Introduction: The Update That Erased a Year
Why the bitter lesson is a business problem, not just a research observation, and what this book promises.

Research spine
This chapter is grounded in Stanford HAI, 2026 AI Index Report, Stanford HAI, 2025 AI Index Report, and Rich Sutton, The Bitter Lesson.
Key Takeaways
- Introduction: The Update That Erased a Year is a chapter about scale, open models, and durable AI moats, not a generic AI adoption note.
- The operating rule is to build around workflow, data, trust, distribution, and evaluation where scale still needs product context.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
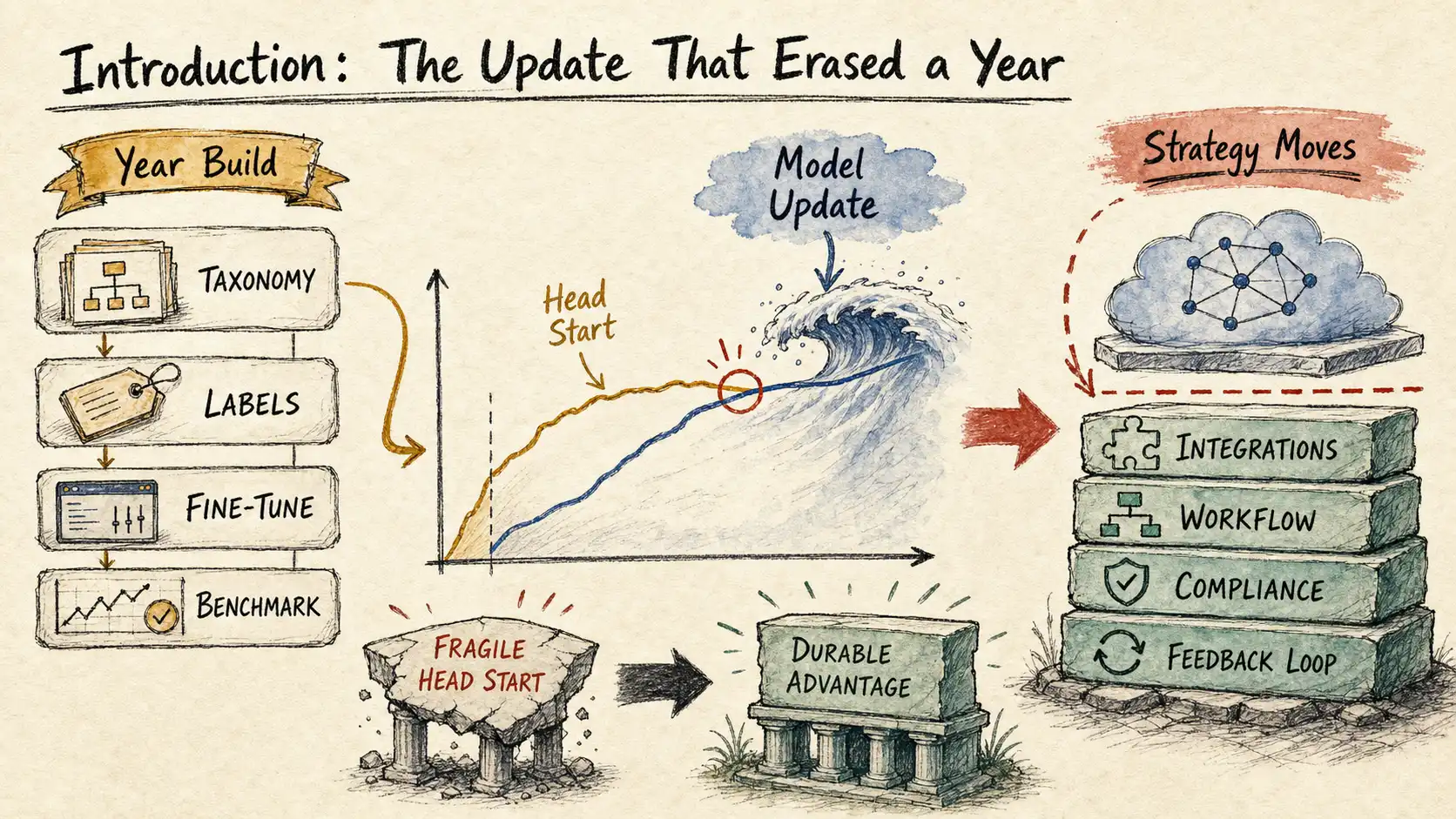
The durable AI moat is not model cleverness alone; it is the workflow, data, trust, distribution, and evaluation stack that survives scale.
A founder I advised spent most of 2024 building a specialized model. Call the company Verant. It read radiology reports and extracted structured findings: laterality, measurements, follow-up recommendations, the small clinical facts that downstream systems need. The team had real domain people. They fine-tuned an open base model on a curated corpus of de-identified reports, wrote a careful taxonomy, built a labeling pipeline, and shipped something that genuinely beat the general models of the day on their internal benchmark. They had a deck with a chart. The chart showed their model ahead.
For about ten months, the chart was true.
Then a frontier lab shipped a routine model update. Not a research milestone, not a press cycle, just a Tuesday version bump with a new system prompt convention and a slightly larger context window. Someone on the Verant team ran the old eval out of habit. The general model, with no fine-tuning, no domain taxonomy, no labeling pipeline, and a prompt written in twenty minutes, scored within two points of Verant's specialized system. On a couple of report types it scored higher. The thing that had taken a year and most of the seed round to build had been matched by an API call that cost a fraction of a cent and required no machine learning team at all.
The founder did not call me to ask what went wrong technically. Technically, nothing went wrong. The pipeline worked. The founder called to ask whether the company still had a reason to exist.
This is the bitter lesson, and it has a business version
In 2019, Richard Sutton published a short essay called The Bitter Lesson. Its central claim is blunt: "The biggest lesson that can be read from 70 years of AI research is that general methods that use computation are ultimately the most effective, and by a large margin." Sutton's argument is that researchers repeatedly try to build human knowledge into their systems, get a short-term win, and then watch general methods that simply use more computation, mainly search and learning, blow past the handcrafted approach as compute gets cheaper. Chess fell to search, not to encoded grandmaster heuristics. Speech recognition fell to statistical learning, not to phonetic rules. Computer vision fell to learned features, not to hand-designed edge detectors.
That is a research observation. It was meant for people choosing what to work on in a lab. But it has migrated, almost without anyone deciding it should, into the operating reality of every company building on top of AI. The Verant story is the bitter lesson wearing a cap table. The team encoded knowledge into a system, got a real short-term advantage, and then a general method that use more computation arrived and ate the advantage. The essay predicted the outcome twenty years before the company existed.
What Sutton did not do, because it was not his job, is tell you what to do about it when your payroll depends on the answer. That is what this book is for.
The enemy of this book is the lazy conclusion
There are three lazy conclusions that people reach after watching a story like Verant's, and all three are wrong.
The first lazy conclusion is that scale makes every application company defenseless. If the frontier model can match your specialized model overnight, the reasoning goes, then nothing built on top of a model is safe, so just buy index funds and go home. This is wrong because it confuses the model layer with every other layer. Verant's model was matched. Verant's contracts with hospital integration vendors, its compliance posture, the workflow its users had built habits around, the feedback loop from corrected outputs, none of those were matched by a version bump. Some of them were never exposed to the model layer at all.
The second lazy conclusion is the opposite: that custom cleverness always wins, that a team with enough domain expertise can out-engineer scale. This is the conclusion that built Verant's model in the first place. It is comforting because it flatters the team's skill, and it is wrong because it ignores the entire history Sutton documented. Cleverness at the model layer has a shelf life measured in model releases.
The third lazy conclusion is that the only real question is open models versus closed models, and once you pick a side the strategy is settled. This is the conclusion of people who read one good blog post and stopped. Open versus closed is a real and important question, and this book treats it seriously in its own chapter, but it is one variable in a larger system. A company can win or lose on open models. A company can win or lose on closed APIs. The choice of weights is not the choice of strategy.
The thesis of this book is the thing all three lazy conclusions miss:
The bitter lesson is not that strategy is dead. It is that strategy must move to the layers scale does not automatically solve.
What scale solves and what it does not
Here is the motif you will see in every chapter, stated different ways:
Scale eats cleverness at the model layer, then forces cleverness to migrate elsewhere.
Scale is structurally advantaged at producing raw capability: better reasoning, broader knowledge, more reliable extraction, cheaper inference per token. If your advantage lives there, scale will come for it, and you will not win that fight by working harder. The compute curve is not your competitor. It is the weather.
But there are things a larger, cheaper, more tool-capable general model does not automatically get. It does not get your customer's messy internal data unless someone wires it in. It does not get the trust a regulated buyer extends to a vendor they have audited. It does not get the integration depth into systems that took eighteen months to certify. It does not get the user's muscle memory. It does not get the proprietary feedback loop that comes from watching real users correct real outputs in a real workflow. It does not get the right to operate under a compliance regime it has never been audited against.
Those are the layers where strategy still lives. The work of this book is to map them precisely, to give you tests for telling a durable layer from a doomed one, and to give you a small set of frameworks you can run against your own roadmap.
What this book is not
I want to be precise about the boundaries, because half of staying useful is refusing to be the wrong book.
This is not a scaling-law textbook. I will explain scaling laws in plain English in one chapter, with enough rigor to make decisions, and then I will leave the math to the people who wrote the papers, who are linked.
This is not a prediction market for model labs. I will not tell you which lab wins in 2028. I do not know, and people who claim to know are selling something.
This is not an open-source manifesto. I am not on a team. Open models are a tool and a strategic pressure, treated as such.
This is not a claim that product, data, UX, or distribution stopped mattering. The reverse. The argument is that they matter more, because they are where the defensible work moved.
And this is not a generic AI strategy book that could have been written about any technology by changing the nouns. Every framework here is built specifically around the asymmetry Sutton identified: the model layer gets commoditized by compute on a predictable schedule, and the layers around it do not.
The frameworks you will carry out of this book
Four tools recur throughout, introduced where the argument needs them and reused in different contexts so they harden into instinct.
The Moat Migration Stack is a six-layer view of where defensibility can live: model weights, data access, workflow ownership, distribution, trust and compliance, and the feedback loop. The point of the stack is that defensibility does not vanish under scale, it migrates down the stack toward the layers compute does not touch.
The Scale Exposure Test is a single question you run against any claimed advantage: would a larger, cheaper, or more tool-capable general model weaken this? If yes, you are standing on melting ice.
The Bitter Lesson Response Matrix gives you the five honest moves available when scale comes for a layer: fight scale, rent scale, compress scale through small models, combine scale with proprietary workflow or data, or avoid model-layer competition entirely.
The Durable Layer Map enumerates the properties that resist scale: trust, latency, cost, domain data, integration depth, compliance posture, user habit, and eval discipline.
You do not need to memorize these now. You will meet them in context, and by the end they should feel like part of how you read your own business.
Who I am writing for
I am writing for the founder choosing between a frontier API, an open model, and a proprietary model, who needs to know which choice is a moat and which is just a bill. For the CTO being asked whether fine-tuning is a defensible asset or a depreciating one. For the investor trying to tell a durable AI company from one that is renting a temporary capability gap. For the product leader designing workflows that have to survive the next model release. And for the platform lead allocating a budget across models, data, evals, UX, and distribution, who has to decide what to own, what to rent, and what to never build.
How to read this book
Read the introduction and the conclusion as bookends, and read the chapters in between in order the first time, because the frameworks build. After that, treat it as a reference. When a frontier model update lands and your team starts asking whether the company still has a reason to exist, the chapter on capability shocks has a response plan you can run in a single afternoon.
Verant survived, by the way. Not because their model came back, it never did, but because they figured out which layers of their business the update had not touched, and moved their effort there fast. That migration is the whole subject of this book.
Let us start where Sutton started: with seventy years of clever people losing to compute, and with what they should have learned.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.