Data Moats That Survive Scale
The precise line between data that scale absorbs and data that scale cannot reach, and a checklist for telling which kind you actually have.

Research spine
This chapter is grounded in Stanford HAI, 2026 AI Index Report, Stanford HAI, 2025 AI Index Report, and Rich Sutton, The Bitter Lesson.
The durable AI moat is not model cleverness alone; it is the workflow, data, trust, distribution, and evaluation stack that survives scale.
"We have a data moat" is the most-repeated and least-examined claim in AI pitch decks. I have heard it from companies sitting on genuinely irreplaceable proprietary signal, and I have heard it, word for word, from companies sitting on a pile of text that a frontier model effectively already memorized the general shape of. The phrase is identical. The reality is opposite. This chapter exists to give you the test that separates the two, because betting your company on the wrong kind of data is one of the most expensive mistakes in the field, and it is made constantly.
Let me start with the failure, because the failure is more instructive than the success.
The data moat that wasn't
A company I looked at, anonymized and lightly fictionalized, had spent three years aggregating product descriptions, reviews, and Q and A from across a retail category. Millions of records. They had a real ingestion pipeline, real cleaning, real scale. The pitch was that this corpus was a moat: nobody else had assembled it, so their model, fine-tuned on it, understood the category better than anyone.
Run it through the Scale Exposure Test. Q1, is the advantage that the model is more capable? Partly, and that part is high exposure. But push to Q3: does it rely on something the general model structurally cannot access? Here is where it fell apart. The corpus was assembled from publicly visible web content. A frontier model trained on a broad crawl of the web had effectively already seen the general distribution of how people describe and review products in that category. The company's specific assembly added a thin layer of organization, but the underlying signal, "how is this category discussed," was already inside the general model, because it was on the open internet, which is exactly what the scaling laws consume.
The moat was an illusion created by effort. The team had worked hard, the corpus was real, and the work felt like it should produce a defensible asset. But effort is not the test. Inaccessibility to scale is the test. Their data was, in the sense that mattered, already accessible to scale, because scale ate the internet. They had paid three years to assemble a private copy of something the general model had a public copy of.
The line: data scale cannot reach
The distinction that matters is not public versus private in the legal sense. It is reachable-by-scale versus unreachable-by-scale. Some private data is still reachable in the sense that the model has seen enough equivalent examples to generalize to it. Some data is genuinely unreachable, and that is where data moats live.
Unreachable data has a few signatures. It is generated inside a workflow that does not exist on the public internet. It reflects the live, current state of a specific system rather than a static historical fact. It includes the outcomes and corrections that only the operator of a process sees. It is the kind of thing that, no matter how large the general model gets, the general model cannot have, because it was never anywhere the crawl could reach and it keeps being created freshly inside your product.
A hospital's current imaging queue is unreachable. The corrections a specific underwriting team made to model outputs last week are unreachable. The actual outcomes of decisions made inside a workflow, who churned, which claim was fraudulent, which lead closed, tied to the inputs that produced them, are unreachable. None of this is on the web. None of it generalizes from web text. All of it keeps being produced as a byproduct of the workflow operating. That last property, that it is produced continuously by the workflow, is what connects data moats to the feedback-loop layer at the bottom of the stack.
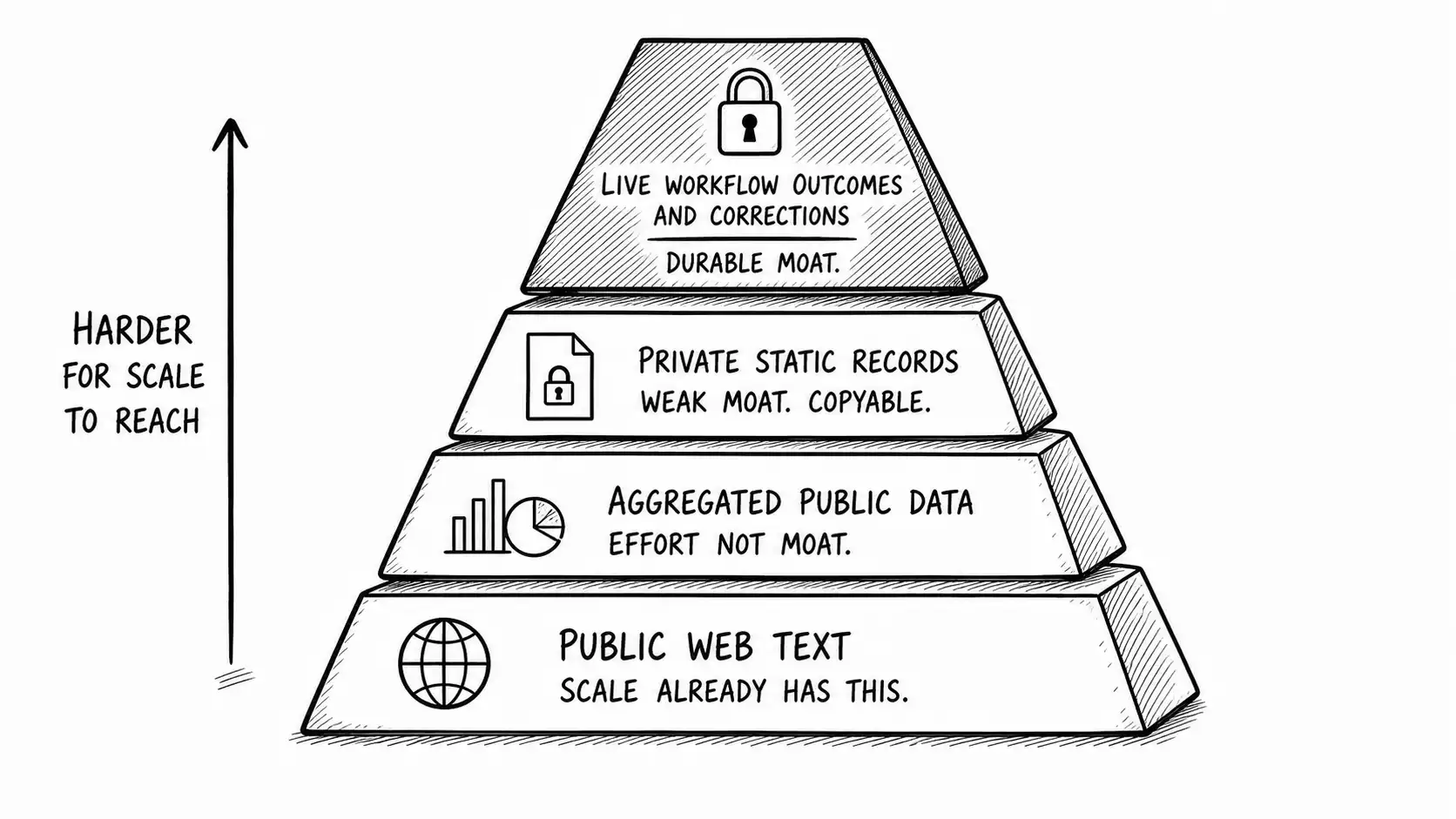
The data moat quality pyramid
The image above is a framework worth stating in prose, because it is the spine of the chapter. Data sits on a pyramid, and only the top is a moat.
At the bottom is public web text. Scale already has it. Assembling more of it is not a moat, it is a redundant copy. This is where the retail company lived.
Above that is aggregated public data, where you have done real work to collect, clean, and structure publicly available information. This is effort, and effort has value, but it is not a moat, because a competitor or a model can reach the same underlying signal. The aggregation is copyable, slowly by a competitor and instantly by a model that already generalized the pattern.
Above that is private static data: records that are genuinely private but fixed, like a historical dataset you licensed exclusively or built once. This is a weak moat. It is private, so the model does not have it, which is real. But it is static, so it does not compound, and exclusivity can lapse, be replicated, or be made irrelevant by a model that gets good enough without it. A static private dataset is a moat with a slow leak.
At the top is live workflow data: the outcomes, corrections, and current-state signal continuously produced inside a workflow only you operate. This is the durable moat. It is private, it is unreachable by scale, and crucially it compounds, because every day of operation produces more of it and widens the gap. This is the only tier where the data moat genuinely survives scale, and it survives precisely because it is not really a data asset, it is the exhaust of an owned workflow with a closed feedback loop.
The strategic instruction falls right out of the pyramid: if your data lives below the top tier, do not bank it as a moat, and if you want a data moat, build the workflow that produces top-tier data. You do not acquire a data moat. You operate one into existence.
The data moat quality checklist
Here is the artifact. Score your dataset on each question. The more "yes" answers concentrated at the top of the list, the more real your moat.
- Is the data produced inside a workflow you operate, rather than collected from outside?
- Does it include outcomes or corrections, not just inputs? (The label is worth more than the example.)
- Does it reflect current, live state rather than static history?
- Does it keep accumulating automatically as the product is used?
- Is it tied to specific decisions, so it teaches the model something about results, not just patterns?
- Would a frontier model, having read the public web, still not be able to produce equivalent value without it?
- Is it legally and contractually yours to use for improvement, with the right consents and agreements?
- Could a well-funded competitor assemble an equivalent within a year? (A "yes" here weakens the moat.)
Question 6 is the Scale Exposure Test in disguise, and it is the one that disqualifies most claimed data moats. Question 2 is the one teams underweight: the model has seen a billion examples of input text, what it has not seen is which outputs were correct in your specific context, and the correction is the scarce, valuable signal. Question 7 is the one that gets companies into legal trouble, and it is non-negotiable: a data moat built on data you do not have the right to use for training is not a moat, it is a liability with a countdown timer. Secure the consents and the data-processing agreements before you build on the data, not after.
Why corrections are the scarce thing
I want to dwell on question 2, because it reframes what a data moat even is.
A frontier model trained on the web has seen astronomical quantities of input-shaped data: text, code, images, the raw material of tasks. What it has seen far less of, and in your specific domain essentially none of, is the supervision signal that says which output was right in a particular real context. That signal is expensive and private because it only exists where someone competent looked at a model output on a real task and said yes or no or fixed it. That someone is your user, inside your workflow.
So the durable data moat is not "we have a lot of data." It is "we have a lot of judgments about outputs on real tasks, captured in a form that improves the system, and we keep generating more of them faster than anyone can copy." That is a fundamentally different asset, and most companies claiming a data moat have the first thing, lots of inputs, and not the second thing, lots of judgments. The second thing is what survives scale, because scale produces capability and your users produce verdicts, and verdicts on your specific tasks are the one input the scaling laws cannot manufacture.
This is also why the data moat and the feedback loop are the same thing viewed from two angles. The data moat is the asset. The feedback loop is the machine that produces it. You cannot have the durable asset without operating the machine, which is why "buy a dataset" almost never produces a real moat and "own a workflow that generates judgments" almost always can.
When a static data moat is still worth having
I do not want to be absolutist, because there are real cases where a static private dataset matters.
If your domain is one where the underlying reality changes slowly and the data is genuinely hard to obtain, a static private dataset can hold value for a meaningful period. Certain scientific, industrial, or proprietary-instrument datasets fall here: data that is private, expensive to generate, and not the kind of thing a web crawl approximates. In those cases the static dataset is a real, if non-compounding, advantage, and the right move is to treat it as a runway rather than a permanent moat. Use the runway to build the compounding layers before the static advantage erodes.
The test for whether your static dataset is worth banking is question 6 again: would a frontier model still be unable to produce equivalent value without it. For a slow-moving, hard-to-obtain scientific dataset, the answer can genuinely be yes for years. For a pile of web-adjacent text, the answer is no today. The same checklist sorts both, which is the point of having a checklist instead of a vibe.
The interaction with privacy and consent
A note that the contract and my own scars both insist on: the most valuable data moats are made of exactly the data that is most sensitive, because unreachable-by-scale and sensitive are nearly the same category. Customer records, corrections by named staff, outcomes tied to individuals: this is the data that is both most valuable and most regulated.
This is not a reason to avoid it. It is a reason to engineer the consent, minimization, and access controls properly from the start, because a data moat that you cannot legally use, or that exposes customer PII, is worse than no moat. Treat the right to use the data for improvement as a feature you have to earn from the customer through clear agreements, not an entitlement. The companies that built durable, defensible data moats did the legal and trust work in parallel with the technical work. The ones that skipped it built an asset they eventually could not touch. This is where the data layer and the trust-and-compliance layer of the stack reinforce each other: the consent that makes your data usable is also part of the trust posture that is itself a moat.
What to do differently tomorrow
Pull your actual dataset onto the pyramid. Be honest about which tier it sits on. If it sits below the top, stop calling it a moat in your own internal language, because the internal story you tell shapes where you invest, and a team that believes it has a data moat it does not have will under-invest in building the real one.
Then design, explicitly, for the top of the pyramid. Find the place in your workflow where a user makes a judgment about a model output, and engineer that judgment into a captured, consented, structured signal that flows back into your evals and your product. That single piece of plumbing, the capture of corrections inside an owned workflow, is the most valuable data-engineering investment most AI companies can make, and almost nobody prioritizes it, because it does not feel like building a model. It is not. It is building the machine that makes your data moat real.
The next chapter goes to the layer that produces the data moat in the first place and turns out to be where most durable AI businesses actually live: the workflow.
Key Takeaways
- "We have a data moat" is the most-repeated and least-examined claim in AI. The test is not effort or volume, it is whether the data is reachable by scale.
- Data sits on a pyramid: public web text and aggregated public data are not moats, private static data is a weak leaking moat, and live workflow outcomes and corrections are the only durable tier.
- The scarce signal is not inputs, which the model has in abundance, but judgments: which output was correct on a real task in your context. The model cannot manufacture verdicts on your specific tasks.
- A data moat and a feedback loop are the same thing from two angles: the asset and the machine that produces it. You operate a data moat into existence rather than acquiring one.
- Static private datasets can be real but non-compounding advantages in slow-moving, hard-to-obtain domains. Treat them as runway and build the compounding layers before they erode.
- The most valuable data is the most sensitive. Engineer consent, minimization, and the legal right to use it for improvement from the start, or you build an asset you cannot touch.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.