The Memory Write Gate
> **Working claim:** The most dangerous moment in a memory system is the *write*. Reading the wrong memory produces a bad answer; writing the wrong memory produces bad answers indefinitely, for everyone, until someone finds and deletes it.

The memory write gate decides whether a candidate fact is true enough, durable enough, allowed enough, and useful enough to persist beyond the current interaction.
Working claim: The most dangerous moment in a memory system is the write. Reading the wrong memory produces a bad answer; writing the wrong memory produces bad answers indefinitely, for everyone, until someone finds and deletes it. Every durable memory must pass a gate that answers three questions before it persists: Is it true? Should it persist? Is it allowed?
Key Takeaways
- The safest memory policy starts with default-do-not-persist, then admits facts through explicit tests.
- A write gate needs evidence, consent, scope, lifetime, confidence, and revocation fields before a fact becomes durable.
- Without a write gate, personalization turns into accidental surveillance and stale behavior.
Why writes are asymmetrically dangerous
A read error is local and transient: a bad recall pollutes one answer, and the next request might recall correctly. A write error is global and persistent: a false or unauthorized fact, once written, is recalled into every future relevant request until it is detected and removed. If the false fact is plausible and confidently stated, it may never be detected, it just quietly steers answers wrong for months. And if the write captured data the user never consented to persist, you have not made a quality mistake; you have made a compliance one, with deletion obligations under regimes like GDPR's right to erasure.
This asymmetry should govern the design. Be liberal about what you read (you can filter and rank), and conservative about what you write (every persisted fact is a long-term liability). The write gate exists to enforce that conservatism. The default disposition of the gate is do not persist, a candidate fact must earn persistence by clearing all three questions, not merely by having been mentioned.
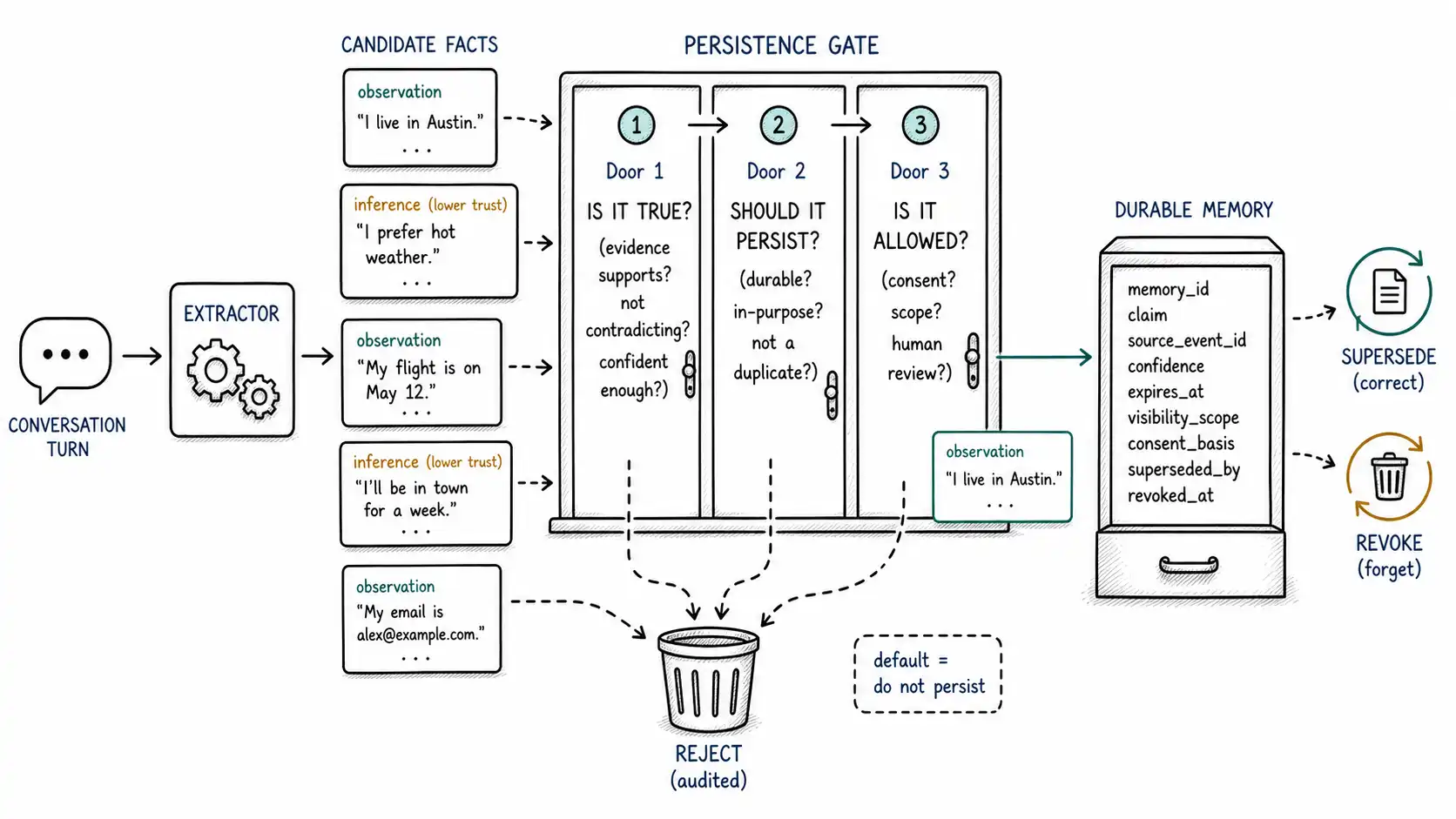
Candidate facts vs. durable memories
The first structural move is to refuse the shortcut of writing whatever the model extracts directly into the store. There are two distinct objects:
- A candidate fact is something the system noticed in a turn: "the user said they prefer email." It is provisional, untrusted, and cheap. The extractor produces many of them, including noise.
- A durable memory is a candidate that has passed the gate, verified enough, worth keeping, and permitted. It is what gets written, recalled, and acted upon.
Collapsing these two, writing every extracted candidate straight to durable memory, is how memory stores fill with contradictions, transient asides ("I'm in a rush today"), misheard intentions, and things the user explicitly did not want kept. The extractor's job is to propose; the gate's job is to dispose.
from dataclasses import dataclass
from typing import Optional
@dataclass
class CandidateFact:
subject: str # who/what the claim is about, e.g."user:8831"
claim: str # the proposed durable statement
category: str # "preference" | "attribute" | "event" | "commitment" | ...
source_event_id: str # the turn/episode this came from - provenance
evidence_span: str # the exact text that justified it
extractor_confidence: floatThe durable memory schema
A durable memory is not a string; it is a governed record. The fields below are the minimum for a store you can trust, correct, audit, and delete from. Each field exists to answer a question someone will eventually ask.
CREATE TABLE durable_memory (
memory_id TEXT PRIMARY KEY, -- stable id for update/delete/audit
subject TEXT NOT NULL, -- who/what it is about (scoped key)
claim TEXT NOT NULL, -- the durable statement itself
category TEXT NOT NULL, -- preference | attribute | event | ...
source_event_id TEXT NOT NULL, -- provenance: the originating episode
evidence_span TEXT, -- the text that justified it
confidence REAL NOT NULL, -- calibrated belief, not raw model logit
created_at TIMESTAMPTZ NOT NULL,
last_confirmed_at TIMESTAMPTZ, -- when last re-observed / verified
expires_at TIMESTAMPTZ, -- soft TTL; null = no expiry
visibility_scope TEXT NOT NULL, -- which users/sessions may recall it
consent_basis TEXT NOT NULL, -- why we are allowed to keep it
superseded_by TEXT REFERENCES durable_memory(memory_id), -- correction chain
revoked_at TIMESTAMPTZ -- soft delete; recall must exclude
);A few fields carry more weight than they look:
source_event_idandevidence_spanmake every memory traceable. When a recalled memory produces a wrong answer, you can find the exact turn and text that created it. A memory without provenance is a rumor; you cannot correct what you cannot trace.confidenceshould be a calibrated belief, not a raw model score."The model was 0.9 sure" is meaningless unless 0.9-confidence claims are actually right ~90% of the time (calibration is covered in Embeddings, Honestly and revisited for memory in Chapter 13).last_confirmed_atvs.created_atseparates when a fact was first learned from when it was last seen to still hold, the basis for decay and re-confirmation (Chapter 10).expires_atencodes that many "facts" are temporary."Working on the Q2 migration" should not be recalled in Q4. A memory with no natural expiry should be the exception, set deliberately.superseded_byandrevoked_atare the correction and deletion machinery. Memories are never hard-deleted in place during normal operation, they are superseded (replaced by a corrected version, chain preserved) or revoked (soft-deleted, excluded from recall). This preserves the audit trail while ensuring the bad memory stops influencing answers. Hard deletion is reserved for honoring erasure requests, and even then the audit log records that a deletion occurred.
The three gates
Now the gate itself. A candidate fact must clear three independent checks, in order. Failing any one means do not persist, and for some failures, escalate to human review rather than silently drop.
Gate 1: Is it true? (verification)
The extractor's confidence is necessary but not sufficient. The truth gate asks whether the claim is supportable and non-contradictory:
- Does the
evidence_spanactually support theclaim, or did the extractor over-generalize ("I used email today" → "prefers email")? - Does it contradict an existing high-confidence memory? A contradiction is not automatically a rejection, it may be an update (the user changed their mind), but it must be routed to conflict resolution (Chapter 12), never silently written alongside the contradicting fact.
- Is the confidence above the category's threshold? High-stakes categories (a commitment, a financial detail) demand higher confidence than low-stakes ones (a UI color preference).
Gate 2: Should it persist? (durability)
Many true things should not be remembered. This gate filters for durability and value:
- Is this transient ("in a rush today") or durable ("works in the Tokyo office")? Transient facts get a short or zero TTL or are dropped.
- Is it within scope of what this product should remember at all? A support assistant probably should not persist a customer's offhand political opinion even if true and durable, it is out of purpose.
- Does it duplicate an existing memory? If so, confirm the existing one (bump
last_confirmed_at, raise confidence) rather than writing a second copy.
Gate 3: Is it allowed? (consent and policy)
The compliance gate, and the one with legal teeth:
- Is there a lawful, recorded
consent_basisfor persisting this about this person? Some categories (special-category personal data) may be prohibited from storage entirely. - Does
visibility_scopecorrectly restrict who can recall it? A fact learned in one user's session must never default to a scope that lets another user recall it, the cross-user leak from Chapter 1's table. - For high-risk systems or sensitive categories, does policy require human review before this persists? In regulated settings, some memory writes should queue for approval rather than auto-commit.
def memory_write_gate(cand: CandidateFact, ctx: WriteContext) -> WriteDecision:
# Default disposition: reject.
# Gate 1 - Is it true?
if not evidence_supports(cand.claim, cand.evidence_span):
return WriteDecision.reject("evidence_does_not_support_claim")
if cand.extractor_confidence < threshold_for(cand.category):
return WriteDecision.reject("below_confidence_threshold")
conflict = find_conflicting_memory(cand.subject, cand.claim, ctx.store)
if conflict:
return WriteDecision.resolve_conflict(conflict) # -> Chapter 12
# Gate 2 - Should it persist?
if is_transient(cand.claim, cand.category):
return WriteDecision.write(ttl=short_ttl(cand.category))
if duplicate:= find_duplicate(cand, ctx.store):
return WriteDecision.confirm(duplicate.memory_id) # bump, don't duplicate
if not within_product_purpose(cand.category, ctx.product_policy):
return WriteDecision.reject("out_of_purpose")
# Gate 3 - Is it allowed?
consent = lookup_consent(ctx.user_id, cand.category)
if not consent.permits_storage:
return WriteDecision.reject("no_consent_basis")
if cand.category in ctx.policy.human_review_categories:
return WriteDecision.queue_for_review(cand)
return WriteDecision.write(
scope=consent.visibility_scope,
consent_basis=consent.basis,
ttl=natural_ttl(cand.category),)Every branch, including every rejection, writes an audit row. Why a memory was not written is as important to an incident reconstruction as why one was.
Extraction without over-extraction
The gate is only as good as the candidates it receives, and the failure mode on the extraction side is over-extraction: the model, asked to "extract durable facts, " will happily invent generalizations from thin evidence, because that is what models do. Two disciplines tame it.
First, make the extractor cite its evidence and stay literal. Force it to output, for each candidate, the exact span that justifies it and a claim that does not exceed that span. An extractor that must quote its source over-generalizes far less, and the evidence_span it produces is exactly what Gate 1 checks.
Second, separate observation from inference, and persist them differently. "The user clicked the email option" is an observation, high-trust, episodic, near-certain."The user prefers email" is an inference, lower-trust, semantic, revisable. Writing an inference with the confidence of an observation is how systems become confidently wrong about people. Store the observation as an immutable episode (Chapter 8); let the semantic inference be a separate, lower-confidence, revisable memory that points back to the episodes supporting it.
def extract_candidates(turn: Turn) -> list[CandidateFact]:
raw = model.extract(
turn.text,
instruction=(
"Extract durable facts about the user. For EACH, output the exact "
"quoted span that justifies it. Do NOT generalize beyond the span."
"Mark each as 'observation' (stated/done) or 'inference' (deduced)."
),
schema=CANDIDATE_SCHEMA,)
out = []
for c in raw:
if c.kind == "inference":
c.extractor_confidence *= 0.6 # inferences start less trusted
c.category = c.category + ":inferred"
out.append(c)
return outUpdates, supersession, and the right to be forgotten
Writing is not only creation; it is correction and deletion, and a write gate that cannot do those is incomplete.
Correction happens when a new candidate contradicts an existing memory and conflict resolution decides the new one wins. The episodic-to-semantic flow that underpins the whole architecture was made concrete by Generative Agents, MemoryBank, and MemGPT, each of which treats correction and supersession as first-class operations rather than afterthoughts. The old memory is not edited in place, it is marked superseded_by the new memory's id, and the new memory records what it replaced. Recall returns only the current head of the chain, but the history remains for audit. This is the event-sourcing discipline from Chapter 8 applied to facts: you never lose the record that the belief changed, only stop acting on the old belief.
Erasure happens when a user exercises a deletion right or withdraws consent. The relevant memories are revoked_at-stamped and excluded from all recall immediately; depending on policy and law, they are then hard-deleted on a schedule, with the audit log recording that erasure occurred (the audit record of a deletion is generally permissible and necessary even when the data itself must go). The reason memories are soft-deletable by design, the revoked_at field existing from day one, is that retrofitting deletion into a store that only ever appended is a migration nightmare, and "we cannot delete it" is not an acceptable answer to a regulator, or to the Govern and Manage functions of the NIST AI Risk Management Framework. Build the deletion path before you need it.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
Writes are asymmetrically dangerous: a read error pollutes one answer, a write error pollutes every future relevant answer indefinitely and can create a compliance liability. So be liberal about reads and conservative about writes, with the gate's default being do not persist. Separate candidate facts (provisional things the extractor noticed) from durable memories (candidates that passed the gate), and store durable memories as governed records, not strings, with provenance (source_event_id, evidence_span), calibrated confidence, created_at/last_confirmed_at/expires_at, visibility_scope, consent_basis, and the correction/deletion machinery (superseded_by, revoked_at). Every candidate clears three gates in order: Is it true? (evidence supports the claim, no silent contradiction, above category confidence threshold), Should it persist? (durable not transient, in product purpose, not a duplicate, confirm instead), and Is it allowed? (lawful consent basis, correct scope to prevent cross-user leaks, human review for sensitive categories). Tame extraction by forcing evidence citation and by separating high-trust observations (immutable episodes) from lower-trust inferences (revisable semantic facts). Handle correction by supersession (never edit in place) and erasure by revocation then scheduled hard-deletion with an audit record, and build the deletion path from day one, because retrofitting it is a nightmare and "we can't delete it" fails the regulator.
Reading Memory: Recency, Relevance, and Policy completes the pair, building the read gate that retrieves correctly from the governed store the write gate just protected.