Open Models and the Compression of Frontier Advantage
Why open weights matter as a strategic pressure rather than a tribal allegiance, and how to use them without confusing the choice of weights with a strategy.

Research spine
This chapter is grounded in Stanford HAI, 2026 AI Index Report, Stanford HAI, 2025 AI Index Report, and Rich Sutton, The Bitter Lesson.
The durable AI moat is not model cleverness alone; it is the workflow, data, trust, distribution, and evaluation stack that survives scale.
The fastest way to lose an hour in an AI strategy meeting is to let it become a debate about open versus closed. The debate has the structure of a sports rivalry: people pick a side early, the side becomes part of their identity, and after that they are arguing for the jersey rather than the business. I have watched a CTO defend open models with the fervor of a convert and a VP defend frontier APIs with the loyalty of a vendor's golf buddy, and neither one was making a decision, they were performing an allegiance.
I want to drain the tribalism out of this, because underneath the jersey there is a real and consequential strategic question. The question is not "which side is morally correct." The question is "what does the existence of capable open-weight models do to the value of a frontier model lead, and how should that change what I build and buy." Answered that way, open versus closed stops being a manifesto and becomes a variable in the system, which is exactly what the introduction promised it was.
What open models actually compress
The single most important effect of capable open-weight models is that they compress the value of a frontier lead. When the best closed model is the only way to get a given capability, that capability commands a premium and the lead is worth a lot. When an open-weight model lands a few months later that delivers most of that capability for the cost of running it yourself, the premium on the frontier collapses for every use case that did not strictly need the last few points of quality.
Think of it as the bitter lesson applied to the gap between labs rather than between handcrafted and general systems. The frontier lab spends enormous compute to open a capability lead. The open ecosystem, riding the same scaling laws and the same published research, follows behind at a lag. The lag is the entire economic value of the frontier lead. If the lag is long, frontier labs capture a lot of value. If the lag is short, the frontier lead is a wasting asset, because most customers will wait a few months and take the open version at a fraction of the cost.
For you, the application company, this compression is mostly good news, with a sharp caveat. It is good news because it means the model layer, the most scale-exposed layer in your stack, gets cheaper and more substitutable over time. Substitutable inputs are good for whoever sits above them. The caveat is that the same compression hits your competitors, so it is not a source of advantage for you specifically. It lowers the floor for everyone. A lower floor for everyone is not a moat. It is a market condition.
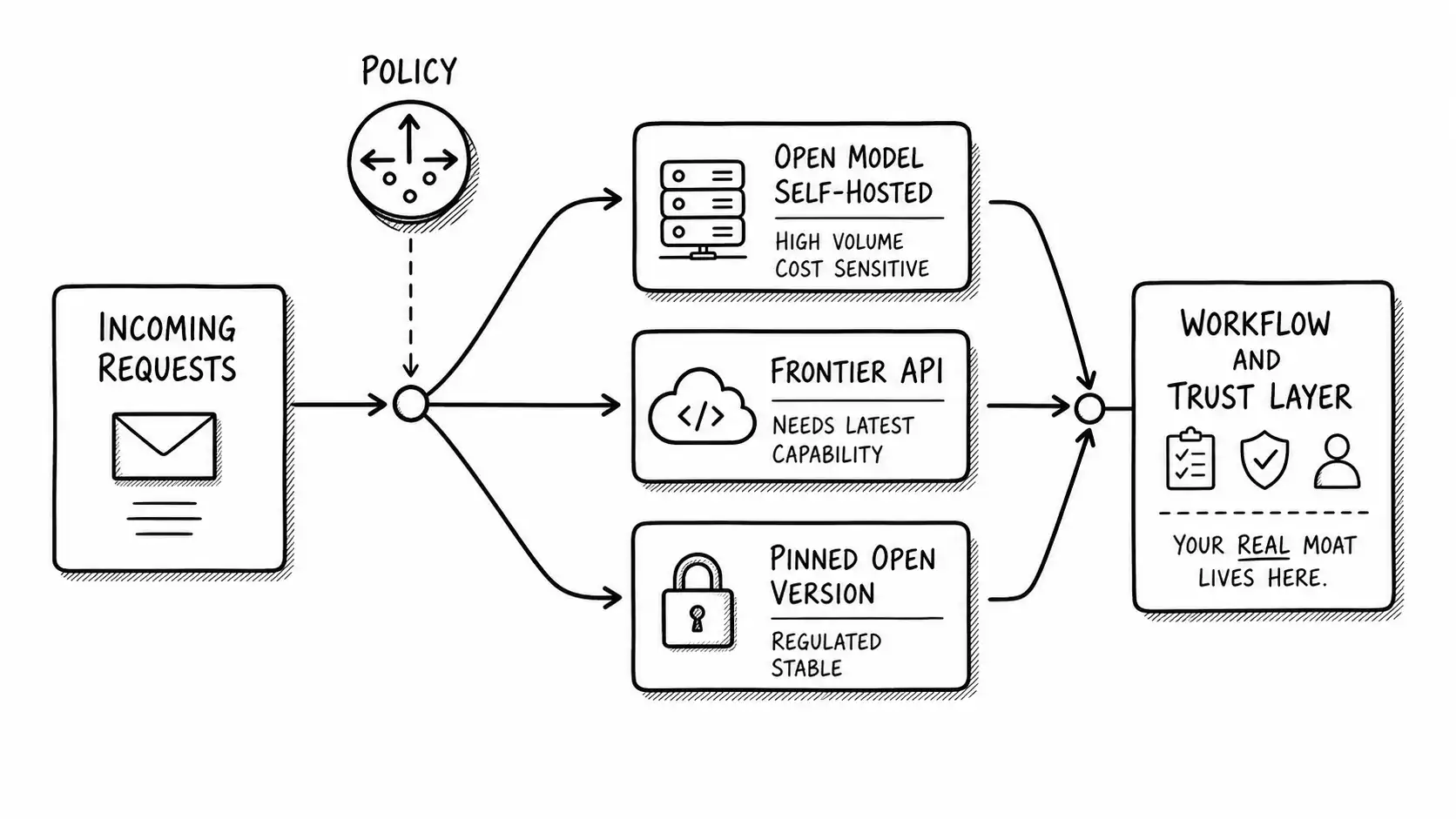
The strategic pressures, named
Open-weight models exert three distinct pressures on an AI application business, and you should track them separately.
Price pressure on inference. Once a good-enough open model exists, the price of frontier inference faces a competitor that is, at the margin, the cost of your own hardware. This caps what frontier labs can charge and what you can charge for the model-layer portion of your value. The Scale Exposure Test's "cheaper" vector is partly powered by open models: they are one of the forces that keep making the obvious approach cheaper.
Capability pressure on differentiation. When the open model is good enough for a use case, "we use the best model" stops being a differentiator for that use case, because anyone can run a good-enough model. Differentiation has to come from somewhere the model is not, which is the entire point of the lower layers of the stack.
Control pressure, which runs the other way. Open weights give you control the frontier API does not: you can run them in your own environment, fine-tune them deeply, fix the version so a vendor's Tuesday update cannot move your behavior under you, and meet data-residency or air-gap requirements that an external API cannot. This pressure is not about price or capability. It is about owning the substrate, and for some businesses it is the deciding factor regardless of benchmark scores.
These three pressures do not point the same direction, which is precisely why the tribal framing is useless. The same technology lowers your pricing power and raises your control. Whether that is good for you depends on your specific stack, not on which jersey you wear.
A scorecard instead of an allegiance
Here is the artifact: an open model versus API strategy scorecard. Score each row for your situation, and let the totals, not your priors, make the call. Higher score favors the column.
| Dimension | Favors open weights | Favors frontier API |
|---|---|---|
| Frontier capability gap on your task | Small or shrinking | Large and persistent |
| Sensitivity to per-request cost | High volume, cost-dominant | Low volume, cost-trivial |
| Data residency / air-gap / sovereignty needs | Strict | Loose |
| Need to pin a fixed model version | Critical | Tolerant of vendor updates |
| In-house ML and infra capability | Strong | Thin |
| Speed to ship and maintain | Slower acceptable | Need fastest path |
| Need for the absolute latest capability | Can lag a few months | Must be at frontier |
| Deep customization / fine-tuning depth | Required | Light adaptation only |
Run it honestly and a striking thing usually happens: the answer is rarely all-open or all-closed. It is a portfolio. You route high-volume, cost-sensitive, low-stakes traffic to open models you run yourself, and you route the requests that genuinely need frontier capability to the API, and you pin versions where regulatory stability demands it. The decision is not a side. It is an allocation.
The lock-in question nobody asks early enough
There is a second-order effect of the open-versus-API choice that teams discover too late: it determines who has use over you.
If you build entirely on one frontier API, that vendor has real use. They can change pricing, change the model behavior with an update, deprecate a version you depended on, or reprioritize their roadmap away from your use case. You have a dependency you do not control, sitting at the most exposed layer of your stack. This is fine if the value you build above the model is large enough that the model is a commodity input you can swap. It is dangerous if your business is thin enough that the vendor could, in principle, ship your product as a feature.
If you build on open weights you run yourself, you trade that dependency for a different one: you now own the operational burden of running, updating, and securing models, and you carry the risk that you fall behind the frontier. You have control, and control has a cost denominated in engineering time and infrastructure.
The mature move is to design for substitutability regardless of which you choose today. Keep the model behind an internal interface so that swapping an API for open weights, or one API for another, is a configuration change rather than a rewrite. The companies that got burned by a vendor's pricing change or behavior change are almost always the ones who wired a specific model deep into their product. The ones who stayed flexible treated every model, open or closed, as a replaceable component behind a stable seam. That seam is itself a small piece of workflow-layer engineering, which is to say the defense against model-layer lock-in is built at a lower, more durable layer.
Where open models do not help you at all
Because this chapter could be misread as pro-open, let me be precise about the limits.
Open models do nothing for the lower layers of your stack. They do not give you a customer's private data, an owned workflow, distribution, a compliance posture, or a feedback loop. They are an input to the most exposed layer, and choosing them well can improve your cost structure and your control, but it cannot create a moat, because the layer they live at is the layer that does not hold a moat for anyone. Run the Scale Exposure Test on "we use open models" and it lands on NO REAL MOAT at Q3, because using open models is not something the general model cannot access. Anyone can use open models. That is the entire point of them.
So the open-versus-closed decision is a cost, control, and risk decision at the model layer. It is genuinely important, the way choosing a cloud provider is important, and like choosing a cloud provider it is not your strategy. Treating it as your strategy is the third lazy conclusion from the introduction, the one that reads one good blog post and stops. You can win on open. You can win on closed. You cannot win on the choice itself, because the choice is available to everyone, which is the bitter lesson's signature: anything available to everyone via scale is not a source of advantage.
How the choice interacts with capability shocks
One forward-looking note, because it sets up a later chapter. The open-versus-API choice changes your exposure to capability shocks, the sudden jumps when a much better model ships.
If you are on a frontier API, a capability shock arrives as a free upgrade you did not have to do anything to receive, and also as a competitive shock, because your competitors got the same upgrade. If you are on pinned open weights, a capability shock arrives as a decision: do you undertake the work to adopt the new capability, and when. You are insulated from the surprise but you carry the catch-up cost.
Neither is strictly better. The portfolio approach hedges: frontier API for the parts of your product where you want to ride the rising tide automatically, pinned open weights for the parts where stability and control matter more than being at the frontier. The capability-shock chapter builds a full response plan, and your model-sourcing portfolio is one of its inputs.
What to do differently tomorrow
Stop having the open-versus-closed debate as a debate. Replace it with the scorecard and run your actual traffic through it, segment by segment. You will almost certainly land on a portfolio, and the portfolio will almost certainly route by use case rather than by allegiance.
Then put the model, whichever models you chose, behind an internal seam so that the choice is reversible. The single most valuable artifact to come out of this chapter is not the scorecard, it is the interface that makes the model a swappable component. That seam is how you keep the bitter lesson working for you instead of against you: when a better or cheaper model ships, open or closed, you adopt it as a configuration change and capture the improvement, while your real advantage sits untouched at the layers below.
The next chapter goes to the layer where the most expensive misjudgments happen, data, and draws the precise line between data that survives scale and data that scale quietly absorbs.
Key Takeaways
- Open versus closed is a variable in the system, not a strategy. Treating it as your whole strategy is a lazy conclusion that confuses the choice of weights with a moat.
- The main effect of capable open-weight models is to compress the value of a frontier lead by shortening the lag before most of that capability is available cheaply. This is a market condition, not an advantage for any single player.
- Open weights exert three separate pressures: downward on inference price, downward on capability differentiation, and upward on your control of the substrate. They do not point the same way, which is why the tribal framing is useless.
- Use a scorecard, not an allegiance. The honest answer is usually a portfolio that routes traffic by use case: open for high-volume cost-sensitive and regulated-stable work, frontier API for work that needs the latest capability.
- The choice determines who has use over you. Design for substitutability by keeping every model behind a stable internal seam, so swapping is configuration, not a rewrite.
- Open models cannot create a moat, because they live at the layer that holds no moat for anyone. Your defensibility still has to come from the lower layers of the stack.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.