Evals as Taste, Judgment, and Moat
Why knowing whether your system is actually good is itself a defensible advantage, and how eval discipline compounds where models commoditize.

Research spine
This chapter is grounded in Stanford HAI, 2026 AI Index Report, Stanford HAI, 2025 AI Index Report, and Rich Sutton, The Bitter Lesson.
The durable AI moat is not model cleverness alone; it is the workflow, data, trust, distribution, and evaluation stack that survives scale.
A design review I sat in went sideways the moment someone asked a simple question: how do you know the new version is better? The team had shipped a model change. The demo looked great. Everyone in the room agreed it felt better. And nobody could answer the question, because there was no measurement, only a feeling. Two weeks later a customer reported that the new version had gotten worse at a specific case the old version handled fine, a case nobody on the team used in demos and nobody had in a test set. The new version was better at the things the team happened to look at and worse at the things the customer happened to need. The team had no way to know, because they had no evals.
That gap, between "it feels better" and "it is measurably better on the things that matter," is where one of the most underrated moats in AI lives. Evals, the discipline of systematically measuring whether your system does what your users need, are usually treated as engineering hygiene, a checkbox somewhere below the model and the product. I want to argue that eval discipline is a strategic asset, a form of accumulated taste and judgment about your specific domain that competitors cannot copy and that the bitter lesson, for once, cannot erode. In fact the bitter lesson makes evals more valuable, not less, because in a world where everyone has access to roughly the same models, the company that knows precisely what good looks like on its own tasks wins the ones where it matters.
Evals are encoded judgment about your domain
Start with what an eval actually is, stripped of tooling. An eval is a captured judgment: a set of inputs, the outputs you consider correct or acceptable, and a way of scoring how close a system gets. Building a good eval suite means deciding, concretely and in advance, what good means for your specific use case, on your specific tasks, with your specific edge cases. That decision is judgment, and judgment about a narrow domain is exactly the kind of thing a general model does not have, because the general model was optimized for general loss, not for your definition of good.
This is the quiet inversion the bitter lesson sets up. The model layer commoditizes capability. Everyone gets access to capable models. But capability is not the same as being good at your task by your standards, and the gap between them is filled by knowing precisely what your standards are, which is what an eval suite encodes. The company with the better evals can tell, for any model, open or closed, frontier or small, whether it is actually good enough for their use case. The company without evals is guessing, and in a fast-moving model landscape, guessing is expensive.
Run it through the Scale Exposure Test. Does a larger, cheaper, more tool-capable general model weaken your eval suite? No. A better model makes your eval suite more useful, because now you have a better candidate to measure, and your suite tells you instantly whether the new model is actually an improvement on your tasks or just a better demo. Evals land on LOW EXPOSURE. They are a layer the model cannot reach because they are about your judgment, not the model's capability.
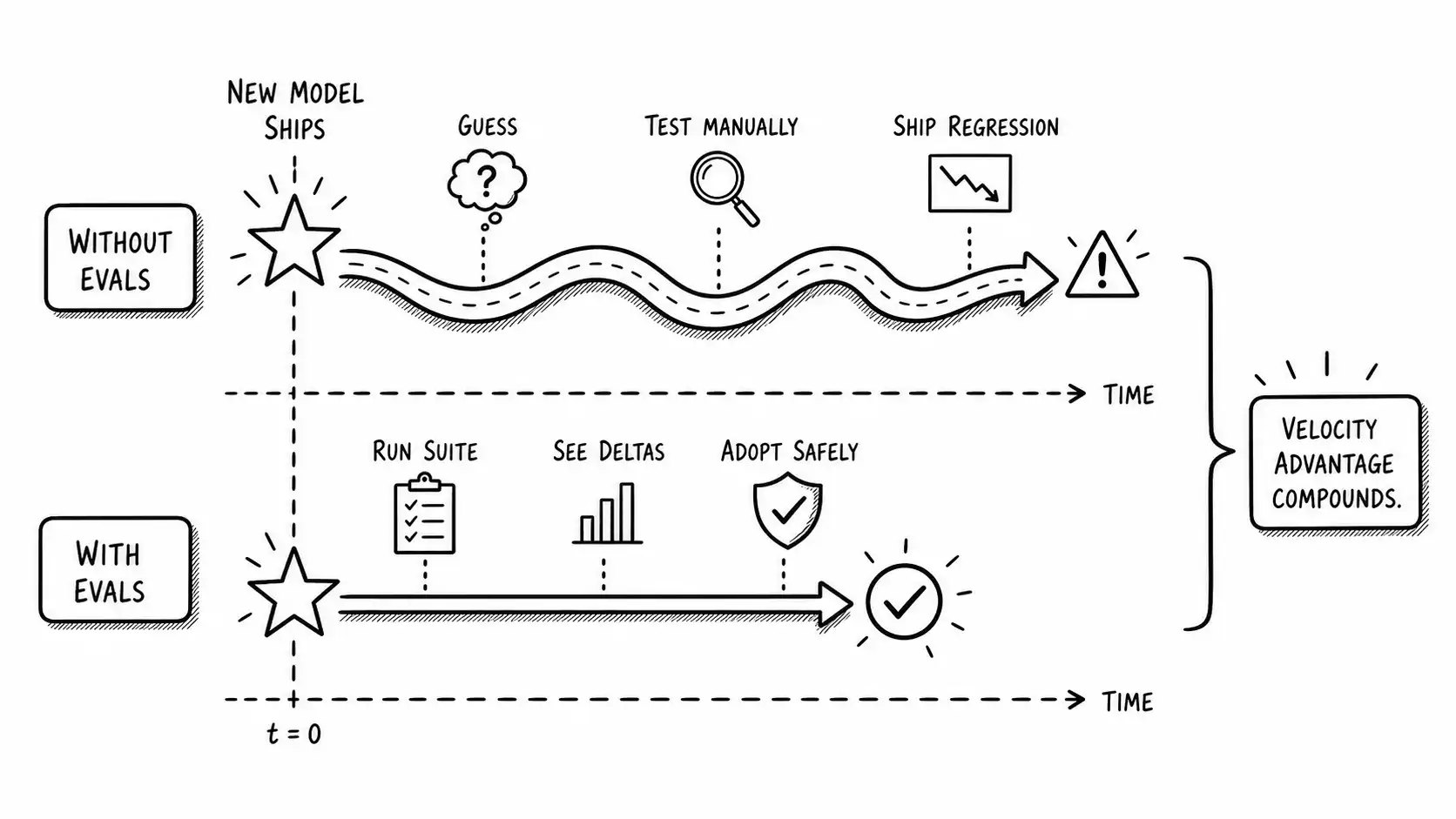
Why eval discipline compounds
Evals are not just durable, they compound, which puts them close to the feedback-loop layer at the bottom of the stack. Every time a user corrects an output in your workflow, that correction is a candidate eval case: a real input, the right output as judged by a competent user on a real task. If you have built the plumbing to capture corrections, your eval suite grows automatically with usage, and it grows specifically in the places where your system was wrong, which are the most valuable places to have test cases.
This is the same machinery as the data moat, viewed through the lens of measurement instead of training. The corrections that make your data moat real are also the cases that make your eval suite sharp. Own the workflow, capture the corrections, and you get two compounding assets from one piece of plumbing: a training signal and a measurement signal. A competitor with a better model but no workflow has neither, because they have no stream of corrections, which means they have no growing eval suite, which means they cannot even reliably tell whether their better model is better on the tasks that matter to your shared customers.
The compounding is the strategic point. A static eval suite is useful. A compounding eval suite is a moat, because the gap between your knowledge of what good looks like on your tasks and a competitor's knowledge widens every day you operate and they do not. This is the eval version of the durable-advantage flywheel: usage produces corrections, corrections sharpen evals, sharper evals let you adopt better models faster and more safely, faster safe adoption produces a better product, a better product produces more usage.
Evals as a model-adoption weapon
Here is the most concrete strategic use of evals, and it is the one that matters most in a world of frequent model releases.
When a new model ships, every company in your category faces the same question: should we adopt it. The company without evals adopts on vibes, which means it either moves recklessly and ships regressions like the team in the opening scene, or moves slowly and cautiously and falls behind, because it cannot trust the new model without a long manual evaluation. Either way, the model release is a source of risk and friction.
The company with a strong eval suite has a completely different experience. A new model ships, they run it against their suite in an afternoon, and they know, with numbers, whether it is better on their tasks, where it improved, and where it regressed. They can adopt the improvement and route around the regression. The model release is a source of advantage, because they can capture the rising tide faster and more safely than anyone who is guessing. This is what it means to ride the bitter lesson instead of fighting it: when capability improves, the company with evals captures the improvement on day one with confidence, and the company without evals either misses it or breaks something adopting it.
This turns eval discipline into a velocity advantage. In a landscape where models improve every few months, the ability to safely adopt each improvement faster than competitors compounds into a meaningful lead, not at the model layer, where everyone has the same models, but at the speed-of-safe-adoption layer, which is a judgment-and-discipline layer competitors cannot shortcut.
What a real eval suite contains
Because "build evals" is easy to say and hard to do well, here is what separates a real eval suite from a token one. This is the artifact: a checklist for whether your evals are doing real work.
- Task-grounded cases, not generic benchmarks. Your evals should be your tasks, with your inputs and your definition of correct, not a public benchmark that measures something adjacent. Public benchmarks tell you about general capability; your evals tell you about your product.
- Hard cases and edge cases, weighted by what hurts. The cases that matter most are the ones where being wrong is expensive: the regulated edge case, the adversarial input, the rare-but-catastrophic mistake. Weight your suite toward where errors cost the most, not toward where they are easy to test.
- Cases sourced from real corrections. The strongest cases come from the feedback loop: real failures on real tasks that real users caught. These are the cases a competitor cannot have, because they happened inside your workflow.
- Both automated scoring and human judgment. Some quality dimensions can be scored automatically; some require a competent human to judge. A serious suite uses automated scoring for scale and human review for the dimensions that resist automation, and is honest about which is which.
- Regression coverage. Every reported failure becomes a permanent test case, so the same mistake cannot ship twice. This is how the suite compounds: it remembers every way the system has been wrong.
- Decision thresholds, not just numbers. A score is useless without a rule for what to do with it. Define in advance what score lets you ship, what score blocks a release, and what regression is unacceptable regardless of average improvement.
Item 2 is the one that distinguishes mature teams. A naive eval suite measures average quality and misses that the average can improve while a critical edge case regresses, which is exactly the failure in the opening scene. The expensive mistakes hide in the tail, and a suite that only watches the average will ship them. Weight the tail.
Evals as taste, made legible
I called this chapter "evals as taste" deliberately, because there is a craft dimension that the checklist undersells. Deciding what good looks like for your domain is an act of taste: a judgment about quality that the best people in your domain hold and that is hard to articulate. The work of building evals is partly the work of making that taste legible, turning the senior practitioner's "no, that output is wrong, here is why" into a captured, scorable case.
This legibility is itself a moat, because it lets you scale the judgment of your best people across your whole system. Without evals, the taste lives in a few heads and is applied inconsistently and does not survive those people leaving. With evals, the taste is encoded, applied uniformly, and compounds as you add cases. You have turned a scarce, tacit human asset into a durable, growing system asset, and you have done it at exactly the layer scale cannot reach, because scale produces general capability and your evals encode your specific, hard-won definition of good.
This is also why I am skeptical of teams that outsource their evals entirely to generic tooling or to a model grading itself. Generic tooling measures generic quality. A model grading itself inherits its own blind spots. The valuable eval suite is the one that encodes your team's specific taste about your specific domain, sourced from your real failures, and that is not something you can buy off the shelf, which is precisely what makes it defensible.
What to do differently tomorrow
If you cannot answer "how do you know the new version is better" with numbers, that is your most urgent gap, more urgent than any model improvement, because without evals every model decision you make is a guess and every model release is a risk instead of an opportunity.
Start small and real: take the last ten failures your users reported and turn them into permanent test cases with a clear definition of the correct output. That is the seed of a compounding suite, and it is sourced from exactly the right place, your real workflow. Then build the plumbing to keep adding cases from corrections automatically, so the suite grows with usage. Within a few model releases you will have what the team in the opening scene lacked: the ability to know, with confidence, whether better is actually better on the things your customers need.
The next chapter shifts from the steady-state disciplines to the discontinuity: what to do when a model improves not gradually but suddenly, the capability shock, and how to have a response plan ready before the shock arrives.
Key Takeaways
- Eval discipline is a strategic moat, not just engineering hygiene. An eval suite is encoded judgment about what good means on your specific tasks, which a general model optimized for general loss does not have.
- The bitter lesson makes evals more valuable, not less: when everyone has access to similar models, the company that knows precisely what good looks like on its own tasks wins where it matters.
- Evals compound through the feedback loop. Every user correction is a candidate eval case, so the same plumbing that builds your data moat sharpens your eval suite, and the gap widens with usage.
- Evals are a model-adoption weapon. A strong suite lets you assess any new model in an afternoon and adopt improvements faster and more safely than competitors who adopt on vibes. This is a velocity advantage that compounds.
- A real suite uses task-grounded cases, weights the expensive tail rather than the average, sources cases from real corrections, mixes automated and human scoring, keeps permanent regression coverage, and defines decision thresholds.
- Evals make your best people's taste legible and durable, turning a scarce tacit asset into a compounding system asset at a layer scale cannot reach. This is not something you can buy off the shelf.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.