Workflow Moats: Where Context Actually Lives
Why the value of an AI product lives in the thirty minutes around the model call, not the few seconds of the call itself.

Research spine
This chapter is grounded in Stanford HAI, 2026 AI Index Report, Stanford HAI, 2025 AI Index Report, and Rich Sutton, The Bitter Lesson.
The durable AI moat is not model cleverness alone; it is the workflow, data, trust, distribution, and evaluation stack that survives scale.
Watch a real user do real work with an AI product and time it. The part where the model runs is a few seconds. The part where the user gathers the inputs, decides which of three conflicting internal documents is authoritative, pastes the result into the system that actually matters, checks it against a constraint the model never knew about, and routes it to the colleague who has to approve it, that part is thirty minutes. The model call is the easy, visible, commoditizing few seconds. The thirty minutes is the workflow, and the workflow is where the value lives, because the thirty minutes is full of context the model does not have and was never going to get from a bigger training run.
This is the layer I would tell most founders to obsess over, and it is consistently the least glamorous part of the pitch, which is exactly why it stays defensible. Nobody puts "we own the boring thirty minutes" on the headline slide. They put the model on the headline slide. The model is the part scale eats. The thirty minutes is the part scale cannot reach, because the thirty minutes is not a capability problem, it is a context, integration, and trust problem, and those do not improve when the model's next-token loss goes down.
What "context the model does not have" actually means
Let me be concrete about what is missing during those thirty minutes, because "context" is a word that gets waved around until it means nothing.
The model does not have the current state of the customer's systems. It does not know what is in their database right now, what the open tickets are, what the inventory level is, which version of the policy is live this quarter. That state lives in systems the model has no connection to, and it changes constantly, so even if you trained on a snapshot it would be stale by the time anyone used it.
The model does not have the customer's private rules, the ones that are not written down anywhere a crawl could find. Every real organization runs on undocumented constraints: this customer always gets manual review, that product line has a special approval path, this number is never allowed to exceed that one for reasons buried in a regulation three people understand. These rules are not on the internet. They live in the workflow, enforced by the steps around the model.
The model does not have the permission structure. It does not know that this user can see these records but not those, that this action requires a second approver, that this data cannot leave this jurisdiction. The permission model is not a capability the model can learn, it is a constraint the workflow has to enforce regardless of how smart the model gets.
And the model does not have the destination. The output has to go somewhere: into a system of record, a downstream process, a document a human signs. Getting it there correctly, in the right format, with the right audit trail, is workflow, not intelligence.
A bigger model improves the few seconds in the middle. It does nothing for any of this, because none of it is a next-token problem. This is the precise mechanism behind the motif: scale eats cleverness at the model layer, and the cleverness migrates to the workflow, because the workflow is made of exactly the things scale does not touch.
The integration depth that takes eighteen months
The most underrated form of workflow moat is integration depth, and it is underrated because it looks like grunt work and is.
To own a workflow, you usually have to read from and write to the systems the customer already runs: their ERP, their CRM, their ticketing system, their data warehouse, their identity provider. Each integration is a slog. The APIs are inconsistent, the auth is a nightmare, the edge cases are endless, and the customer's instance is configured in some unique way that breaks your assumptions. Building a deep, reliable, bidirectional integration into a customer's stack can take many months, and certifying it for an enterprise can take longer.
Here is why that slog is a moat. A better model does not give your competitor those integrations. The integrations are not a capability that scales with compute, they are a body of unglamorous engineering and a set of certified connections that exist only because someone did the months of work. When a customer's workflow runs through your integrations, swapping you out means rebuilding all of them, which is expensive and risky enough that the customer mostly will not. Run the Scale Exposure Test: does a larger, cheaper, more tool-capable model weaken your integration depth? No. The model getting smarter does not hand a competitor credentials to the customer's ERP or the eighteen months of work to certify a connection. Integration depth lands on LOW EXPOSURE, which is exactly where you want your investment.
There is a real threat to watch here, and it is the "more tool-capable" vector. As models get better at using tools, some of the orchestration logic inside a workflow, the part that decides which system to call in what order, gets absorbed by the model. That is real and you should expect it. But absorbing the orchestration logic is not the same as having the integrations. The model can learn to decide it needs the customer's inventory; it still cannot reach the customer's inventory system without the connection you built and the credentials the customer granted you. The orchestration commoditizes; the wired, certified, permissioned connection does not.
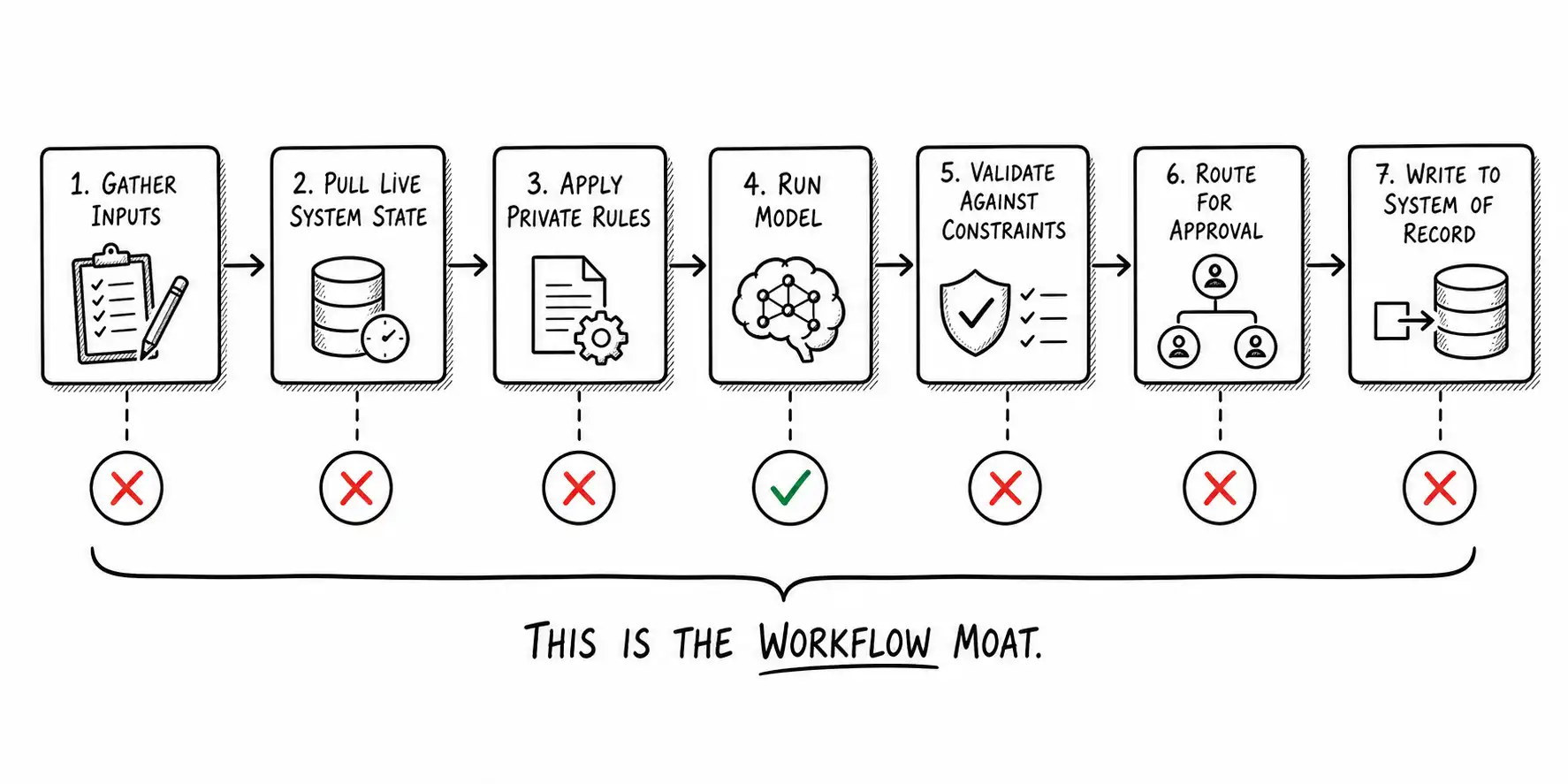
The context map: drawing what the model cannot see
Here is an artifact I have teams build in a single workshop. Draw the workflow as a horizontal flow, left to right, every step a real user takes. Then, for each step, mark whether the information that step needs is available to the model by default or not. The steps marked "not available to the model" are your workflow moat, drawn explicitly.
When teams do this honestly, the picture is almost always the same as the sketch: one step is "available to the model," the model call, and every other step is "not available to the model." That picture is the most reassuring thing a panicking founder can see after a frontier update, because it shows visually that the update improved one box out of seven, and the other six are theirs. The Verant team, late, drew this map and realized that report extraction, the box the update improved, was a single step in a workflow that also included pulling the patient's prior studies, applying the hospital's reporting conventions, flagging findings against the radiologist's standing rules, routing to the right physician, and writing into the reporting system. The update ate one box. They owned six.
Why owning the workflow creates the feedback loop
The workflow layer is not just defensible on its own, it is the layer that generates the durable data moat from the previous chapter, which is why I keep insisting they are the same structure seen twice.
When you own the workflow, you own the moment where the user validates or corrects the model's output, because that moment happens inside your product. Every correction is a judgment on a real task, the scarce supervision signal that scale cannot manufacture. If you have engineered the workflow to capture those corrections, you have a feedback loop, and the feedback loop is the bottom, compounding layer of the stack. A competitor with a better model but no workflow has no corrections, because they have no moment where a real user validates a real output on a real task. They have the capability. You have the verdicts.
This is the flywheel: own the workflow, capture the corrections, improve the evals and the product, earn more usage and trust, capture more corrections. The model is a rising tide that lifts you and your competitor equally. The flywheel is the part that lifts only you, and it only exists because you own the workflow. This is the operational meaning of "build where scale needs context to become useful": the context is in the workflow, the workflow produces the corrections, and the corrections are the only thing compounding in your favor.
The honest threat: workflows can be disintermediated
I will not pretend the workflow layer is invulnerable, because the lazy-optimistic version of this chapter would be as wrong as the lazy-pessimistic version of the model chapters.
The real threat to a workflow moat is disintermediation: someone who already owns the surface the user looks at, or already owns the systems the workflow connects, decides to own the workflow themselves. The incumbent ERP vendor builds the AI workflow into the ERP. The platform the user already opens every day adds the feature natively. They have distribution and they have the integrations because they are the system. This is the distribution layer of the stack reaching up to threaten the workflow layer, and it is a genuine risk that a better model has nothing to do with.
The defense is not to out-model them, because you cannot, and it is not to out-integrate the company that owns the system, because you cannot do that either. The defense is to own the workflow across systems they do not individually own. The ERP vendor owns the ERP; they do not own the cross-system process that spans the ERP, the CRM, the ticketing system, and the human approvals. The user who lives in one platform does not get a workflow that orchestrates five. Workflow moats are strongest exactly where they span boundaries no single incumbent controls, and weakest where they sit inside one incumbent's walls waiting to be absorbed. Choose your workflow accordingly: live in the seams between systems, not inside one of them.
A worked build decision
Let me make this operational with a decision a team actually faces. Suppose you can spend the next quarter either improving your model's accuracy on the core task by a few points or building a deep two-way integration into the customer's primary system of record. The model improvement is visible, demoable, and flattering. The integration is invisible, slow, and a slog.
Run both through the Scale Exposure Test. The accuracy improvement: Q1, is it that the model is more capable, yes, HIGH EXPOSURE, a frontier update will likely match it within months and you will have spent a quarter on a depreciating asset. The integration: Q3, does it rely on something the model cannot access, yes, the customer's live system and the certified connection, Q4, does it stay inaccessible without you, yes, LOW EXPOSURE, durable and it deepens the workflow that produces your feedback loop.
The test says spend the quarter on the integration, even though the model improvement demos better and feels more like real AI work. This is the recurring discipline of the whole book: do the unglamorous durable work over the glamorous exposed work, because the exposed work is exactly what scale is about to do for free. The integration is the harder sell internally and the better investment externally. Most teams pick the demo. The durable ones pick the slog.
What to do differently tomorrow
Run the context map workshop this week. Draw your real workflow, mark every step as available or not available to the model, and look at the ratio. If most steps are not available to the model, you have a workflow moat whether or not you have been treating it as one, and your job is to deepen it and to make sure you are capturing the corrections that turn it into a feedback loop. If most steps are available to the model, you are closer to a wrapper than you think, and the more tool-capable vector is coming for you, so your urgent job is to push into the systems and constraints the model cannot reach.
Either way, the instruction is the same: invest down the stack, into the boring thirty minutes, and treat the few seconds of model call as a commodity input you route to the best available model. The next chapter takes the two lowest, slowest-eroding layers, distribution, trust, and compliance, and shows why they have quietly become the strongest moats of the model era.
Key Takeaways
- The value of an AI product lives in the thirty minutes of workflow around the model call, not the few seconds of the call. The workflow is full of context the model does not have and cannot get from scale.
- The missing context is live system state, undocumented private rules, the permission structure, and the destination. None of these are next-token problems, so a bigger model does not improve them.
- Integration depth is an underrated moat precisely because it is unglamorous engineering that a better model does not hand to a competitor. It lands on low exposure in the Scale Exposure Test.
- Map your workflow step by step and mark each as available or not available to the model. Almost always one step is available and the rest are yours. That picture is the antidote to post-update panic.
- Owning the workflow is what generates the feedback loop, because the user's correction happens inside your product. The model is a rising tide for everyone; the flywheel lifts only you.
- The real threat is disintermediation by an incumbent who owns the surface or the systems. Defend by owning workflows that span boundaries no single incumbent controls, and choose the boring durable integration over the flattering model improvement.
Internal map
For the larger argument, keep this chapter connected to The Bitter Lesson, Revisited, the judgment economy, the case for smaller models, and A Field Guide to Evals.