Conclusion: Build Where Scale Needs You
A sober stance for the next capability shock: do not fight scale where it is structurally advantaged, build where it needs context, ownership, trust, and distribution to become useful.

Research spine
This chapter is grounded in Stanford HAI, 2026 AI Index Report, Stanford HAI, 2025 AI Index Report, and Rich Sutton, The Bitter Lesson.
The durable AI moat is not model cleverness alone; it is the workflow, data, trust, distribution, and evaluation stack that survives scale.
Let me return to Verant, because the founder's question from the introduction deserves an answer, and the answer is the whole book in miniature.
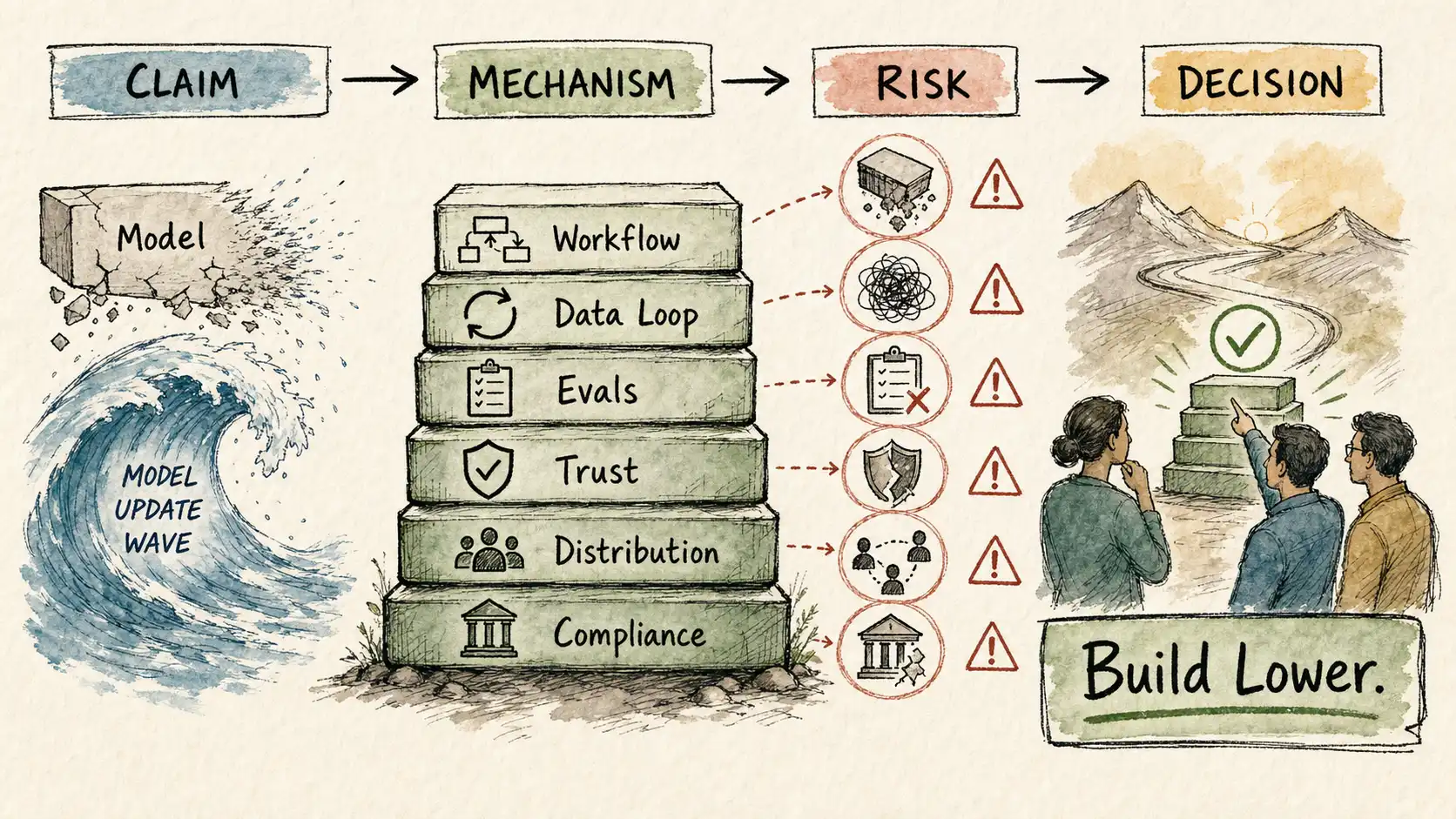
The founder asked whether the company still had a reason to exist after a routine model update matched a year of specialized work. The honest answer was: not for the reason you thought, and yes for reasons you had not been counting. The model was gone as a moat. It was never a moat, only a head start, and the head start had expired on the schedule the bitter lesson always sets. But the integrations into the hospital systems were not gone. The reporting workflow the radiologists had built habits around was not gone. The compliance posture that took eighteen months to earn was not gone. The stream of corrections flowing back from real use was not gone, and it was the one asset getting stronger every day. The company had been losing sleep over the one layer that the update could touch and ignoring the four layers it could not. When they stopped defending the model and started compounding the layers below it, they had a business again. Smaller in ambition than the model-first story, more durable in reality.
That is the migration this book is named for, lived out in one company. Scale ate the cleverness at the model layer, and the cleverness had to move somewhere scale could not reach. The companies that survive are the ones that move it on purpose, early, before the shock forces them.
What the bitter lesson actually demands of you
Sutton's essay was a warning to researchers: stop trying to build your knowledge into the system, because general methods that use computation will pass you, and by a large margin. The business translation is not that strategy is dead. It is the central thesis I asked you to carry from the first page: strategy must move to the layers scale does not automatically solve.
That single reframing dissolves the three lazy conclusions the book set out to kill. Scale does not make every application company defenseless, because defensibility migrates down the stack rather than vanishing. Custom cleverness does not always win, because at the model layer it loses on a schedule you do not control. And open versus closed is not the whole question, because the choice of weights sits at the most commoditized layer and cannot, by itself, be a moat for anyone. All three errors share a root: they treat the model layer as the whole game. The bitter lesson's real lesson for business is that the model layer is the part of the game you should expect to lose, and the strategy is everything you build around losing it gracefully.
The stance, stated plainly
Here is the stance the book has been building toward, sober and unhedged.
Do not fight scale where scale is structurally advantaged. Do not train your own frontier model to compete with the labs unless that is your entire business and you can fund the compute curve indefinitely, which almost none of you can. Do not bank a fine-tune, a clever prompt, a chunking pipeline, or a capability gap as a moat, because all of them sit at the layer the compute curve is built to flatten. Do not spend your scarce senior engineers tuning models when the frontier will match the tuning for free in a quarter. Fighting scale at the model layer is the most common expensive mistake in the field, and it feels like the most legitimate AI work, which is exactly why it is so tempting and so wrong.
Build where scale needs context, ownership, trust, economics, and distribution to become useful. Build into the workflow, the thirty minutes around the model call that is full of context the model does not have. Build the integrations that take eighteen months and that a better model does not hand to your competitor. Build the feedback loop that turns real usage into private signal no one else can copy. Build the eval discipline that lets you adopt every model improvement faster and more safely than anyone guessing. Build the distribution, the trust, and the compliance posture that are accumulated over years and immune to the compute curve. These are the layers where scale needs you, where a more capable model is a rising tide that lifts your product instead of a wave that drowns it.
That is the difference between fighting scale and riding it. The company that fights scale treats every model release as a threat to defend against. The company that rides scale treats every model release as a free upgrade to an engine it does not depend on for its moat. Same release, opposite experience, and the difference is entirely where you chose to build.
The frameworks, one last time, as a working set
You now have four instruments, and they work as a set, not as isolated tools.
The Moat Migration Stack is your map. It tells you which layers erode under scale and which hold, and it shows you that defensibility moves down rather than disappears. Read your business through it whenever you are not sure where you stand.
The Scale Exposure Test is your diagnostic. One question, three vectors, run as a tree against any advantage: would a larger, cheaper, or more tool-capable model weaken this. It tells you, fast, whether you are holding a moat or a head start, and it generalizes to your roadmap, your hiring, and your pricing.
The Bitter Lesson Response Matrix is your decision set. Five honest moves: fight scale, rent scale, compress scale, combine scale, avoid model-layer competition. It keeps you from pretending there is only one option, and for most of you the answer is rent-plus-combine: rent the best model, combine it with the lower-layer moats that are actually yours.
The Durable Layer Map is your investment guide. Trust, latency, cost, domain data, integration depth, compliance posture, user habit, eval discipline: the properties that resist scale and reward investment. When you are deciding where the next quarter of effort goes, go here.
Run them together and they answer the only question that matters in this field: given that the model layer commoditizes on a schedule I do not control, what am I building that scale cannot reach.
What to do Monday
Not someday. Monday.
Run your single most-cited advantage through the Scale Exposure Test before lunch. If it lands on high exposure, do not argue with the result, thank it for the early warning, and ask what you are building down the stack that does not.
Draw your business on the Moat Migration Stack and score each layer for strength and exposure. If your strength is concentrated at the top, you have a head start, and your job this quarter is to convert it into position lower down before it expires.
Write your capability shock response plan as a one-page runbook and name who runs each step. The next Tuesday model release should meet a drill, not a meltdown.
And pick one piece of plumbing to build: the seam that makes your model swappable, or the capture mechanism that turns user corrections into a compounding feedback loop and a sharpening eval suite. One of those, started Monday, does more for your durability than another month of model tuning.
The sober close
I will not tell you the model era is easy, because it is not. The compute curve is relentless, the shocks are real, and the layer everyone instinctively wants to defend is the layer they will lose. A lot of companies that feel like AI companies today are renting a temporary capability gap and calling it a moat, and the market will eventually correct them, sometimes overnight, on a Tuesday.
But the bitter lesson is not a counsel of despair, and reading it that way is the largest mistake of all. It is a counsel of focus. It tells you, with seventy years of evidence, exactly where not to spend your effort, which is an enormous gift, because the field is full of people spending their effort there anyway. It frees you to build where building actually pays: in the workflow, in the data you operate into existence, in the trust you earn on the bad days, in the distribution you fight for in the seams, in the eval discipline that compounds, in the feedback loop that widens the gap every day you run and your competitor does not.
Scale eats cleverness at the model layer, then forces cleverness to migrate elsewhere. Your job is to be elsewhere already, building the layers where a more capable model makes you stronger instead of obsolete. Do that, and the next capability shock, whenever it lands and whatever it eats, finds you standing on ground it cannot reach.
That is the whole revisited lesson. Not that strategy is dead. That strategy moved, and you can move with it.
Key Takeaways
- The bitter lesson's business meaning is not that strategy is dead but that strategy must move to the layers scale does not automatically solve. The model layer is the part of the game you should expect to lose.
- The three lazy conclusions all share one root: treating the model layer as the whole game. Defensibility migrates down the stack rather than vanishing, custom cleverness loses at the model layer on a schedule, and the choice of weights cannot itself be a moat.
- Do not fight scale where it is structurally advantaged. Build where scale needs context, ownership, trust, economics, and distribution to become useful.
- The four frameworks work as a set: the Moat Migration Stack maps where you stand, the Scale Exposure Test diagnoses any advantage, the Response Matrix gives you the five honest moves, and the Durable Layer Map guides where to invest.
- For most application companies the move is rent-plus-combine: rent the best available model and combine it with the lower-layer moats that are genuinely yours.
- Start Monday: test your top advantage, score your stack, write a one-page shock runbook, and build one piece of plumbing, a swappable model seam or a correction-capture loop, that compounds your durability.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.