Seventy Years of Clever People Losing
The historical pattern Sutton documented, told as a sequence of teams who built knowledge in and watched compute win.

The durable AI moat is not model cleverness alone; it is the workflow, data, trust, distribution, and evaluation stack that survives scale.
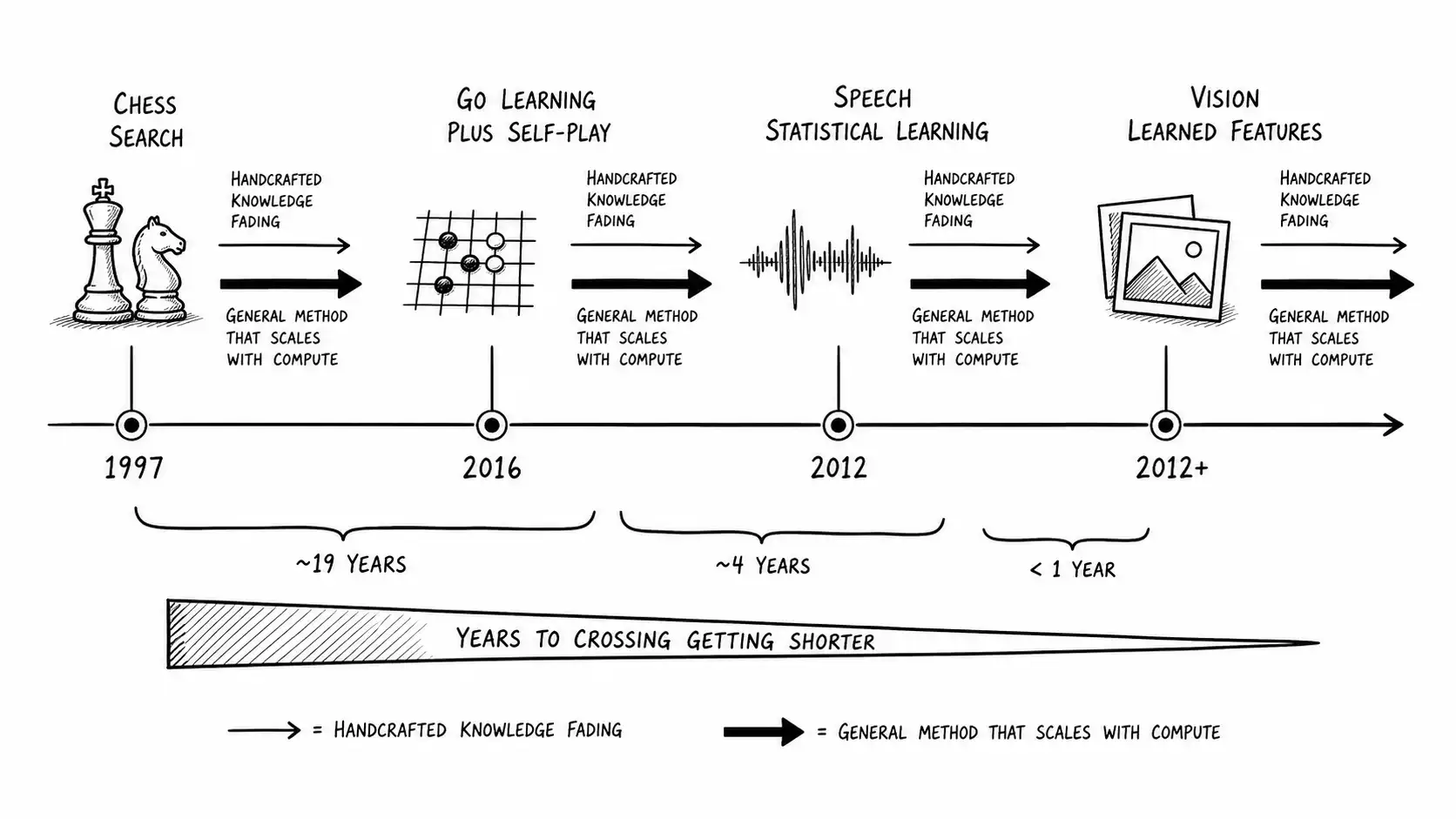
In May 1997, a chess machine beat the reigning world champion under tournament conditions for the first time, and the thing that won was, by the standards of its own field, almost embarrassingly unintelligent. IBM's Deep Blue did not understand chess the way Garry Kasparov understood chess. It did not have a theory of pawn structure or a sense of initiative. It had specialized hardware that let it evaluate on the order of two hundred million positions per second and a search that looked many moves ahead. There were hand-tuned evaluation features in there, contributed by grandmasters, but the engine of the victory was brute search over a vast tree of possibilities, made affordable by hardware.
The chess research community had spent decades pursuing a different dream. The dream was to encode chess knowledge, the patterns and principles that strong human players use, into the machine so it could play the way a master thinks. That was the elegant path, the one that would have taught us something about intelligence. The path that won was the unglamorous one. It looked a lot of moves ahead, very fast. Sutton, in The Bitter Lesson, reports that many chess researchers viewed the search-based victory with something close to disappointment, because it did not vindicate the human-knowledge program they believed in.
This is the pattern. A field decides that the way to make a machine good at a task is to give it human knowledge about the task. The field invests years in capturing that knowledge. Then a general method that simply uses more computation, almost always some form of search or learning, arrives and wins by a margin that makes the knowledge-engineering look like a detour. The people who built the knowledge are not stupid. They are usually the smartest people in the room. They lose anyway, and they lose on a schedule set by the cost of compute, not by the cleverness of their competitors.
The pattern, repeated until it stops being a coincidence
Go was supposed to be different. The board is larger than a chessboard, the branching factor is enormous, and brute-force search of the kind that beat Kasparov was understood to be hopeless. For years this was offered as evidence that Go would require genuine machine understanding, some encoding of the intuition that strong players describe and cannot fully articulate. Then in 2016, DeepMind's AlphaGo beat Lee Sedol four games to one. AlphaGo did use human games to bootstrap, but its strength came from a combination of deep neural networks trained partly by self-play and Monte Carlo tree search, a general learning-plus-search recipe scaled with compute. Its later sibling, AlphaGo Zero, discarded the human games entirely and learned from self-play alone, and was stronger. The encoded human knowledge turned out to be a crutch the system did better without.
Speech recognition tells the same story on a longer timeline. Early systems tried to build in linguistic knowledge: phonemes, the rules of how sounds combine, models of the vocal tract. They worked in narrow conditions and fell apart in the noisy real world. The systems that won were statistical: hidden Markov models trained on large amounts of data, and later deep neural networks trained on far larger amounts. The knowledge-based linguists did not become wrong about linguistics. They became irrelevant to the engineering of a recognizer, which is a different and more painful thing.
Computer vision is the cleanest example because the break is so sharp and so recent. For years, the way you built a vision system was to hand-design features: edge detectors, corner detectors, descriptors with names attached to the researchers who invented them. You engineered the features and then ran a classifier on top. In 2012, a deep convolutional network called AlexNet won the ImageNet competition with a top-5 error rate of about 15.3 percent against a runner-up near 26 percent. In a field where progress was measured in fractions of a percent, this was not an improvement, it was a regime change. The network did not use the hand-designed features. It learned its own from data, given enough compute to do so. Within a year, essentially the entire competition had switched to learned features. A subdiscipline's worth of carefully engineered feature design became, more or less overnight, history.
I am listing these not to celebrate compute but to make a point that should make a strategist uncomfortable: in every one of these cases, the losing side was the side that knew the most about the domain. Knowing the most about the domain is precisely the position most application companies believe is their moat. The history says that the domain knowledge, when it is encoded into the system as the primary advantage, is the thing scale is best at replacing.
Why this keeps happening, mechanically
It is worth understanding the mechanism, because the mechanism is what makes the pattern predictable rather than a run of bad luck.
Human-knowledge approaches work by constraining the search space. The expert tells the system what to pay attention to, which cuts down the space of things it has to consider. In the short term this is a huge advantage, because the system does not waste compute exploring obviously-bad options. The expert's knowledge is, in effect, free compute. That is why knowledge-based systems usually win early, while compute is expensive.
But the constraints the expert imposes are also a ceiling. The expert can only encode the knowledge the expert has, and the expert's knowledge is incomplete and partly wrong, as all human knowledge is. A general method that learns or searches is not bounded by what the expert knew. Given enough compute, it can discover patterns the expert never articulated, including the famous AlphaGo move that strong human players initially read as a mistake and later recognized as brilliant. As compute gets cheaper, the general method's ability to explore beyond the expert's ceiling grows, and the expert's head start shrinks. At some point the lines cross. The date of the crossing is set by the cost of compute.
This is the part that matters for business. The crossing point is not a function of how good your team is. You can have the best domain team in the world and it will not move the crossing point by much, because the thing on the other side of the crossing is not a better team, it is a cheaper teraflop. Sutton's phrasing is that researchers wanted to build their own knowledge in because that is "the obvious thing to do," and it always helped in the short term and gratified the researcher, but in the long run it plateaued and even inhibited progress, while the breakthrough came from scaling computation through search and learning.
The thing Sutton did not say, and why it matters to you
Here is where I want to be careful, because the bitter lesson is constantly overstated, and the overstatement is one of the lazy conclusions this book exists to kill.
Sutton's argument is about the model, the system that performs the task. It is an argument about where capability comes from. It is not an argument that nothing else matters. Deep Blue won the chess match, but IBM did not become the world's chess company, because being good at chess was not a business. AlexNet changed vision, but the value did not accrue to the network architecture, which was published and copied within months. It accrued to companies that put learned vision into products people paid for, with data those companies controlled, in workflows those companies owned.
The bitter lesson tells you that the model layer commoditizes. It is silent on everything else, and people fill that silence with whatever conclusion flatters their priors. The doomers fill it with "so application companies are defenseless." The romantics fill it with "so our domain knowledge will save us." Both are filling a silence that the essay never spoke into.
What the history actually supports is narrower and more useful: if your advantage is that you encoded knowledge into a model, and that knowledge is the kind a general learning system can acquire from data and compute, then your advantage has an expiration date, and the date is set by the compute curve, not by your effort. That is a precise, testable claim. It is the seed of the Scale Exposure Test, which I will formalize in a later chapter and which asks, of any advantage you claim: would a larger, cheaper, or more tool-capable general model weaken this?
Run that test against the losing side of each historical case and it screams. Deep Blue's opponents relied on encoded grandmaster heuristics: a bigger search weakens that. The Go knowledge-engineers relied on encoded intuition: a learning system with self-play and compute weakens that. The vision feature-designers relied on hand-built descriptors: a network that learns its own features from more data weakens that. In every case the answer was yes, and in every case the advantage fell on schedule.
The historical cases as a strategist's checklist
Let me convert the history into something you can use, because a chapter that only admires the past has failed the test I set in the introduction.
| Domain | The handcrafted advantage | The general method that won | What it ran on | Years to crossing |
|---|---|---|---|---|
| Chess | Encoded grandmaster evaluation heuristics | Deep search over the game tree | Specialized fast hardware | Decades |
| Go | Encoded positional intuition, opening books | Deep nets plus tree search, then self-play | GPUs at scale | A few years after the problem was framed as learnable |
| Speech | Phonetic and linguistic rules | Statistical models, then deep learning | Growing data and compute | A long, grinding decline |
| Vision | Hand-designed image features | Learned convolutional features | GPU training on ImageNet | A single competition, roughly one year to total adoption |
Read the columns. The fourth column, what it ran on, is always some form of more compute made cheaper or more accessible. The fifth column, years to crossing, is shrinking over time, which is the genuinely alarming trend for anyone whose plan depends on a capability gap staying open. The vision case crossed in roughly a year. Current frontier model releases ship every few months. The Verant founder from the introduction had ten months. The trend in the fifth column is the trend that should set your planning horizon.
There is one more column the table does not have, and its absence is the point of the rest of the book: a column for advantages that did not cross. Nobody hand-built a workflow that AlexNet erased, because AlexNet was not a workflow. Nobody had a compliance audit that Deep Blue invalidated, because chess has no regulator. The advantages that survive the historical pattern are the ones that were never at the model layer to begin with. The history is silent on them not because they do not exist but because they were not what the researchers were studying.
What this means for the next thing you build
If you take one operating instinct from this chapter, take this: when you find yourself encoding domain knowledge into a model as your primary source of advantage, set a calendar reminder. You are buying a head start, and head starts are real and worth buying, but you are not buying a moat, and you should not price it as one. The head start will be matched by a general model on a schedule you do not control. The only question is whether you spent the head start building something at a layer the general model cannot reach.
The Verant team spent their ten-month head start the wrong way. They spent it improving the model that was about to be matched. They could have spent it deepening integrations no API can replicate, accumulating a correction feedback loop no base model has access to, and earning a compliance posture that takes a competitor eighteen months to acquire. The model was always going to be matched. The question was what they would own when it was.
The next chapter goes one level deeper into the engine doing the matching: the scaling laws that turn "more compute wins" from a slogan into a forecast you can actually plan against.
Key Takeaways
- The bitter lesson is a historical pattern, not a one-time event: in chess, Go, speech, and vision, encoded human knowledge lost to general methods that use more computation through search and learning.
- The losing side was always the side that knew the most about the domain, which is exactly the position most application companies believe is their moat.
- The crossing point where the general method overtakes the handcrafted one is set by the cost of compute, not by how good your team is.
- The time-to-crossing is shrinking: vision crossed in about a year, and frontier models now ship every few months.
- The advantages that survive the pattern are the ones that were never at the model layer: workflows, integrations, feedback loops, and compliance, none of which the historical researchers were studying.
- When you encode domain knowledge into a model as your primary advantage, you are buying a head start, not a moat. Price it that way and spend it on layers scale cannot reach.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.