trusted, current, and remembered. A piece of information can be included in a prompt and never attended to. It can be attended to and not selected as relevant. It can be selected and not trusted. It can be trusted and not current. And none of that has anything to do with whether it is remembered for tomorrow. Most long-context failures are a slippage between two of these words, and naming them precisely is the first defense.
How long context actually behaves comes second. We look at what the research and the production telemetry agree on: that models attend unevenly across position, that they degrade on tasks more demanding than simple recall, that passing a needle-in-a-haystack test predicts very little about real multi-document reasoning, and that every token you add carries a cost in latency, money, and, counterintuitively, accuracy, because irrelevant context is not free, it is confusing.
Memory is a system is the heart of the book. We define memory types precisely, short-term context, conversation history, summaries, episodic memory, semantic memory, user-profile memory, procedural memory, application state, external knowledge, and audit state, and we treat memory as something a system writes and reads through gates, with schemas, consent, provenance, confidence, and expiry. The borrowed metaphors from operating systems and databases are useful here, and we will use them carefully, without pretending an LLM's memory is the same thing as a page table.
Context engineering as a discipline comes fourth. This is where the book turns constructive. Instead of dumping content into a prompt, you assemble it from components under a budget: system instructions, task instructions, the user query, retrieved evidence, durable memory, tool results, constraints, and an output schema, each with a priority and a token allocation. We will build a context assembler, a budget allocator, a provenance-preserving summary object, and a conflict-resolution routine that refuses to silently merge contradictory facts.
Evaluation and production readiness closes the book. A long-context or memory system that cannot be measured cannot be trusted, and demos systematically overestimate reliability. We build positional evals, multi-hop evals, stateful conversation evals, memory write/read evals, memory-poisoning tests, deletion tests, and a monitoring schema, and we write the runbook for the incident you will eventually have: the agent acted on stale memory.
How to read this book
It is written to be read in order, because the movements build, but it is also written so that an engineer in the middle of a specific fire can open to the relevant chapter and find a usable artifact: a schema, a function, a decision table, an eval harness, a runbook. The code is deliberately about context and memory infrastructure, token budgets, write gates, provenance merges, deletion, and not about generic chatbot plumbing. Every code example is chosen to demonstrate the difference between temporary context and durable memory, because that difference is the whole point.
Throughout, the tone is skeptical without being cynical. Long context is a genuine advance. Prompt caching makes large stable contexts economically reasonable in ways they were not two years ago. Retrieval and long context are increasingly complementary rather than competing. The skepticism is aimed not at the capability but at the story told about the capability, the story that says the hard parts of building reliable systems have been abstracted away. They have not. They have moved.
A demo only needs a good answer once. A product needs a defensible answer repeatedly, under messy input, stale documents, adversarial text, multilingual content, budget pressure, long sessions, changing policies, and operational drift. The policy team's system gave a good answer once, in the demo, and a dangerous one in week two. The rest of this book is about the difference.
Turn the page. The desk is covered in papers, the lamp is small, and somewhere in the middle there is a sentence that matters.
The Million-Token Mirage names and dissects the specific belief this introduction surfaced, that a bigger window means the hard parts are solved.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.