Conflicts, Recency, and Knowing Which Tool to Reach For
> **Working claim:** Two hard problems sit at the center of context engineering, and both are usually solved by accident, badly. The first is *conflict*: when the user, a document, and a stored memory disagree, the system must not silently pick one.

Conflicts in AI memory are not edge cases; they are the normal state once old facts, new facts, source authority, and tool results disagree inside one context window.
Working claim: Two hard problems sit at the center of context engineering, and both are usually solved by accident, badly. The first is conflict: when the user, a document, and a stored memory disagree, the system must not silently pick one. The second is tool selection: long context, retrieval, and memory are not competitors to choose between once, but a toolkit to combine per need.
Key Takeaways
- Recency is only one signal; source authority, policy, confidence, and application state often outrank the newest memory.
- A memory system needs conflict rules before retrieval, not an apology after the model blends two incompatible claims.
- The right tool is usually the source of truth nearest the decision: database for state, retrieval for evidence, memory for preferences, audit for proof.
Part one: the conflict triangle
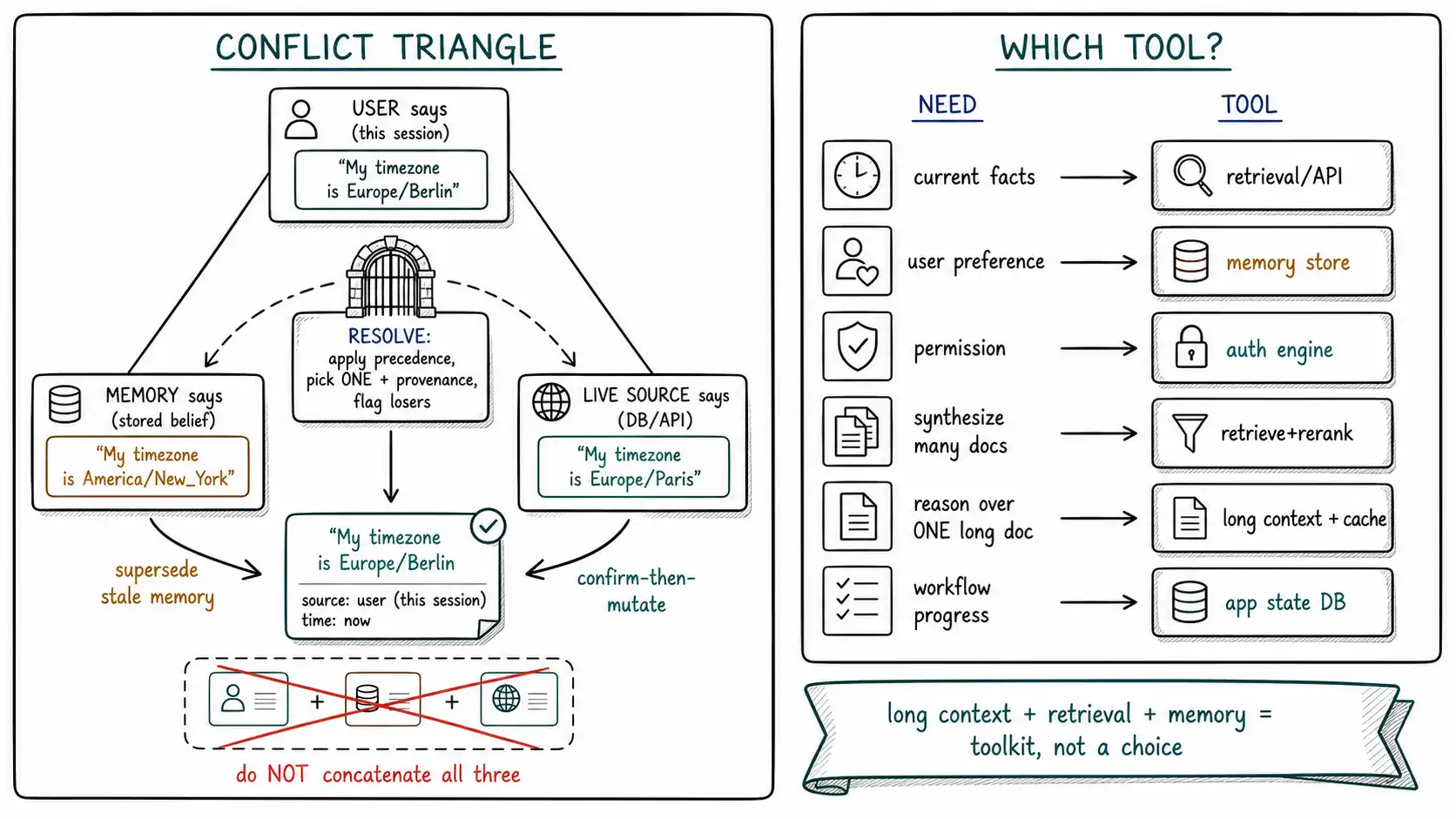
Every non-trivial assistant eventually faces three sources of "truth" that disagree:
- The user says something in this session: "I'm on the Pro plan."
- A stored memory holds a durable claim from before: "user is on the Free plan."
- A live source, the billing database, a freshly retrieved document, says a third thing: "Free, but a Pro upgrade is pending."
The naive system concatenates all three into the prompt and lets the model sort it out. This is the worst possible choice, because it converts a data integrity problem, which the system can resolve deterministically, into a generation problem, where position and phrasing decide the outcome and the answer is non-reproducible. The model might quote the user, the memory, or the database depending on where each landed and how confidently each was worded (the distractor dynamics of Chapter 2). Silent merging of contradictions is the single most common way personalized assistants become confidently wrong.
The discipline is a conflict hierarchy: when sources disagree, the system applies an explicit precedence rather than letting the model guess. A defensible default precedence for facts about the world and the user:
| Source | Precedence | Rationale | On conflict |
|---|---|---|---|
| Live authoritative system (billing DB, auth) | Highest | Source of truth, current by construction | Wins; flag memory for supersession |
| Fresh user assertion this session | High | Most current human intent | Wins over memory; may update the live system via a tool, with confirmation |
| Recently retrieved current document | High | Current, but interpret in context | Wins over stale memory; defer to live system for system-owned facts |
| Stored durable memory | Lower | A belief about the past; may be stale | Loses to all above; gets re-confirmed or superseded |
| Model parametric knowledge | Lowest | Untraceable, possibly outdated | Never overrides traceable sources |
The point is not that this exact ordering is universal, a medical system might rank a verified record above a patient's casual assertion, and the precedence is domain policy. The point is that there must be an ordering, applied in code, before generation, with the loser not discarded but flagged: a memory that lost to live data is stale and should be re-confirmed or superseded (Chapter 9); a user assertion that contradicts the live system may be a request to change the system, routed to a tool with confirmation, not a fact to silently absorb.
def resolve_conflict(claims: list[Claim]) -> Resolution:
"""claims: same subject+attribute, different values, different sources."""
ranked = sorted(claims, key=lambda c: SOURCE_PRECEDENCE[c.source])
winner = ranked[0]
losers = ranked[1:]
actions = []
for l in losers:
if l.source == "durable_memory":
actions.append(SupersedeOrReconfirm(l.memory_id, winner.value))
elif l.source == "user_assertion" and winner.source == "live_system":
# User disagrees with the system of record: do NOT silently overwrite.
actions.append(ConfirmThenMutate(target=winner.source, proposed=l.value))
return Resolution(use_value=winner.value, provenance=winner.source,
followups=actions, was_conflict=True)Crucially, resolve_conflict never returns "both." It returns one value, its provenance, and a list of follow-up actions to reconcile the losers. The model receives a single, attributed fact, not a contradiction to adjudicate. And was_conflict=True is logged, because a rising conflict rate is an early signal that memory is drifting from reality (Chapter 14's monitoring).
Recency versus relevance, stated precisely
A special, pervasive case of conflict is recency vs. relevance. Retrieval ranks by relevance; the world changes over time; and the most relevant document is sometimes not the most current. The policy team's failure was exactly this, the most textually relevant passage (the detailed exclusion clause) was not the current one (the addendum). Relevance found the right topic and the wrong version.
The resolution is to stop treating recency as something the model should infer from content and make it a retrieval-time filter and ranking signal, owned by the data layer:
- Filter on currency first. Retrieve only current versions where a document has versions, using the supersession metadata (the same
superseded_bydiscipline as memory). The obsolete exclusion clause should not be a retrieval candidate once an addendum supersedes it. - Then rank by relevance within the current set. Recency is a hard gate, not a soft tiebreaker, for facts that have a clear "current version."
- For facts without versions (a research paper, a historical record), recency is a soft signal blended into ranking, because newer is not always better, sometimes the foundational older source is what you want.
The general principle: recency is metadata, not content, so it must be enforced by the data layer before the model ever sees the candidates. Prompting "prefer the most recent information" is hope; filtering out superseded versions is engineering. A model cannot reliably determine which of two authentic, similarly-worded passages is current, the only difference is a date the model has no privileged access to.
Part two: the toolkit, not the choice
The book's framing might suggest long context is the villain and retrieval the hero. That is too simple, and an honest chapter must correct it. Long context, retrieval (grounded in the Lewis et al. RAG architecture), and memory are complementary tools, and mature systems use all three, each for what it does best. The mistake the mirage makes is not using long context; it is using it for jobs the other tools do better: durable facts, permission, current data, multi-document synthesis at scale.
Here is the decision table the front matter promised, expanded:
| Need | Reach for | Not | Why |
|---|---|---|---|
| Current facts about a changing world | Retrieval / live API | Long-context dump | Currency is a data-layer property; dumps go stale and can't be versioned |
| A specific user's preferences/attributes | Durable memory store | "The model will remember" / history replay | The window is stateless; persistence needs a governed store |
| Permission / who-can-see-what | Auth + policy engine | Prompt instructions | Trust is structural (Ch. 2); a prompt is not a security boundary |
| Synthesis across many documents | Retrieval + rerank + citation map | Dump all docs | Effective context collapses with distractors (RULER, Ch. 6) |
| Deep reasoning over ONE long document | Long context (+ cache) | Aggressive chunking | Chunking severs cross-document structure the task needs |
| A fixed, stable, fully-relevant corpus queried all day | Long context + prompt caching | Re-retrieving every turn | Cacheable stable prefix makes it cheap; whole set is relevant |
| Conversation continuity | Summaries + episodic log + selective recall | Verbatim transcript replay | Transcript grows unbounded and pollutes (Ch. 3) |
| Workflow / entity progress | Application state (DB) | Memory snippets / prose | State is structured source-of-truth, not fuzzy recall |
| Multi-step task improvement over time | Procedural memory (skills) | Re-deriving each run | Reusable routines (Voyager-style, and the Generative Agents reflection pattern) beat re-reasoning |
Read it as a routing function. Most real products combine several rows: a support copilot uses retrieval for product docs, application state for the ticket, durable memory for the customer's preferences, long context when deeply analyzing one long attached log, and prompt caching for its large stable instruction set. The skill is not picking one tool; it is decomposing the task into the parts each tool serves and assembling them (Chapter 11).
When long context genuinely wins
To be concrete and fair, three patterns where reaching for the big window is the right call, not a concession:
- Single-document deep work. Summarizing or interrogating one long contract, paper, deposition, or log file where the whole document is the relevant evidence and chunking would break the cross-references the task depends on. Here retrieval would hurt, you would be fragmenting exactly what needs to stay whole.
- Small curated multi-document synthesis. Comparing five specific documents you have already determined are the relevant set. Long context plus an explicit citation requirement beats chunked retrieval because the task is cross-document reasoning, and five documents is comfortably inside the effective context for most current models.
- Stable cacheable context. A large, rarely-changing instruction set, schema, codebase, or knowledge base that you prefix-cache, so the per-request cost of the large context drops to the variable tail after the first call.
What unites all three, and separates them from the mirage, is that the large context is curated and justified, someone decided this whole set belongs on the desk for this task, and it is inside the effective, not merely the advertised, context (Chapter 6). The mirage is "dump everything because it fits." The legitimate use is "include this whole, specific, relevant set because the task is to reason over all of it." Same big window, opposite discipline.
Hybrid patterns worth knowing
The frontier is not "long context vs. RAG" but their combination, and a few patterns recur:
- Retrieve-then-read-long. Retrieval narrows a huge corpus to the dozen most relevant documents, then the full text of those documents (not chunks) goes into a long context for cross-document reasoning. Best of both: corpus-scale recall, document-scale coherence.
- Self-reflective retrieval. Approaches like Self-RAG let the system decide whether to retrieve and critique what it retrieved, rather than always stuffing context. This directly attacks pollution, retrieve only when needed, keep only what survives critique.
- Cache the corpus, vary the query. For a stable document set queried repeatedly, load it once into a cached long context and vary only the question in the tail, turning a per-request cost into a near-one-time one.
The assembler from Chapter 11 is what makes hybrids practical: it is already a component that gathers from multiple sources, ranks, budgets, and orders. Adding a hybrid pattern is changing what it gathers and how it decides to gather, not rebuilding the system.
Closing Movement IV
Movement IV turned the principles of Movements I-III into an operating discipline. Chapter 11 built the assembler, the component with a budget, a priority order, and a policy that decides what goes on the desk, compacts before dropping, orders for attention and cache, and logs every choice. This chapter handled the two judgment calls the assembler must make well: resolving conflicts by an explicit precedence applied in code before generation (never silently merging contradictions, always carrying provenance and flagging the losers), enforcing recency as a data-layer filter rather than a model hope, and routing each part of a task to the right tool from a toolkit in which long context, retrieval, and memory are complementary rather than competing.
The system is now built: it knows what the window is and is not (Movement I), how the window behaves and bills (Movement II), how memory is written and read as a governed system (Movement III), and how to assemble the desk and resolve conflicts under a budget (Movement IV). What remains is the question that separates a system that works in a demo from one that works in production: how do you know it remembers the right things, for the right reasons, and keeps doing so? Movement V makes the whole thing measurable.
Where this connects
Read this chapter beside the full Long Context Is Not Memory book, Memory Systems for Agents, and Agents That Actually Work. If the read path starts looking like retrieval, the adjacent failure mode is why most RAG pipelines fail in month three.
Source note
The external frame for this chapter comes from Lost in the Middle, MemGPT, Generative Agents, and MemoryBank. I use them for a narrow claim: long windows, external stores, simulated behavior, and durable memory are different mechanisms that need different controls.
Chapter summary
Two central problems are usually solved by accident and badly. Conflict: when the user, a stored memory, and a live source disagree, concatenating all three converts a deterministic data-integrity problem into a non-reproducible generation problem decided by position and phrasing. The fix is a conflict hierarchy applied in code before generation, a domain-specific precedence (typically live authoritative system > fresh user assertion > recent current document > stored memory > parametric knowledge) that returns exactly one attributed value plus follow-up actions, never "both, " flagging losers for supersession or confirm-then-mutate and logging that a conflict occurred.Recency vs. relevance is the pervasive special case: recency is metadata, not content, so currency must be a retrieval-time filter (drop superseded versions before ranking) rather than a prompt instruction the model cannot reliably honor.Tool selection: long context, retrieval, and memory are a complementary toolkit, not a one-time choice, a decision table routes each need (current facts → retrieval, preferences → memory, permission → auth, multi-doc synthesis → retrieve+rerank, single-long-doc reasoning → long context + cache, workflow → app state) and real products combine several. Long context genuinely wins for curated, justified, whole-set reasoning inside the effective context, and hybrid patterns (retrieve-then-read-long, self-reflective retrieval, cache-the-corpus) are the frontier, all practical because the Chapter 11 assembler already gathers, ranks, budgets, and orders from multiple sources.
Measuring What the System Actually Remembers turns the discipline of Movements I–IV into an eval suite, providing the metrics and golden-case structure that prove the whole system actually works, not just in the demo.