Small Models as Economic Response, Not Ideology
When compressing scale into a small model is a sound financial move, when it is a trap, and how to decide with a cost model instead of a belief.

Research spine
This chapter is grounded in Stanford HAI, 2026 AI Index Report, Stanford HAI, 2025 AI Index Report, and Rich Sutton, The Bitter Lesson.
The durable AI moat is not model cleverness alone; it is the workflow, data, trust, distribution, and evaluation stack that survives scale.
There is a tribe that treats small models as a moral cause, the way another tribe treats open weights. They will tell you that small models are the future, that the giant models are wasteful, that the real craft is in efficiency. There is a tribe that treats small models as a sign of weakness, a thing you settle for when you cannot afford the frontier. Both tribes are making a financial decision with their identity instead of a spreadsheet, and both will occasionally be expensively wrong.
Small models are neither a virtue nor a compromise. They are an economic response to the bitter lesson. The bitter lesson commoditizes capability at the model layer and compresses your margin there, because anyone can call a good general model. A well-chosen small model is one way to rebuild margin, by doing a known task at a fraction of the cost and latency of calling a frontier model for everything. That is the entire case, and it is a case you make with numbers, not beliefs.
This chapter is the most arithmetic in the book on purpose, because the small-model decision is one of the few in AI strategy that reduces cleanly to a cost model, and a team that runs the cost model will make a better decision than a team that runs a manifesto.
What "small model" means here
By small model I mean a model you can run cheaply, often self-hosted, often distilled or fine-tuned for a specific task, that does that task well enough while costing far less per request and responding faster than a general frontier model would. The smallness is in the cost and latency, not in some abstract purity. A small model that does your one task at acceptable quality for a tenth of the cost is a financial instrument, and you should evaluate it like one.
The connection to the Chinchilla result from the scaling-laws chapter is direct. Once we learned that compute-optimal training scales parameters and data together, and that smaller well-trained models can match much larger wasteful ones, it became clear that you do not always need a giant model to hit a given quality bar on a given task. For a narrow task with the right training, a small model can reach the quality you need, and then the only remaining question is the economics, which is a question of arithmetic.
The Bitter Lesson Response Matrix, applied
Recall the five honest moves available when scale comes for a layer: fight scale, rent scale, compress scale through small models, combine scale with proprietary workflow or data, or avoid model-layer competition. Small models are the "compress scale" move, and the matrix is useful because it forces you to see compression as one option among five rather than a default.
| Move | What it means | When it is right |
|---|---|---|
| Fight scale | Train and maintain your own frontier model | Almost never for an application company; only if frontier capability is your entire product and you can fund it indefinitely |
| Rent scale | Call a frontier API | When you need the latest capability and volume or cost is not the binding constraint |
| Compress scale | Run a small model for the task | When the task is narrow, volume is high, and cost or latency dominates |
| Combine scale | Use a general model plus your proprietary workflow and data | The default durable position; the model is rented, the moat is below it |
| Avoid model competition | Compete entirely on lower layers | When your advantage is distribution, trust, or compliance and the model is a commodity input |
Notice that "compress scale" is not opposed to "combine scale." The mature architecture usually does both: a small model handles the high-volume narrow work cheaply, a frontier API handles the requests that genuinely need the latest capability, and the whole thing sits underneath a proprietary workflow that is the actual moat. The matrix is not a menu where you pick one. It is a set of moves you sequence and combine.
The cost model that should decide this
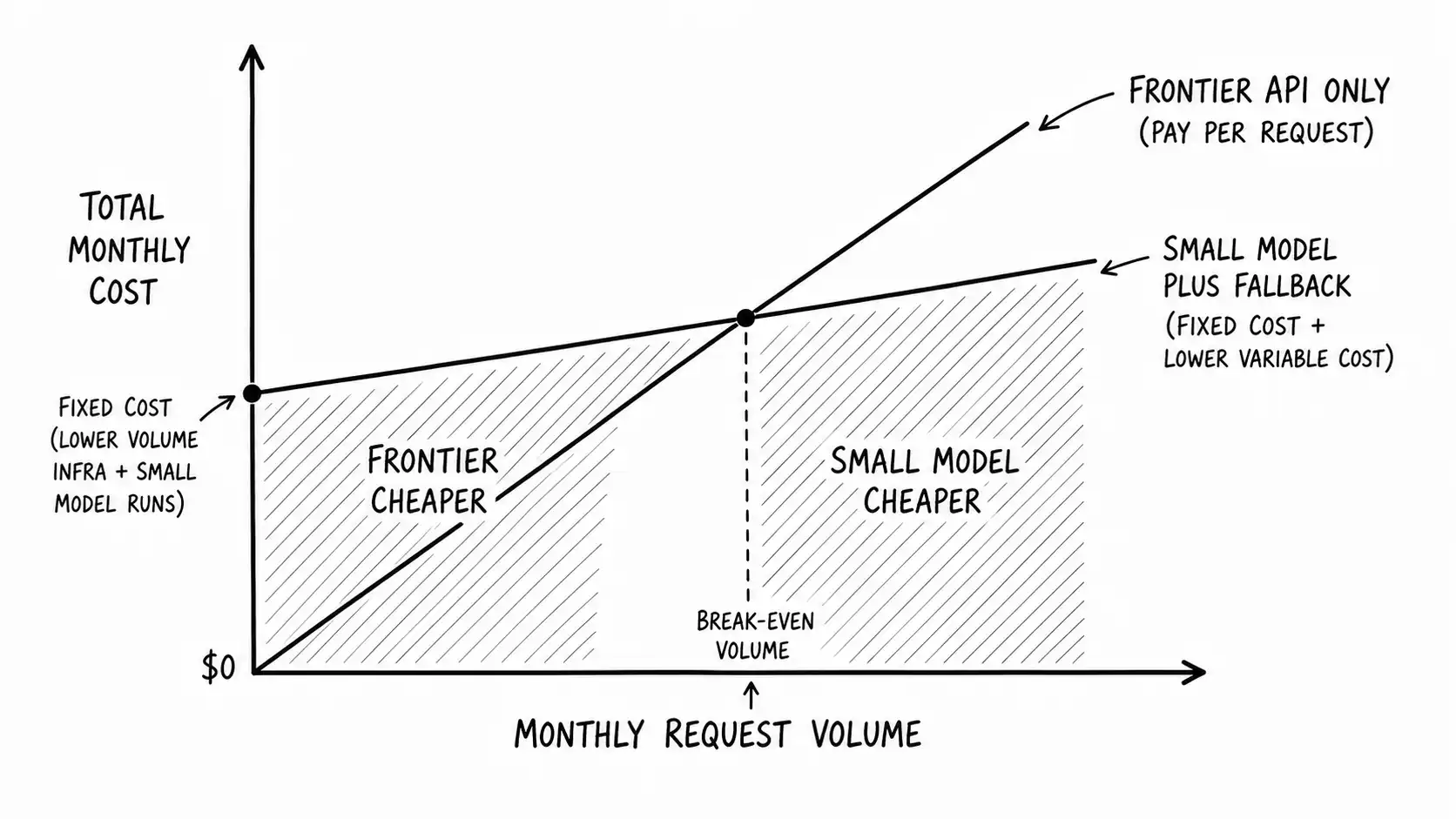
Here is the arithmetic. This is a simplified model, label it as such, but it captures the decision. Consider routing a workload either entirely to a frontier API or to a self-hosted small model, and compare total cost.
Define:
V= requests per monthCf= cost per request on the frontier APICs= marginal cost per request on the small model (compute only)Fixed= monthly fixed cost of running the small model (hosting, ops, the engineering time to maintain it, amortized)Quality gap= the fraction of requests the small model handles acceptably; the rest must fall back to the frontier API
Frontier-only monthly cost:
Cost_frontier = V * CfSmall-model-with-fallback monthly cost:
handled_by_small = V * Quality_fraction
fallback = V * (1 - Quality_fraction)
Cost_small = Fixed + (handled_by_small * Cs) + (fallback * Cf)The small model wins when Cost_small < Cost_frontier. Rearranged, the small model is worth it roughly when the savings on the handled requests exceed the fixed cost:
(V * Quality_fraction) * (Cf - Cs) > FixedThis little inequality is the whole decision, and it teaches three things immediately.
First, volume is the dominant variable. At low V, the fixed cost dominates and the frontier API wins, because you cannot amortize the ops burden over enough requests. At high V, the per-request savings dominate and the small model wins. There is a break-even volume, and you should compute it before you build anything. Many teams build a small model at a volume where the frontier API was cheaper all-in once you counted the engineering time, and they did it because small felt thrifty. Thrift that ignores fixed cost is not thrift.
Second, the quality fraction matters as much as the cost. If the small model only handles 60 percent of requests acceptably and 40 percent fall back to the frontier, you are paying the fixed cost plus most of the frontier cost anyway, and the math often does not clear. The small model has to be genuinely good enough on a large fraction of the volume, which is an evals question, which is the subject of the next chapter and not a coincidence.
Third, the fixed cost is mostly people, not servers. The compute to run a small model is cheap. The expensive part is the engineering time to build it, the ongoing burden to maintain it, retrain it, monitor it, and keep it from drifting. Teams chronically underestimate this term because servers have a price tag and engineering time does not show up on the same invoice. Put a real number on the people. It is usually the term that decides the inequality.
The trap: small models depreciate too
Here is the part the small-model tribe does not put on the slide. A small model you trained for a task is, like any model-layer artifact, exposed to the compute curve, just from a different direction.
The frontier API gets cheaper over time, sometimes dramatically, as labs optimize and compete. Every price drop on the frontier moves the break-even volume to the right, which means your small model has to handle more volume to stay worth it. A small model that cleared the inequality this year can fail it next year not because it got worse but because the frontier got cheaper. Run the Scale Exposure Test on "we save money with a small model": Q2, does it depend on the frontier being expensive, yes, partly, MEDIUM exposure on the cheaper vector. The cost advantage is real but it is being eroded by the same curve that erodes everything at the model layer.
This is why small models are an economic tactic and not a moat. They can improve your margin, which is valuable and worth doing when the arithmetic clears, but they do not give you a defensible position, because the basis of the saving, the gap between frontier cost and small-model cost, is being squeezed by frontier price drops. Treat the small model as a margin instrument you re-evaluate every time frontier pricing moves, not as a permanent advantage you build once and forget.
The combine-scale move is what makes the small model durable, and it is durable for reasons that have nothing to do with the model. A small model running inside a workflow you own, fed by proprietary data, producing outputs that flow into your integrations, is defensible because of the workflow and the data, not because of the model. The small model is the cheap engine; the moat is the car around it. Build the car.
When small models clearly win
To be balanced, here is when the arithmetic reliably favors small models, so the chapter is not all caution.
High-volume, narrow, latency-sensitive tasks are the sweet spot. Classification, extraction, routing, ranking, simple structured generation at scale, the kind of task you do millions of times where a frontier call per request would be both slow and expensive. Here the volume is high enough to amortize the fixed cost, the task is narrow enough that a small model hits the quality bar, and the latency advantage of a local small model is itself worth money in the product. In these cases the inequality clears comfortably and the small model is plainly the right call.
Privacy and residency constraints also favor small models independent of cost, because running a small model you control inside your environment can satisfy requirements an external API cannot. Here the small model is not really an economic decision, it is a compliance and control decision, and it ties back to the trust-and-compliance layer: sometimes the small model is the only model you are allowed to run on the data, and the cost model is secondary.
What to do differently tomorrow
Before you build a small model, build the spreadsheet. Estimate V, Cf, Cs, the realistic quality fraction, and an honest fully-loaded Fixed that includes the engineering time to build and maintain it. Compute the break-even volume. If you are below it, do not build the small model, rent the frontier and spend the saved engineering time down the stack. If you are above it, build it, and put a recurring reminder to re-run the spreadsheet every time frontier pricing changes, because the break-even moves.
And whichever way the arithmetic falls, do not let the small model become an identity. It is an engine, not a moat. The moat is the workflow, the data, and the trust around it. Use the small model to widen your margin so you can fund the durable layers, which is the only reason margin matters in the first place.
The next chapter goes to the layer that decides whether any of this works: evals, the discipline of knowing whether your system is actually good, which turns out to be a form of taste, judgment, and yes, a moat.
Key Takeaways
- Small models are an economic response to the bitter lesson, not an ideology or a compromise. They rebuild margin where scale compressed it, and the decision is arithmetic, not belief.
- They are the "compress scale" move in the Bitter Lesson Response Matrix, best combined with "combine scale": a small model for high-volume narrow work, a frontier API for requests needing the latest capability, both under a proprietary workflow.
- The cost decision reduces to a single inequality: the per-request savings on handled volume must exceed the fully-loaded fixed cost. Volume is the dominant variable and there is a break-even you should compute before building.
- The fixed cost is mostly people, not servers, and teams chronically underestimate it. Put a real number on the engineering time to build and maintain the model.
- Small models depreciate too: frontier API prices keep falling, moving the break-even rightward. The cost advantage is real but eroding, so a small model is a margin tactic you re-evaluate, not a moat.
- Small models clearly win on high-volume narrow latency-sensitive tasks and where privacy or residency constraints rule out an external API. The moat is always the workflow and data around the model, never the model.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.