Tokens, Windows, and the Shape of Attention
> **Working claim:** You cannot reason about long-context behavior without a working model of three things: what a token is, what the window actually bounds, and why attention is a finite resource spread unevenly across a sequence.

Tokens are the budget, windows are the container, and attention is the uneven mechanism that decides which parts of the container matter during generation.
Working claim: You cannot reason about long-context behavior without a working model of three things: what a token is, what the window actually bounds, and why attention is a finite resource spread unevenly across a sequence. None of this requires Transformer math. All of it requires refusing the fiction that the model "reads" a prompt the way a person reads a page.
Key Takeaways
- A context window is not a database; it is a bounded working surface with positional and attention effects.
- Token budgeting should follow decision value, not document length or convenience.
- The shape of attention is why ordering, repetition, summaries, and evidence placement belong in architecture.
Why a builder needs this layer
This is the one mechanism chapter in the book, and it earns its place because every operational decision downstream, budgets, caching, positioning, the choice between long context and retrieval, rests on three facts about how a model consumes input. The goal is not to make you a Transformer researcher. It is to replace a misleading intuition ("the model reads my prompt and understands it") with an accurate one ("the model runs a bounded, position-aware, attention-weighted computation over a sequence of tokens, once"). With the accurate intuition, the rest of Movement II stops being surprising.
We will build it in three steps: the token (the unit), the window (the bound), and attention (the mechanism that makes position matter). Each step ends with a consequence you will use later.
Step one: the token, and why your word count lies
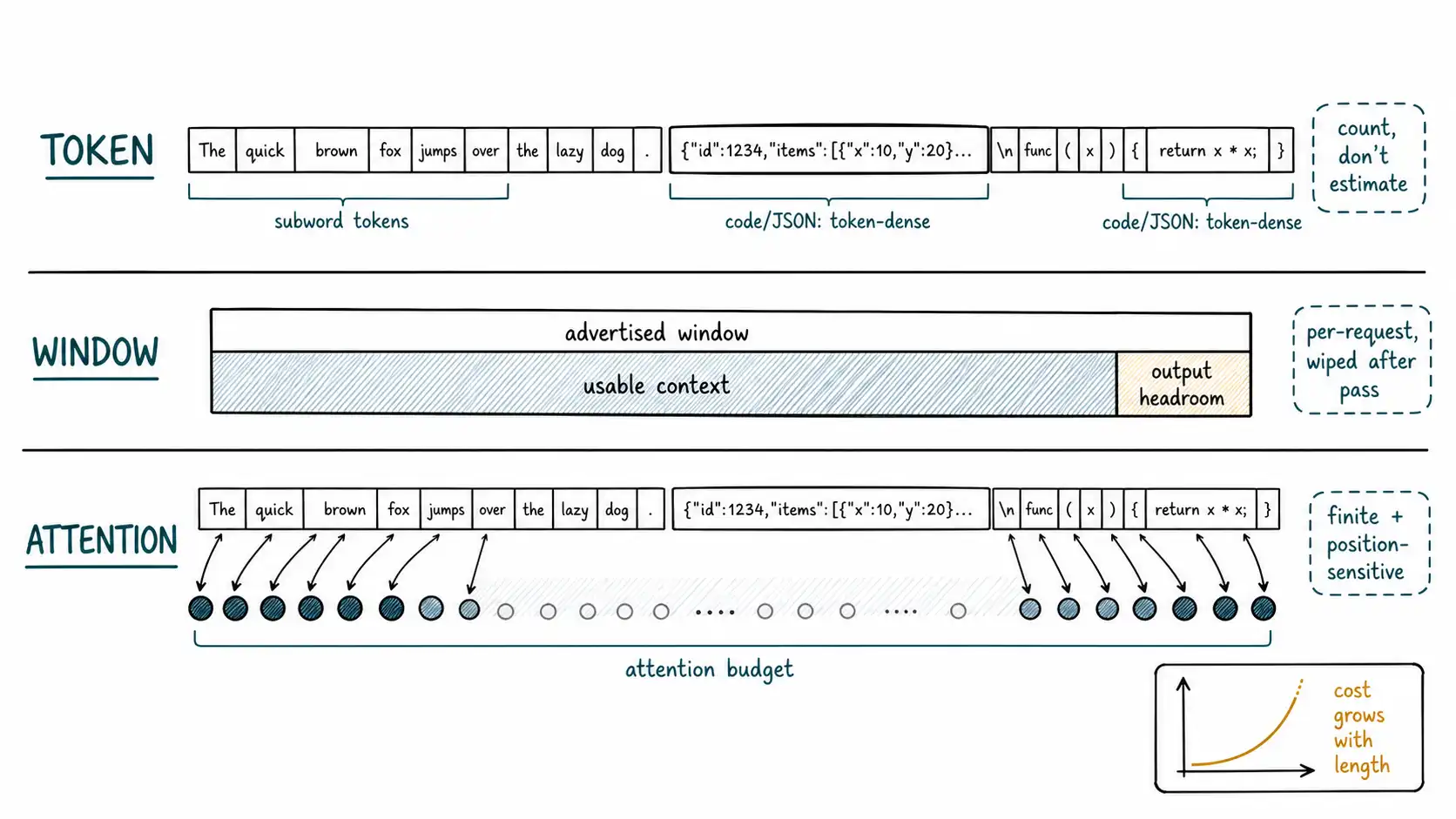
Models do not see characters or words. They see tokens, subword units produced by a tokenizer that was trained to compress text into a vocabulary of typically tens of thousands of pieces. Common words are often a single token; rare words, code, URLs, and non-English text fragment into many. The mapping is learned and somewhat arbitrary, which has direct, practical consequences that bite teams who reason in "words" or "characters."
A few realities worth internalizing:
- Tokens are not words. A rough English rule of thumb is ~0.75 words per token, or ~4 characters per token, but it is only a rule of thumb. Code, JSON, and structured data are token-dense; a tidy-looking config block can cost far more tokens than its character count suggests.
- Non-English text is more expensive. Many tokenizers fragment non-Latin scripts heavily, so the same meaning in another language can cost two or three times the tokens. A multilingual product silently pays this, and a budget computed on English samples under-provisions for everyone else.
- Token counts are tokenizer-specific. The count for the same string differs across model families. You must count with the target model's tokenizer, not an approximation, if budgets are tight. The OpenAI tiktoken library and the Hugging Face tokenizers documentation are the practical references for measuring this correctly across the two dominant model families.
The operational consequence is simple and non-negotiable: measure tokens, do not estimate them. Any budget logic, cost model, or truncation decision built on a character-count approximation will be wrong by enough to matter at the margins, and the margins are exactly where truncation silently drops your golden fact.
import tiktoken
def count_tokens(text: str, model: str = "gpt-4o") -> int:
enc = tiktoken.encoding_for_model(model)
return len(enc.encode(text))
# The point: the same "size" in characters is wildly different in tokens.
samples = {
"prose_en": "The return window is thirty days from delivery.",
"json_blob": '{"return_window_days":30,"effective":"2026-02-01","supersedes":"R-114"}',
"code": "for i in range(len(xs)):\n acc += xs[i] * w[i]\n",}
for name, s in samples.items():
print(f"{name:10s} chars={len(s):3d} tokens={count_tokens(s):3d}")
# Structured/code strings cost far more tokens per character than prose.When a vendor advertises a context window, that number is in tokens, and so is your bill. Reasoning in words is how teams are surprised by both.
Step two: the window, and what it actually bounds
The context window is the maximum number of tokens the model will process in a single forward pass, and, critically, it is usually a bound on input plus output combined, not input alone. If a model has a 200k-token window and you fill 199k with input, you have left almost nothing for the response, and the model will be cut off mid-answer. Budgeting must reserve output headroom; this is a common and embarrassing production bug.
Two properties of the window matter more than its raw size:
First, the window is per-request and stateless. We established this in Chapter 1, but it bears repeating in mechanical terms: the window does not carry information between calls. There is no hidden buffer that remembers the previous prompt. Each request reconstructs everything from scratch. The model's parameters are fixed (that is where training "knowledge" lives); the window is the only channel for request-specific information, and it is wiped after each pass.
Second, the advertised window is a physical bound, not a usable one. A model rated for a million tokens does not reason equally well across all million. The usable capacity, the length over which the model maintains reliable retrieval, selection, and multi-hop reasoning, is typically much shorter, and it depends on the task. We will see the evidence for this in Chapters 5 and 6. For now, hold the distinction the way you hold the difference between a truck's cargo volume and the weight it can legally carry: the bigger number is real, and it is not the number that governs whether the trip is safe. The Anthropic context windows guide and the Google Gemini long-context documentation both address this physical-vs-usable distinction and offer practical recommendations for staying within the reliable range.
| Window concept | What it is | What it is not |
|---|---|---|
| Advertised size | Max tokens per forward pass (often input+output) | A guarantee of equal reasoning across that span |
| Input budget | Window minus reserved output headroom | The whole window |
| Usable context | Span over which the task stays reliable | Equal to the advertised size |
| Per-request scope | Reconstructed every call | A persistent buffer between calls |
Step three: attention, the finite resource
Here is the mechanism that makes "the model reads my prompt" a fiction worth dropping. The Transformer architecture, introduced in Attention Is All You Need, processes a sequence by letting each position compute a weighted combination of all other positions, the attention mechanism. The weights are learned and input-dependent. The essential point for a builder, stated without the matrix algebra, is this: attention is a budget that gets distributed across the sequence, and the distribution is neither uniform nor under your direct control.
Three consequences follow, and they are the spine of everything in Movement II:
-
Attention is finite and shared. When the model decides how much each token contributes to producing the next token, it is dividing a fixed pool of attention across the whole sequence. Add a thousand irrelevant tokens and you have not added attention; you have spread the same attention thinner, and given it more places to land wrongly. This is the mechanical root of context pollution (Chapter 7): more context can mean less attention per relevant token.
-
Position influences attention. Models encode the position of each token (through positional schemes baked into the architecture), and empirically they do not attend equally across positions. The lost in the middle phenomenon, which Chapter 5 dissects, is the most studied instance: information at the start and end of a long context is used more reliably than information in the middle. Position is therefore a lever you control through ordering, and ignoring it leaves accuracy on the table.
-
Cost grows superlinearly with length. The original self-attention computation scales with the square of sequence length, because every position attends to every other. Production systems use optimized and approximate attention variants, surveyed in Efficient Transformers, to soften this, but the directional fact survives: long inputs are disproportionately expensive to process, which is why latency and cost climb with context length (Chapter 7) and why caching the stable prefix matters so much.
You do not need to know which attention variant a given model uses. You need to know that attention is finite, position-sensitive, and length-expensive, three facts that turn the abstract "use the window wisely" into concrete levers: *include less, order deliberately, cache the stable part. *
What "the model reads it" actually means
With the three steps in place, we can state precisely what happens when you "send a prompt." Your application assembles an ordered token sequence within the window's input budget. The model runs a single forward pass: every token's representation is refined by attending, with learned and position-influenced weights, to the others; the finite attention pool is distributed across the whole sequence; and the model emits output tokens one at a time, each conditioned on everything before it. Then it stops, and the sequence is discarded.
Nowhere in that process is there "reading" in the human sense, no eyes moving deliberately to the relevant clause, no re-reading the part that matters, no flagging "this is the current version, ignore the old one." There is a weighted, position-sensitive, one-pass computation. When the relevant clause sits in an attention-poor position, drowned among distractors that pull weight away from it, the model does not "miss" it the way a careless reader misses a line. It assigns it low weight, mechanically, and produces output dominated by whatever got the weight instead. Understanding this is the difference between blaming the model ("it's dumb") and fixing the system ("the clause was in the attention-poor middle, competing with three distractors, in a prompt twice as long as it needed to be").
The three levers, named
This chapter exists to hand you three levers that the rest of Movement II and IV will pull repeatedly. State them explicitly so they are easy to reach for:
- Lever 1: Include less. Because attention is finite and shared, fewer relevant tokens beat many mostly-irrelevant ones. Curation (Chapter 3) is not just about cost; it is about concentrating attention.
- Lever 2: Order deliberately. Because position influences attention, where you place the relevant material changes whether it is used. Put the most important evidence and instructions where attention is strongest (Chapter 5 makes this precise).
- Lever 3: Cache the stable prefix. Because long inputs are expensive, and because much of a production prompt (system instructions, schema, policy) is identical across requests, prompt caching lets you avoid re-paying for the stable part (Chapter 7 builds the cost model).
These three levers are the entire practical payoff of understanding the mechanism. You do not tune attention directly. You tune what you put in, in what order, and what you reuse, and those moves work because of how tokens, windows, and attention behave.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
A builder needs an accurate, math-free model of three things. The token is the model's unit of input; it is not a word, it is tokenizer-specific, it is denser for code and non-English text, and it must be measured rather than estimated because budgets and bills are denominated in tokens. The window is the per-request bound on tokens, usually input plus output combined, that is reconstructed from scratch every call and whose advertised size is a physical bound, not the much smaller usable capacity.Attention is a finite resource distributed unevenly and position-sensitively across the whole sequence, with cost that grows superlinearly in length; this is why irrelevant context dilutes attention, why position matters, and why long inputs are expensive. Together these facts replace the fiction that the model "reads" a prompt with the reality of a one-pass, weighted, position-aware computation, and they yield three concrete levers used throughout the book: include less, order deliberately, and cache the stable prefix.
Lost in the Middle puts the position-sensitivity mechanism under empirical scrutiny, quantifying exactly how the U-shaped attention curve degrades real task performance, not just benchmark recalls.