The Desk and the Archive
> **Working claim:** The first honest long-context decision is not "what fits?" but "what belongs on the desk at all?" A prompt is a curated working set assembled for one task, not a dumping ground for everything that might be relevant.

The desk is the small working set the model can use now; the archive is everything the system can consult later, and confusing them is how long context becomes memory theater.
Working claim: The first honest long-context decision is not "what fits?" but "what belongs on the desk at all?" A prompt is a curated working set assembled for one task, not a dumping ground for everything that might be relevant. The archive is where things live; the desk is what you carry over for the next ten minutes of work.
Key Takeaways
- The desk/archive split keeps prompt context small enough to reason over and archive state durable enough to govern.
- A model should not receive the whole archive when it needs a precise working set.
- The operating question is always which archive item deserves to be placed on the desk for this request.
The metaphor, paid off
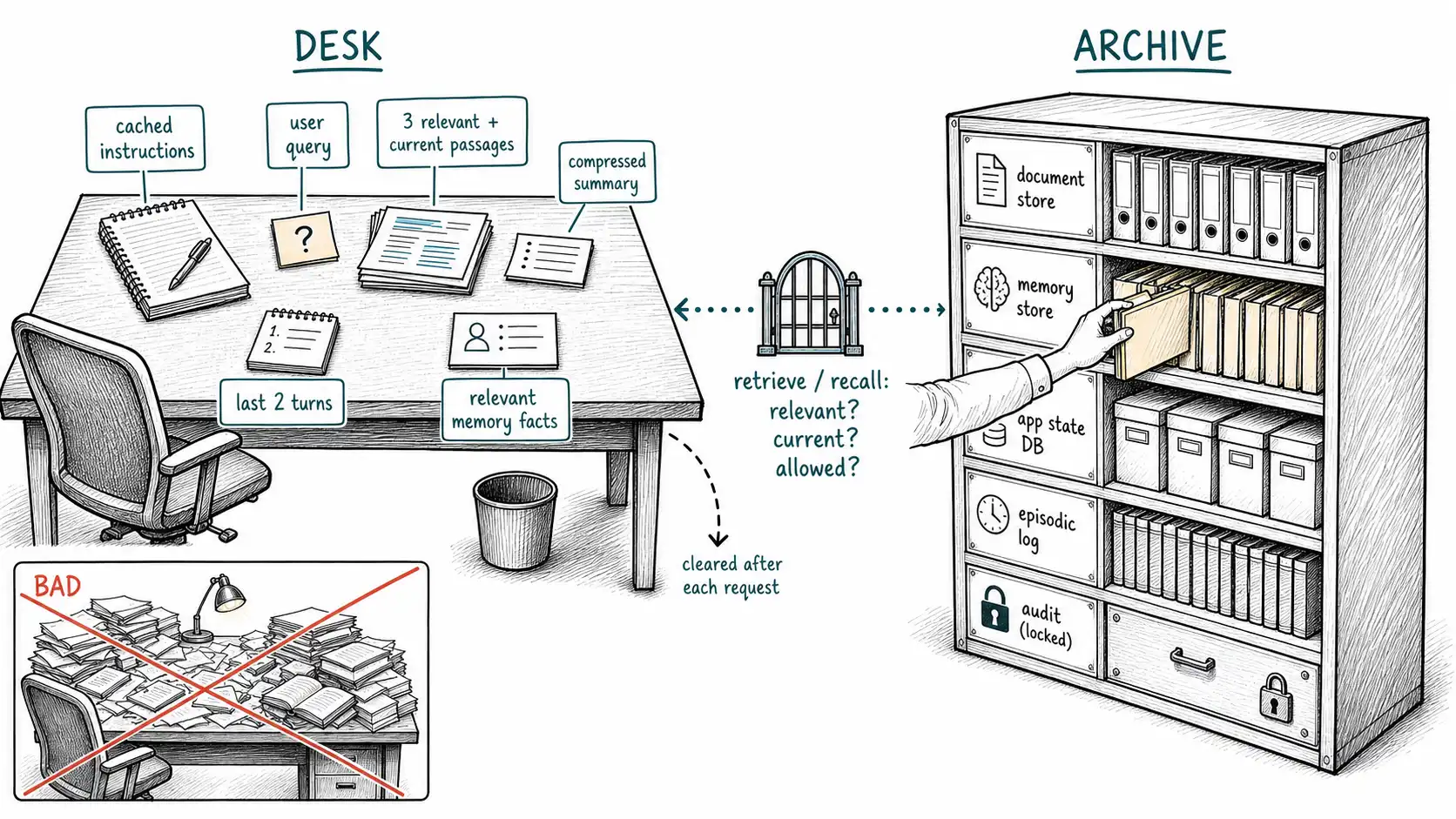
The previous two chapters earned the desk-and-archive metaphor; this chapter spends it. A desk is a working surface. Its defining property is not how large it is but that it is cleared and rebuilt for each task. A good worker does not pile every file they own onto the desk and squint; they walk to the archive, pull the three folders this task needs, lay them out in a sensible order, do the work, and clear the desk. The archive is the durable, organized, permissioned store. The desk is transient, curated, and personal to the moment.
Map this onto an AI system and the architecture falls out almost mechanically:
- The archive is everything durable: document stores, databases, the memory store, application state, audit logs, knowledge bases. It is large, organized, versioned, and access-controlled. It outlives any single request.
- The desk is the assembled prompt for one request. It is small relative to the archive, curated for the current task, ordered deliberately, and discarded after the forward pass.
- The act of walking to the archive and pulling the right folders is retrieval, memory read, and state load. This is where the real engineering is, and it is exactly the work the million-token mirage tells you to skip (see Lewis et al.'s foundational Retrieval-Augmented Generation for the architecture that makes this retrieval step principled).
The mistake the mirage encourages is to stop maintaining an archive and just keep piling onto an ever-larger desk. It works until the desk is covered, the lamp is small, and the one folder you needed is buried under ninety you didn't. That is not a hypothetical; it is the RULER result restated as furniture: usable working capacity is far smaller than physical surface area, because discrimination degrades as the pile grows.
"What belongs on the desk at all?": the question the mirage skips
Long context makes a new question optional, and because it is optional, teams skip it: should this be in the prompt at all? When the window was small, the question answered itself, almost nothing fit, so you were forced to choose. When the window is enormous, the lazy answer ("include it, why not, it fits") is always available, and it is almost always wrong, for reasons that compound.
Every token you add has four costs, and only the first is the obvious one:
- Money. You pay per input token. A 500k-token prompt sent ten thousand times a day is a real line item, and most of it is usually irrelevant material that contributed nothing.
- Latency. Larger inputs take longer to process. Time-to-first-token and total latency both grow with input size, and users feel it. Chapter 7 quantifies this.
- Accuracy. This is the counterintuitive one. Irrelevant context does not merely waste money; it actively degrades the answer by adding distractors that compete for selection. More is not safer. More is often worse.
- Auditability. A prompt assembled by "include everything that might help" cannot be reasoned about. When it produces a bad answer, you cannot say which of the ninety folders caused it. A prompt assembled by "include these three folders for this reason" can be debugged.
So the honest design question is a curation question, and it has a default answer that runs opposite to the mirage: exclude by default, include on justification. A piece of content earns its place on the desk by being the current, relevant, permitted evidence for this task, not by being potentially relevant to some task someday.
A taxonomy of what tries to get on the desk
In practice, content competing for prompt space falls into a small number of categories, and each has a different correct home. Confusing the categories is how desks get cluttered.
| Content type | Tempting home | Correct home | Why |
|---|---|---|---|
| Stable instructions (role, format, policy) | The prompt, every time | The prompt, and cacheable | Rarely changes; prefix-cache it so you don't re-pay (see Ch. 7) |
| The current user query | The prompt | The prompt | Obviously; it is the task |
| Relevant evidence for this task | "All of it, it fits" | The prompt, retrieved, top-k, current | Only the relevant, current subset belongs; the rest is distraction |
| The full document corpus | The prompt (the mirage) | The archive, queried by retrieval | A store to search, not a thing to paste |
| Conversation history | The prompt, verbatim, forever | Summarized + selective recall | Verbatim history grows unbounded and pollutes; compress with provenance |
| Durable user facts/preferences | "The model will remember" | The memory store, re-injected selectively | The model remembers nothing; a store does |
| Workflow state (cart, case, ticket) | The prompt narrative | Application state, read as structured data | State belongs in a database, not in prose the model must parse |
| Audit logs | Never the prompt | The audit store, model-invisible | Must exist for compliance; must not be shown to the model |
Read down the "correct home" column and you have the architecture of every reliable long-context system: a small cached instruction prefix, the live query, a retrieved-and-current slice of evidence, a compressed conversation summary, selectively recalled memory, structured state, and an audit trail the model never sees. The desk holds a curated assembly of those; the archive holds the rest.
The cost of treating the archive as a desk
It is worth being concrete about what goes wrong when an archive-shaped thing is forced onto the desk. Take conversation history, the most common offender. The naive design appends every turn verbatim and replays the whole transcript each request:
# Anti-pattern: the transcript is the memory, and it only grows.
history.append({"role": "user", "content": user_msg})
history.append({"role": "assistant", "content": reply})
prompt = system_prompt + render(history) + new_user_msg # unboundedThree failures are baked in. The prompt grows without limit, so cost and latency climb every turn until you hit the window ceiling and start silently truncating, usually the oldest turns, which may hold the user's original goal. The transcript accumulates contradictions: the user said "actually, make it blue" three turns after "make it red, " and now both are on the desk competing for selection. And nothing is governed: there is no consent, no expiry, no way to delete a specific fact on request, because "memory" here is just an ever-growing blob of prose.
The archive-shaped fix separates the durable signal from the transient transcript:
# Pattern: extract durable facts to a governed store; summarize the rest.
turn = record_turn(user_msg, reply) # episodic log (archive)
facts = extract_candidate_facts(turn) # "prefers blue", "deadline Friday"
for f in facts:
memory.write_if_allowed(f, user_id, consent_basis="stated_preference")
running_summary = summarize_with_provenance(history, keep_last=2) # lossy, traceable
prompt = (
cached_system_prompt
+ memory.recall(user_id, relevant_to=new_user_msg) # only relevant durable facts
+ running_summary # compressed history
+ render(history[-2:]) # last couple turns verbatim
+ new_user_msg
)The desk now holds a bounded, curated assembly: cached instructions, the few relevant durable facts, a compressed summary, the last couple of turns, and the new message. The growth is bounded, contradictions are resolved at write time instead of accumulating, and every durable fact is governed. The archive, the episodic log and the memory store, holds the rest, queryable but off the desk. We build each of these mechanisms properly in Movement III and IV; the point here is structural, that the fix is moving things to their correct home, not enlarging the desk to fit them all.
When the desk should be large
The metaphor is not an argument against ever using a big window, that would be its own kind of dogma. A large desk is exactly right for a class of tasks where the whole working set is genuinely relevant, current, and trusted, and where the task is reasoning over the set rather than retrieving from it:
- Single-document deep analysis. Summarizing, critiquing, or answering questions about one long document, a contract, a paper, a transcript, where the entire document is the relevant evidence and there is no "irrelevant subset" to exclude.
- Synthesis across a small, curated set. Comparing five specific documents you have already determined are the relevant ones. Here long context plus a citation map beats chunked retrieval, because the task needs cross-document reasoning that chunking breaks.
- Stable, cacheable context. A large instruction set, schema, or codebase that rarely changes and can be prefix-cached, so the per-request cost of the large context drops sharply after the first call.
The distinguishing feature of all three is that the large context is curated and justified, not defaulted. Someone decided this whole set belongs on the desk for this task. That is the opposite of "paste the corpus and hope." The decision table in Chapter 12 makes the "long context vs. retrieval vs. both" choice precise; the Anthropic context windows guide and the Google Gemini long-context documentation each catalog the specific task patterns where a large desk is the right choice versus where retrieval should own the work. For now, hold the principle: a big desk is a deliberate choice for whole-set reasoning, never a substitute for deciding what belongs.
A working rule for Movement I
Movement I has made one argument from three angles. Chapter 1 said the window is a desk and not a filing cabinet. Chapter 2 split the act of "using information" into six independent rungs and drew the line between the single-request rungs and the across-request rung. This chapter turned that into a design rule for what goes on the desk in the first place. The rule, stated plainly:
Assemble the prompt as a curated working set: exclude by default, include current/relevant/permitted evidence on justification, keep everything durable in the archive, and clear the desk every request.
Everything in the rest of the book is an implementation of that rule. Movement II explains why it is necessary by studying how the window actually behaves when you violate it, why a cluttered desk produces worse answers, not just slower ones. Movement III builds the archive: the taxonomy of memory and the gates that write and read it. Movement IV builds the act of pulling folders: the context assembler that curates the desk under a budget. Movement V proves the whole thing works.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
The first honest long-context decision is curation, not capacity: not "what fits?" but "what belongs on the desk at all?" A desk is a working surface that is cleared and rebuilt per task; an archive is the durable, organized, permissioned store that outlives any request. The mirage encourages abandoning the archive and piling onto an ever-larger desk, but every added token costs money, latency, accuracy (via distractors), and auditability, so the correct default is to exclude and include only on justification. Different content types have different correct homes: stable instructions belong in a cached prefix, evidence belongs retrieved and current, history belongs summarized, durable facts belong in a memory store, workflow belongs in application state, and audit logs belong where the model never sees them. A large desk is legitimate but only as a deliberate choice for whole-set reasoning over a curated, current, trusted set, never as a substitute for deciding what belongs. The working rule for the rest of the book: assemble a curated working set, keep the durable in the archive, and clear the desk every request.
Tokens, Windows, and the Shape of Attention provides the mechanical grounding for why the desk must be curated, explaining how the finite attention pool determines what the model actually uses from any given desk.