The Scale Exposure Test
One question, run as a decision tree, that tells you whether an advantage will survive the next better model or melt under it.

Research spine
This chapter is grounded in Stanford HAI, 2026 AI Index Report, Stanford HAI, 2025 AI Index Report, and Rich Sutton, The Bitter Lesson.
There is a question I have asked in enough strategy reviews that I now ask it reflexively, the way a doctor asks whether it hurts when they press here. The question is this: would a larger, cheaper, or more tool-capable general model weaken what you just described as your advantage?
It sounds simple to the point of being trivial. It is not trivial in practice, because most teams have never asked it about their own advantages out loud, and when they finally do, the answer is frequently yes, and the room goes quiet. That quiet is the most valuable thing the question produces. It is the sound of a team realizing that the thing they have been defending in board decks is exposed to a force they cannot fight.
This chapter turns that question into a repeatable instrument: the Scale Exposure Test. It is the diagnostic that runs underneath the entire Moat Migration Stack. Where the stack tells you which layers tend to be exposed, the test tells you, for your specific advantage, whether it actually is.
The three vectors of scale
The question names three vectors because scale does not advance on one front. An advantage can survive one and die to another, so you have to check all three.
Larger. A model with more capability: better reasoning, broader knowledge, higher accuracy on the task. This is the vector everyone thinks of. If your advantage is "our system is more accurate at this task," a larger model is coming for it directly.
Cheaper. A model that delivers the same capability at a lower price per token. This vector kills advantages that depend on the model being expensive. If your business model assumes inference is costly enough that customers will not just call the API themselves, a cheaper model removes the assumption. Many "we do it efficiently" advantages are really "we do it when the obvious approach is too expensive," and they evaporate when the obvious approach gets cheap.
More tool-capable. A model that can use tools, call functions, browse, execute code, and orchestrate multi-step tasks. This is the vector people miss most often, and it is the one quietly eating the most businesses right now. A lot of application companies are, underneath, a wrapper that decomposes a task into steps and calls a model for each step. When the model itself learns to decompose and orchestrate, the wrapper's value collapses. The advantage was "we know how to break this problem into model-sized pieces," and a more tool-capable model now does that itself.
You must run all three vectors, because an advantage that is safe from "larger" and "cheaper" can still die to "more tool-capable," and that is the death that surprises teams, because they were watching the accuracy benchmark and not the agentic one.
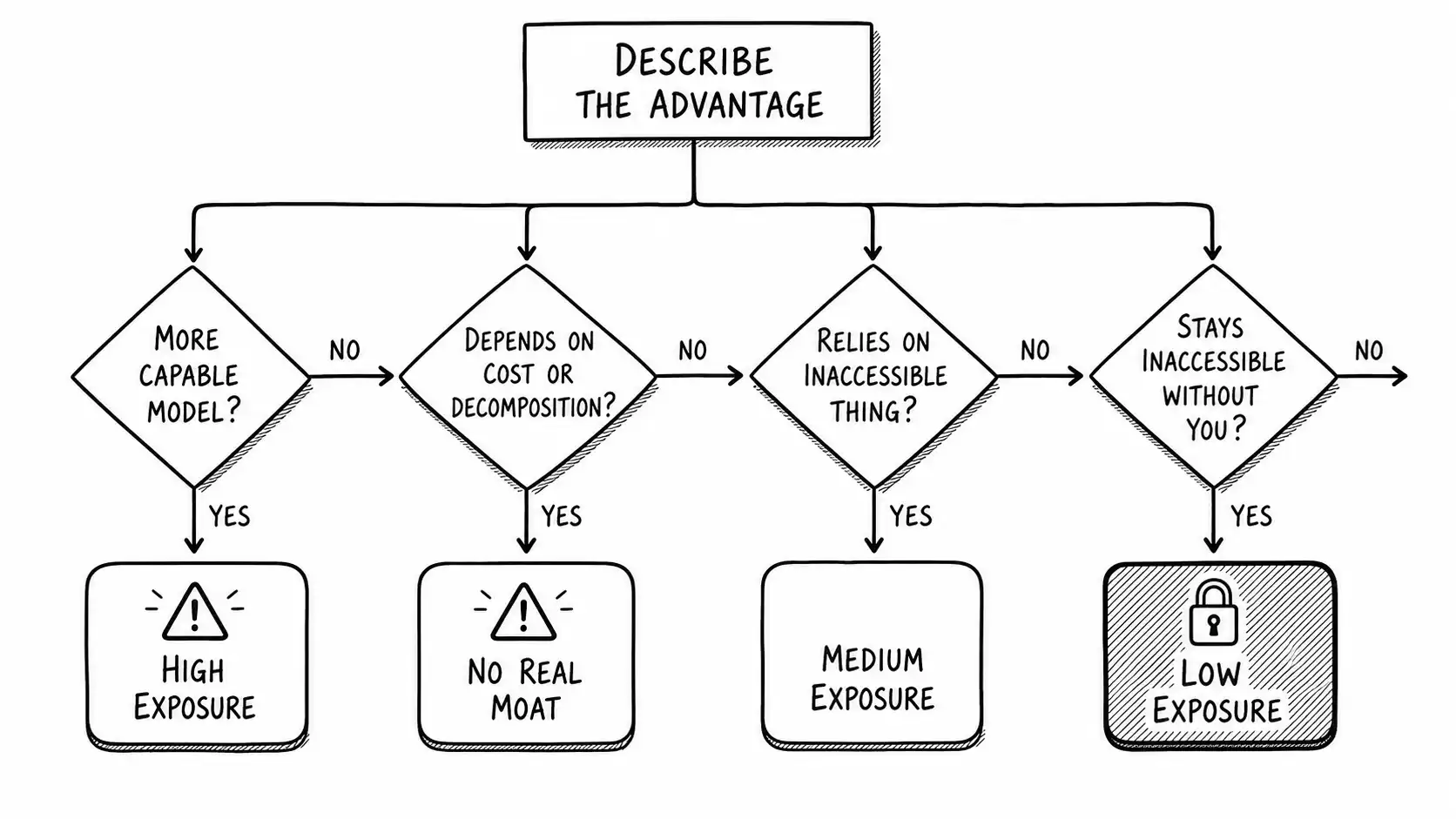
The decision tree
Here is the test as a tree. Run any claimed advantage through it.
START: Describe the advantage in one sentence.
Q1. Is the advantage primarily that your model is more capable at a task?
YES -> HIGH EXPOSURE. A larger model closes this. Treat as a head start, not a moat.
NO -> continue.
Q2. Does the advantage depend on the model being expensive or on you decomposing the task?
YES -> HIGH EXPOSURE. Cheaper or more tool-capable models remove the basis. Continue to Q3 to check what is left.
NO -> continue.
Q3. Does the advantage rely on something the general model structurally cannot access:
private live data, an owned workflow, a distribution channel, a compliance posture,
or a private feedback loop?
NO -> NO REAL MOAT. You are standing on capability. Build down the stack now.
YES -> continue.
Q4. For that inaccessible thing, would the general model getting better still leave it
inaccessible without your cooperation?
NO -> MEDIUM EXPOSURE. The access can be replicated or disintermediated. Strengthen the lock-in.
YES -> LOW EXPOSURE. This is a durable layer. Invest and compound it.The tree is doing one job: it pushes every advantage down the Moat Migration Stack until it either hits a layer scale cannot reach or runs out of layers. If it runs out of layers, you have no moat, only a head start, and the test has done you the favor of telling you before the market does.
Worked examples, including ones that fail
Theory is cheap. Let me run real-shaped advantages through the test so you can feel where the cuts fall. These are composites, not specific companies, and I label them as illustrative.
Advantage A: "We have the most accurate contract-clause classifier." Q1: is it primarily that your model is more capable at a task? Yes. HIGH EXPOSURE, full stop. A larger general model will match this, and on the schedule we established, in months. This is Verant. It is a head start. The only useful follow-up is what you build with the head start.
Advantage B: "We are cheaper than calling the frontier API directly because we use a small distilled model for most requests." Q1: no, it is not about being more capable. Q2: does it depend on the model being expensive? Yes, the whole basis is that the frontier API is costly. HIGH EXPOSURE on the "cheaper" vector. When the frontier API's price drops, which it does on a steep curve, your cost advantage narrows. This can still be a real tactic, the chapter on small models treats it seriously, but it is not by itself a moat. You must check Q3 for what survives.
Advantage C: "We have read and write integrations into the customer's ERP, CRM, and ticketing systems, and the workflow runs through us." Q1: no. Q2: no, it does not depend on the model being expensive or on us decomposing the task, the integrations exist regardless. Q3: does it rely on something the model cannot access? Yes, an owned workflow and live data in systems the model has no path to. Q4: would a better model still leave that inaccessible without your cooperation? Yes, because the model getting smarter does not give it credentials to the customer's ERP or the certified integration. LOW EXPOSURE. This is a durable layer. Invest.
Advantage D: "We have the largest dataset of labeled support tickets in our industry." Q1: no. Q2: no. Q3: does it rely on something inaccessible to the model? Here is where you have to be honest. If the tickets are the kind of text a general model has effectively already seen the equivalent of, the answer trends toward NO REAL MOAT, because the model learned the general pattern from the open web and your specific labels add a thin, copyable layer. If the tickets contain private operational signal that the model has no equivalent of, and you keep accumulating it inside a workflow competitors do not have, you continue. Q4 then asks whether that accumulation stays private. If a competitor can buy or scrape an equivalent dataset, MEDIUM EXPOSURE. If the dataset only exists because of your workflow and feedback loop, LOW EXPOSURE. Most "we have the biggest dataset" claims wash out at Q3 or Q4. The data-moat chapter is largely an expansion of this single example.
Notice the shape. Two of the four advantages most teams would put on a slide are HIGH EXPOSURE, one is genuinely durable, and one depends entirely on a distinction most teams have not drawn. That ratio is roughly what I see in the wild.
Running the test on a roadmap, not just a pitch
The test is most valuable applied not to your current pitch but to your roadmap, because the roadmap is where you are about to spend money. Take each major initiative for the next two quarters and run it through the tree before you fund it.
The pattern that should alarm you is a roadmap where most of the funded work lands on HIGH EXPOSURE leaves. That is a team investing its scarce engineering time into advantages that the compute curve will erase before the work ships its second version. I have seen roadmaps that were, line by line, a list of capability gaps the team was racing to open, every one of which a frontier update would close. The team felt productive. They were sprinting up a melting glacier.
The healthy pattern is a roadmap where the HIGH EXPOSURE work is explicitly labeled as a head start with a short payback window, and the bulk of the durable investment lands on LOW EXPOSURE leaves: deepening integrations, tightening the feedback loop, earning compliance posture, building distribution. You are allowed to do HIGH EXPOSURE work. You are not allowed to mistake it for a moat or to fund it as if it will last.
The test as a hiring and pricing tool
Two less obvious uses, because the test generalizes.
In hiring, the test tells you where your scarce senior talent should sit. If your best engineers are tuning models at a HIGH EXPOSURE layer, you are spending your most expensive resource on your least durable advantage. Move them to the workflow, integration, and eval layers where their work compounds. The bitter lesson applies to your org chart, not just your stack.
In pricing, the test tells you which parts of your value you can actually defend a price on. You cannot durably charge a premium for the part of your value that is HIGH EXPOSURE, because a customer can eventually get it from a cheap API. You can charge for the LOW EXPOSURE parts: the integration you maintain, the compliance you carry, the workflow you own, the feedback loop that makes your outputs reliable on their specific tasks. Price the durable layers. Treat the model-layer value as table stakes, because that is what scale is turning it into.
A standing ritual
Make the test a ritual, not a one-time exercise, because the frontier moves and an advantage that passed the test last year can fail it this year. The "more tool-capable" vector especially mutates fast: a workflow advantage that was durable when models could not orchestrate becomes exposed the quarter models learn to orchestrate.
I recommend running the full test against your top three advantages every time a major frontier model ships, which is to say every few months. It takes an afternoon. The afternoon you skip it is the afternoon a competitor, or a model release, redraws your map without telling you. The capability-shock chapter builds this ritual into a full response plan, but the test is the core of it: when the model changes, re-run the question, because the model changing is exactly the event the question was designed for.
What to do differently tomorrow
Take your single most-cited advantage, the one in your deck's defensibility slide, and run it through the four questions before lunch. If it lands on HIGH EXPOSURE or NO REAL MOAT, do not panic and do not argue with the test. Treat the result as information you are lucky to have early. Then ask the only question that matters next: given that this melts, what am I building down the stack that does not?
That question is the whole strategy of this book compressed into one sentence, and the Scale Exposure Test is the instrument that forces you to ask it honestly. The next chapter applies the test to the question everyone wants to lead with, open models versus frontier APIs, and shows why it is one variable in the system rather than the whole game.
Key Takeaways
- The Scale Exposure Test asks one question: would a larger, cheaper, or more tool-capable general model weaken this advantage? Run all three vectors, because an advantage can survive two and die to the third.
- The "more tool-capable" vector is the one teams miss most, and it is currently eating the most wrapper businesses as models learn to decompose and orchestrate tasks themselves.
- The decision tree pushes every advantage down the Moat Migration Stack until it hits a layer scale cannot reach or runs out of layers. Running out of layers means head start, not moat.
- Most slide-worthy advantages fail the test: capability and cost-arbitrage advantages are high exposure, and most "biggest dataset" claims wash out on accessibility.
- Run the test against your roadmap, not just your pitch. A roadmap full of high-exposure work is a team sprinting up a melting glacier.
- The test generalizes to hiring and pricing: put senior talent and premium pricing on the low-exposure layers, and treat model-layer value as table stakes. Re-run the test every time a major model ships.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.