The Moat Migration Stack
A six-layer map of where defensibility lives, why scale pushes it down the stack, and how to read your own business through it.

Research spine
This chapter is grounded in Stanford HAI, 2026 AI Index Report, Stanford HAI, 2025 AI Index Report, and Rich Sutton, The Bitter Lesson.
I want to start this chapter with a whiteboard, because the framework that organizes the rest of the book was born on one. I was in a budget review with an AI company's leadership team, the kind of meeting where someone has built a slide that proves the company is defensible and someone else has built a slide that proves it is doomed, and both slides are about the model. I drew a vertical stack of six boxes on the whiteboard and asked the team to tell me, for each box, whether a bigger and cheaper general model next year would weaken what they had there. By the time we got to the bottom of the stack, the argument had dissolved, because we could finally see that the company was strong at three layers and weak at one, and the one it was weak at was the only one anyone had brought a slide about.
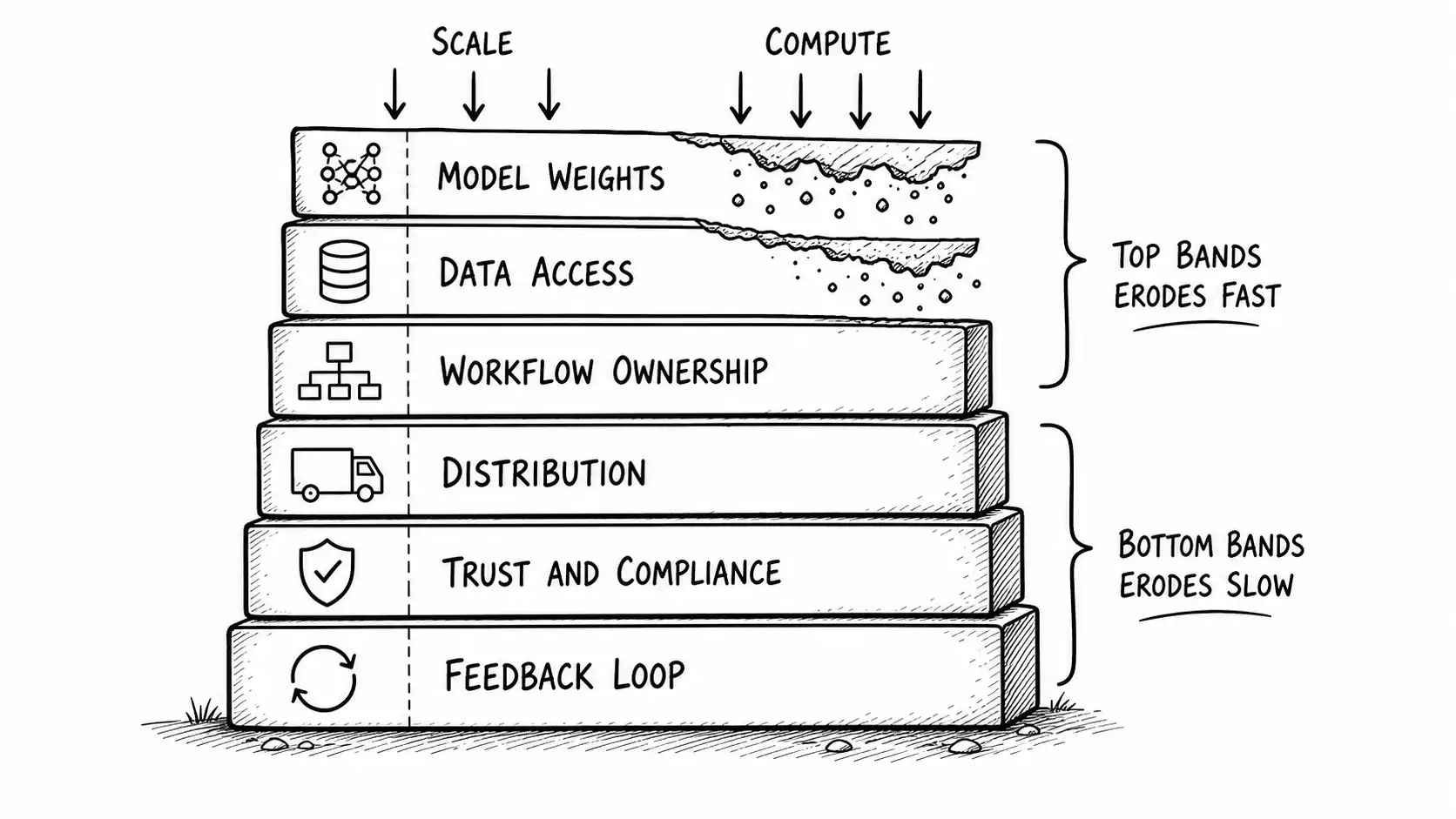
That stack is the central instrument of this book. I call it the Moat Migration Stack, and the word that matters is "migration." The point is not that defensibility exists or does not exist. The point is that it moves. Scale eats it at the top of the stack and it reforms further down, at the layers compute does not automatically touch.
The six layers
From top to bottom, most exposed to scale to least exposed:
- Model weights. The parameters themselves. Whether you trained, fine-tuned, or licensed them.
- Data access. The data you can feed the model, including proprietary data and live context the general model does not have.
- Workflow ownership. The end-to-end process the user actually completes inside your product, including the steps that happen around the model call.
- Distribution. How you reach and acquire users, including channel relationships, embeds, and partnerships.
- Trust and compliance. The right to operate in a context with auditors, regulators, security reviews, and buyers who answer to all three.
- Feedback loop. The closed loop in which real usage produces signal that improves the product in ways a competitor cannot copy.
The ordering is the argument. The top of the stack is where the bitter lesson operates most directly, and the bottom is where it operates least. As you go down, defensibility gets harder for scale to erode, because each lower layer depends less on raw capability and more on things compute does not produce: relationships, habits, audits, accumulated private signal.
Layer one: model weights, the melting top
This is where most founders think their moat is, and it is the layer the previous two chapters spent dismantling. If your differentiation is the weights, your differentiation is exposed directly to the compute curve. A fine-tune is a temporary capability shaped onto a base that is about to be replaced by a better base. Training your own foundation model is a moat only if you can keep spending at the frontier indefinitely, which almost no company can.
I am not saying weights never matter. They matter enormously for the labs whose entire business is the frontier, and they matter tactically for a company that genuinely cannot get acceptable quality any other way. But for the typical application company, treating weights as the moat is the strategic equivalent of building your house on the part of the beach the tide reaches. The Verant team from the introduction lived almost entirely at layer one. That is why a Tuesday version bump nearly killed them.
The Scale Exposure Test, which I will formalize in its own chapter, lives most painfully here. Would a larger, cheaper, more tool-capable general model weaken your weights advantage? At layer one the answer is almost always yes, on a schedule of months.
Layer two: data access, the first real argument
Data is the layer where the conversation gets interesting, and it is also where the most expensive mistakes happen, so the book gives it a full chapter later. For now, the stack-level point is that data is not one thing. There is data the model already effectively has, because it was on the public internet and the scaling laws hoovered it up. And there is data the model structurally cannot have: your customer's private records, the live state of their systems right now, the corrections their staff made yesterday.
The first kind is not a moat. The second kind can be. The line between them is the line between data that scale absorbs and data that scale cannot reach. A general model trained on the open web will, over time, know everything a textbook knows about radiology. It will never know what is in a specific hospital's PACS this morning unless someone gives it access. Layer two defensibility lives entirely in the second category, and most companies that claim a "data moat" are actually sitting on the first category and have not noticed.
Layer three: workflow ownership, where context actually lives
This is the layer where most durable AI businesses actually live, and it is consistently undervalued because it is unglamorous. The model call is a few seconds in the middle of a process that takes a user thirty minutes. Around that call sits everything that makes the output usable: the steps that gather the right inputs, the integrations that pull current state from other systems, the validation that catches the model's mistakes before they reach a customer, the handoffs to humans, the audit trail, the place the result actually goes.
A general model gets better at the few seconds in the middle. It does not, by default, get any better at the thirty minutes around it, because the thirty minutes are specific to your customer's reality and were never on the training distribution. Owning the workflow means owning the part of the value the model cannot see. This is where "scale eats cleverness at the model layer, then forces cleverness to migrate elsewhere" becomes concrete: the cleverness migrates from the prompt to the process. I give workflow its own chapter because it is where I would tell most founders to spend most of their effort.
Layer four: distribution, the moat that predates AI
Distribution is the least AI-specific layer in the stack, which is exactly why it is durable. How you reach users, whether through an existing product they already open daily, a channel partner who resells you, an integration that puts you inside someone else's workflow, or a brand that gets you on the shortlist, none of that is affected by the model getting better. A better model does not give your competitor your customer relationships.
This is also why incumbents with distribution are so dangerous to AI startups, and why so many AI features ship fastest from companies that already own the surface the user is looking at. The startup has the better model for six months. The incumbent has the distribution forever. Bet on the wrong one and the better model becomes a feature in the incumbent's product. The stack tells you that distribution sits below model weights for a reason: it does not erode when capability rises.
Layer five: trust and compliance, the slowest to erode
In regulated and high-stakes contexts, the right to operate is its own moat, and it is almost perfectly insulated from the compute curve. A model getting better does not give a vendor a completed SOC 2, a HIPAA posture a hospital's security team has audited, a data-processing agreement the customer's legal team has signed, or the track record that gets a vendor past procurement. These take time and trust to accumulate, and trust does not scale with FLOPs.
I have watched a technically inferior product win an enterprise deal against a technically superior one because the inferior product had been through the buyer's security review and the superior one had not, and the buyer could not afford the six-month delay of a fresh review. That is layer five doing its job. It is unglamorous, it is mostly paperwork and relationships, and it is one of the hardest layers in the stack for a better model to dissolve. A later chapter treats trust, compliance, and distribution together as the model-era moats they have quietly become.
Layer six: the feedback loop, the only compounding layer
At the bottom sits the layer that not only resists scale but compounds against it. A feedback loop is the closed cycle in which real usage produces private signal that improves your product, which improves the experience, which produces more usage and more signal. The signal is private because it comes from inside your workflow, on your customers' real tasks, with their real corrections. A general model does not have it and cannot buy it.
The reason this is the bottom of the stack is that it is the only layer where the gap widens over time on its own. Every other layer, you defend. This layer, if you build it right, defends itself and grows. The durable AI companies I have seen all have some version of this: they watch users correct outputs, they capture the corrections, and they feed them back into evals and product in a way no competitor can replicate because no competitor has the usage. The feedback loop is where the durable-advantage flywheel lives, and it is worth designing the whole product around.
The worksheet: scoring your own stack
Here is the artifact. Run your business through it honestly. For each layer, rate your strength from 0 to 3, and separately rate that layer's exposure to scale from 0 to 3, where higher exposure means a better general model weakens it more.
| Layer | Your strength (0-3) | Scale exposure (0-3) | Verdict |
|---|---|---|---|
| Model weights | High exposure: do not count on it | ||
| Data access | Depends: is the data reachable by scale? | ||
| Workflow ownership | Low exposure: invest here | ||
| Distribution | Low exposure: invest or partner | ||
| Trust and compliance | Lowest exposure: durable if real | ||
| Feedback loop | Compounds: design around it |
The diagnostic is simple and brutal. Add up your strength only on the layers with low scale exposure: workflow, distribution, trust, feedback loop. If most of your strength is at the top of the stack, where exposure is high, you do not have a defensible business, you have a head start, and you should be using it to build down the stack. If your strength is concentrated in the lower four, scale can keep eating the model layer all it wants and your business survives, because your business was never really at the model layer.
This is exactly what happened in the whiteboard meeting that started the chapter. The team scored high on workflow and trust and low on weights. They had been losing sleep over the one layer that did not matter and ignoring the three that did. The migration had already happened in their business. They just had not drawn it yet.
Why "migration" and not "destruction"
I chose the word migration deliberately against the doomer framing. The doomers say scale destroys moats. The stack says scale relocates them. Defensibility is not conserved exactly, but it is not annihilated either, it moves down the stack toward the layers compute does not reach. A company that understands this does not panic when the model layer commoditizes, because it never banked the model layer as a moat. It banked the lower layers and treated the model as a rented, rising tide.
The strategic instruction is therefore not "find a layer scale cannot touch and hide there." It is "build a position that spans the lower layers so that when the top erodes, and it will, the structure stands." The next chapter takes the single test that runs underneath all of this, the Scale Exposure Test, and turns it into a decision tree you can apply to any advantage in fifteen minutes.
Key Takeaways
- Defensibility does not vanish under scale, it migrates down a six-layer stack: model weights, data access, workflow ownership, distribution, trust and compliance, and feedback loop.
- The top layers erode fast under the compute curve; the bottom layers erode slowly or not at all, because they depend on relationships, habits, audits, and private signal rather than raw capability.
- Most founders defend the wrong layer. Model weights are the most exposed, yet they get the most strategic attention.
- Workflow ownership is where most durable AI businesses actually live, because the model call is a few seconds inside a process that takes the user much longer.
- The feedback loop is the only layer that compounds against scale on its own, because private usage signal widens the gap over time.
- Score your business by strength and scale-exposure per layer. If your strength sits at the high-exposure top, you have a head start, not a moat, and you should spend it building down the stack.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.