The Capability Shock Response Plan
What breaks when a model improves suddenly, and a plan you can run in an afternoon instead of panicking for a quarter.

Research spine
This chapter is grounded in Stanford HAI, 2026 AI Index Report, Stanford HAI, 2025 AI Index Report, and Rich Sutton, The Bitter Lesson.
The durable AI moat is not model cleverness alone; it is the workflow, data, trust, distribution, and evaluation stack that survives scale.
The call comes on a Tuesday, because the model releases come on Tuesdays. A founder, a CTO, or a head of product, voice tight, says some version of: a new model just shipped and it does the thing our product does, and the team is melting down, and I do not know whether we still have a business. I have taken this call enough times that I now keep a checklist for it, because the difference between the companies that survive a capability shock and the ones that spiral is almost entirely whether they have a plan ready before the shock or are improvising during it.
A capability shock is a sudden, discontinuous jump in what the general model can do, the kind that closes a gap you were depending on in a single release rather than gradually. The scaling-laws chapter argued that capability improves smoothly in loss but lumpily in the specific abilities you sell against, and the lumps are the shocks: the quarter the model suddenly gets good at tool use, the release where it suddenly handles long context, the update where it suddenly does the extraction your whole product was built around. The shocks are not predictable in timing, but they are predictable in kind, which means you can prepare for the category even though you cannot diary the date.
Why panic is the wrong first move, and so is denial
There are two failure modes when the shock lands, and they are mirror images.
The first is panic: the team concludes the business is dead, morale collapses, people start updating their resumes, and the company spirals into a self-fulfilling decline while the actual situation was survivable. The panic is usually rooted in the first lazy conclusion from the introduction, that scale makes every application company defenseless, applied in the moment of maximum fear. It feels like clear-eyed realism. It is usually a category error, because the shock hit one layer and the team is reacting as if it hit all of them.
The second is denial: the team insists the new model does not really do what their product does, finds the cases where their product is still better, and uses those cases to avoid confronting the shock. This is the second lazy conclusion, that custom cleverness always wins, deployed as a defense mechanism. It feels like confidence. It is usually a slow-motion version of the Verant story, the team defending a model-layer advantage that is already gone while the window to migrate down the stack closes.
The response plan exists to replace both with a sequence of concrete steps, run in a fixed order, that gets you to an accurate map of the damage and a decision about what to do, fast, before either panic or denial sets the strategy.
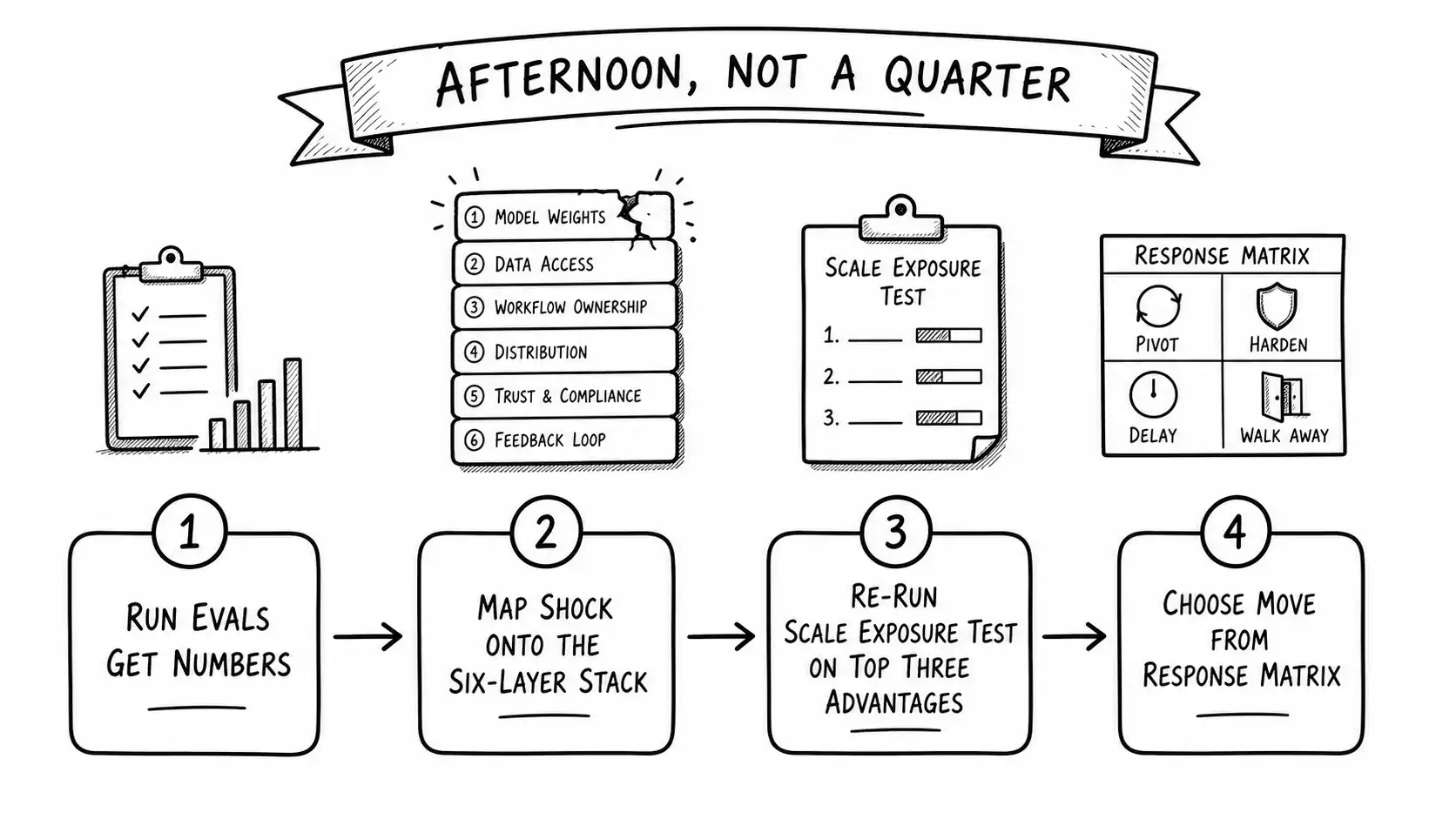
The plan, step by step
Here is the artifact: a capability shock response plan you can run in an afternoon. The order matters. Do not skip to step four.
Step 1: Run your evals against the new model. (Hours, not weeks.)
The first move is measurement, which is why the evals chapter came right before this one. Run the new model against your eval suite and get numbers. Where did it improve, where did it regress, and crucially, did it actually match your system on your tasks, or only on the demo that scared everyone. Half the panic calls I take are about a shock that the eval suite shows is smaller than it felt, because the team was reacting to a headline benchmark, not to performance on their actual tasks. If you do not have an eval suite, this step is "build a minimal one from your last twenty real cases overnight," and the fact that you are doing it under fire is the lesson to build it earlier.
Step 2: Map the shock onto the Moat Migration Stack.
For each layer of the stack, ask: did this shock touch this layer? The shock almost always hits the model-weights layer and frequently the data-access layer if the new model now handles context it could not before. It rarely touches workflow, distribution, trust, or the feedback loop directly, because those are not capability. Draw the stack and mark what the shock hit. This is the step that defuses panic, because it converts "the model does our thing now" into "the shock hit one or two layers and left three or four untouched," which is a survivable picture and an accurate one.
Step 3: Re-run the Scale Exposure Test on your top advantages.
The shock is exactly the event the Scale Exposure Test was designed for. Take your top three claimed advantages and run them through the tree again with the new model in mind. Advantages that were borderline may now be clearly HIGH EXPOSURE. Advantages at the lower layers should still come out LOW EXPOSURE, and confirming that on paper is what lets the team breathe. The test tells you precisely which of your advantages the shock killed and which it did not touch.
Step 4: Decide the move from the Bitter Lesson Response Matrix.
Now, and only now, decide what to do, using the five moves: fight scale, rent scale, compress scale, combine scale, or avoid model-layer competition. For most application companies hit by a shock, the right move is some combination of "rent scale," adopt the new better model immediately because it is now the best engine available, and "combine scale," double down on the lower-layer moats the shock did not touch. The shock that ate your model-layer advantage also gave you a free upgrade to the best model, and the fastest companies treat the shock as both a threat to one layer and a gift to another. The matrix forces you to make an actual decision instead of marinating in the feeling.
A worked shock
Let me run the plan on a concrete, illustrative shock so the steps are not abstract.
Hypothetical: you sell a product that reads long, messy customer documents and answers questions about them. Your differentiation has been a clever chunking-and-retrieval pipeline that worked around the fact that models could not handle very long inputs. On Tuesday, a new model ships that handles a context window many times larger than before, well enough to ingest the whole document directly. Your clever pipeline's reason for existing just got partially erased.
Step 1, run evals: the new model with the long context matches your pipeline on most question types and beats it on a few, but regresses on a class of cross-document questions your pipeline handled because your retrieval pulled from multiple documents the single long context cannot hold all at once. So the shock is real but partial, and you now know exactly where.
Step 2, map onto the stack: the shock hit the model-weights and data-access layers, specifically the part of your pipeline that was compensating for a model limitation. It did not touch your integrations into the customer's document systems, your workflow for routing answers to the right reviewer, your compliance posture for handling sensitive documents, or your feedback loop. One layer hit, four untouched.
Step 3, re-run the Scale Exposure Test: your chunking-pipeline advantage is now clearly HIGH EXPOSURE, the model ate the limitation it worked around. Your integration and workflow advantages remain LOW EXPOSURE. The cross-document capability the new model regressed on is a temporary advantage you should not bank, because the next release will likely close it.
Step 4, choose the move: rent scale, adopt the new long-context model as your engine immediately because it is now better and simpler than your pipeline, retire the chunking complexity you no longer need, redirect that freed engineering effort into deepening the integrations and the feedback loop, and combine scale by keeping a thin retrieval layer only for the cross-document case where it still adds value, knowing that case is borderline. Net result: the shock made your product simpler and cheaper to run, freed engineering capacity, and left your real moats intact. The shock was survivable, and run through the plan, it was even net positive, because you got a free engine upgrade and got to delete code you were maintaining to compensate for a limitation that no longer exists.
That is the difference the plan makes. The same shock, met with panic, looks like "the model killed our core technology." Met with the plan, it looks like "the model upgraded our engine and let us delete a workaround, and our moats are downstairs where it did not reach."
Building resilience before the shock
The plan handles the shock when it lands. Resilience is what you build before, so that when it lands the plan works. Three practices, drawn from earlier chapters, make you shock-resilient.
Keep the model behind a swappable seam, from the open-models chapter, so that adopting the new model in step four is a configuration change and not a rewrite. Companies that wired a specific model deep into their product cannot execute step four quickly, because adopting the new model means a rebuild, so they are forced toward denial by the cost of the alternative. The seam is what makes "rent scale" a same-week move.
Keep a living eval suite, from the evals chapter, so that step one is hours and not weeks. The eval suite is your shock sensor and your shock-response instrument at once. Without it, every shock is a fog you have to clear manually under pressure.
And keep your strategic weight on the lower layers, from the entire middle of the book, so that step two reliably shows the shock hitting layers you did not depend on. A company whose advantages live at the model layer will, every single time, find in step two that the shock hit everything, because everything they had was at the layer the shock hits. A company whose advantages live in workflow, distribution, trust, and the feedback loop will find the shock hit a layer they were already treating as a rented commodity. Resilience is not a reaction. It is the accumulated result of having built down the stack before you needed to.
The standing ritual
Make the response plan a drill, not a panic button. Every time a major model ships, run the plan even if nothing feels threatened, because the discipline of running it when calm is what makes it fast when scared, and because sometimes the shock you should worry about is the one that did not feel scary, the quiet release that closed a gap you did not notice you were depending on. The teams that survive the model era treat each frontier release as a scheduled drill: run evals, map the stack, re-test exposure, decide the move. An afternoon, every few months. It is the cheapest insurance in the business.
What to do differently tomorrow
Write your capability shock response plan down now, while you are calm, as a one-page runbook with the four steps and the names of who runs each one. Pre-decide who runs the evals, who maps the stack, who makes the call. A plan you have to invent during the shock is a plan you will invent badly. A plan on a shared page, rehearsed once when nothing was on fire, is a plan that turns a Tuesday meltdown into an afternoon of disciplined work.
And then go do the unglamorous resilience work the plan depends on: the swappable model seam, the living eval suite, the strategic weight on the lower layers. The plan is only as good as the structure underneath it, and the structure is the whole rest of this book. The final chapter pulls all of it together into a stance you can hold: where to fight scale, where to ride it, and where to build so that the next shock finds you already standing on ground it cannot reach.
Key Takeaways
- A capability shock is a sudden jump in what the general model can do, the lumpy realization of the smooth scaling curve. You cannot predict the timing but you can prepare for the kind.
- The two failure modes are panic, the lazy conclusion that the business is dead, and denial, the lazy conclusion that custom cleverness still wins. The response plan replaces both with disciplined steps.
- Run the plan in order: run your evals for numbers, map the shock onto the Moat Migration Stack, re-run the Scale Exposure Test on your top advantages, then choose a move from the Bitter Lesson Response Matrix.
- Mapping the shock onto the stack is what defuses panic, because it almost always shows the shock hit one or two layers and left the lower three or four untouched.
- The shock that eats a model-layer advantage also hands you a free upgrade to the best engine. Run through the plan, many shocks are net positive: simpler product, freed engineering, intact moats.
- Build resilience before the shock: a swappable model seam makes adoption a config change, a living eval suite makes assessment an afternoon, and strategic weight on the lower layers makes the shock land where you were not depending. Run the plan as a drill on every major release.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.