A Memory Is a Claim with a Source: A Working Taxonomy
> **Working claim:** "Memory" is not one thing, and the single most common architectural mistake is building one undifferentiated store and pouring everything into it.

Key Takeaways
- A Memory Is a Claim with a Source: A Working Taxonomy is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: "Memory" is not one thing, and the single most common architectural mistake is building one undifferentiated store and pouring everything into it. An agent needs at least nine distinct kinds of memory, each with a different source, write rule, read rule, decay behavior, and risk profile. Get the taxonomy right and the rest of the system follows. Get it wrong and you spend the project fighting symptoms.
The single-store mistake
Open most "agent with memory" codebases and you find one table, or one vector index, with a content column and an embedding column. Everything goes in: conversation snippets, extracted facts, summaries, the agent's notes to itself, task state, sometimes tool outputs. Recall is a similarity search over the whole thing. It works in the demo. It fails in production, and it fails in a way that is hard to diagnose, because the symptom, "the agent recalled something weird", could come from any of a dozen causes that the single store has flattened into one undifferentiated blob.
The reason a single store fails is that the governance rules for different kinds of memory are not just different: they are contradictory. A conversation snippet should be high-fidelity and short-lived. An extracted preference should be low-fidelity (just the conclusion) and long-lived, but only after confirmation. A task should expire the moment it is done. A learned skill should never expire but must be versioned. An audit record must be immutable and must survive even after the user deletes everything else. You cannot apply one write rule, one decay policy, and one access control to objects whose entire reason for existing pulls in opposite directions. The single store is not a simplification; it is a refusal to make decisions, and the decisions come due later as incidents.
So the first real architectural act is to name the kinds. The taxonomy below is the one I use. It is not the only valid carving, the research literature uses overlapping terms, but it is the one that maps cleanly onto distinct write gates, read policies, and lifecycles (see MemGPT for the foundational treatment of managing differentiated memory tiers in agents), which is the only test that matters for an engineer.
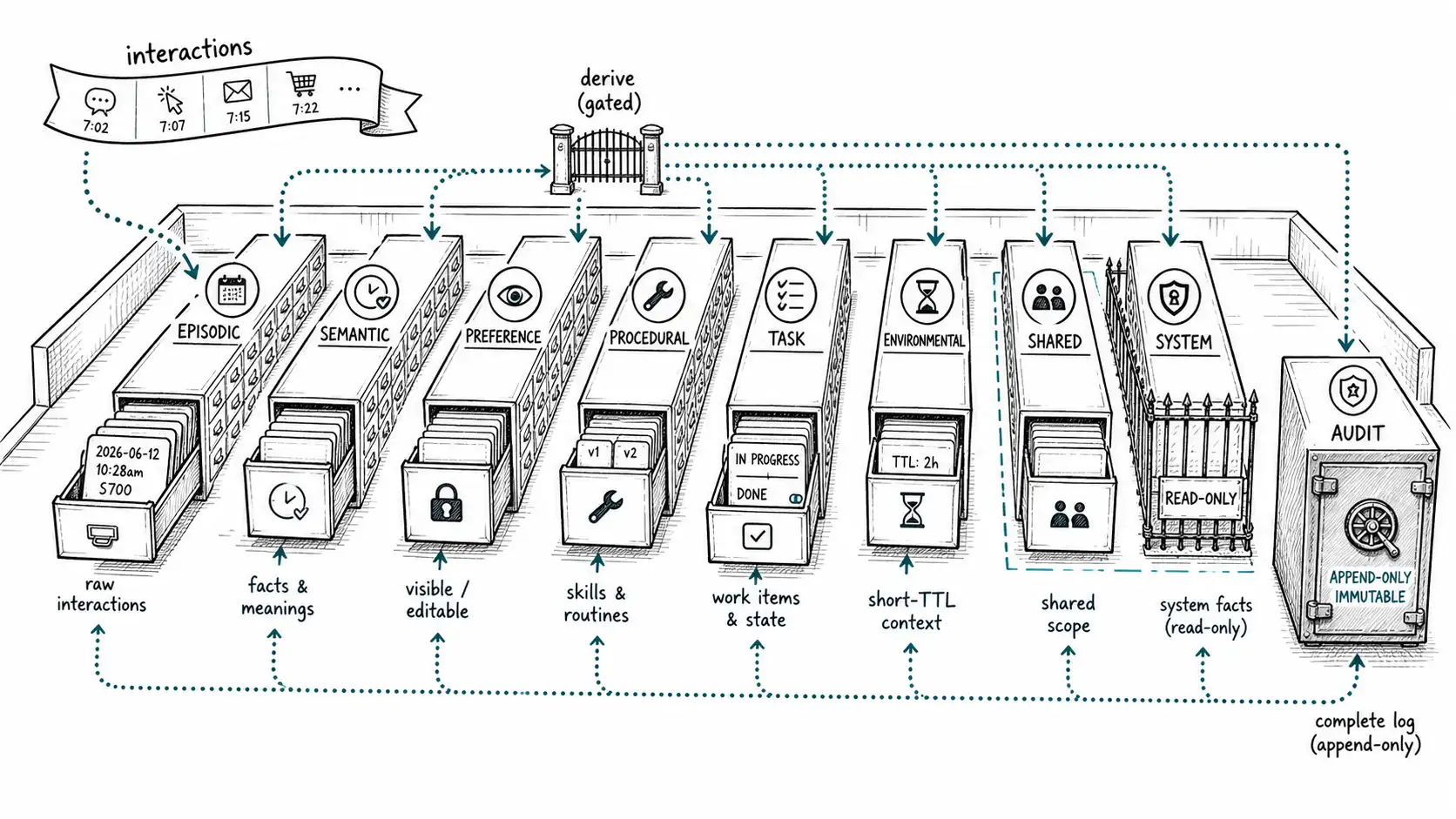
The nine memory types
1. Episodic memory: what happened
Episodic memory is the agent's log of events: interactions, actions taken, tool calls made, results observed."On 2026-03-04 the user asked to reschedule the planning call; I moved it to Thursday; they confirmed." It is high-fidelity, append-only, and it is the evidence layer, every other durable memory should point back to an episode as its source. This is the store that lets a memory be a claim with a source, because the source is an episodic record.
Generative Agents called this the memory stream: a time-stamped sequence of natural-language observations from which everything else is derived. Reflexion used an episodic buffer of trial outcomes as the substrate for self-improvement. The key property is that episodic memory is raw: it records what happened, not what it means. Interpretation is a separate, later, gated step. Conflating the two, writing interpretations into the episodic log, or treating the log as conclusions, is a frequent source of false memory.
2. Semantic memory: what is true
Semantic memory holds durable facts distilled from episodes: "User's timezone is US/Pacific." "The production database is Postgres 15." "The customer's contract renews in November." A semantic fact is the conclusion, not the conversation; it is compact, recallable, and it is what the agent acts on. Crucially, a semantic fact is derived and must carry provenance back to the episode(s) that justified it. A semantic memory with no episodic source is exactly the 7 a. m. failure: a conclusion with no evidence.
Semantic facts can go stale (the timezone changes) and can be contradicted (a later episode says US/Eastern). So semantic memory needs a re-confirmation timestamp, an expiry or decay policy, and a supersession mechanism, none of which episodic memory needs, because episodes are immutable records of the past and the past does not change.
3. Preference memory: what the user wants by default
Preference memory is a special, dangerous subspecies of semantic memory: durable choices and defaults."Prefers concise answers." "Defaults flights to aisle seats." "Wants code comments in the style guide format." Preferences are dangerous because they are acted on repeatedly and silently, the agent applies them without re-asking, which means a wrong preference (the 7 a. m. case) causes recurring harm, and a creepy preference erodes trust every time it is applied. Preferences get the strictest write rule of the user-facing types: prefer confirmation over inference, and always make them visible and editable.
4. Procedural memory: how to do things
Procedural memory holds skills, routines, and workflows: not facts about the world but reusable methods for acting in it."To run this repo's tests: activate the venv, set TEST_DB_URL, run pytest with the integration marker." "To research a company: check the filings, then the news, then the org chart." This is the store that lets an agent get genuinely better at tasks over time, and it is the heart of the Voyager architecture, where the agent built a growing library of executable skills and composed them into more complex behaviors.
Procedural memory is unlike the others in two ways. First, it is executable or near-executable, code, structured plans, or tool sequences, so it can be tested, which the other types cannot. Second, a bad procedural memory has a uniquely large blast radius: it produces wrong behavior every time it is invoked, and worse, the agent may build new skills on top of it. Procedural memory therefore needs versioning, tests, and a retirement path. Chapter 7 is devoted to it.
5. Task memory: what is open
Task memory tracks objectives and their state: open goals, completed subtasks, blocked dependencies, decisions made and their rationale, deadlines."Migrating the billing service to the new schema; data backfill done; cutover blocked on the staging environment; decided to keep the old endpoint for one release." Task memory has a lifecycle, created, in-progress, blocked, done, abandoned, and the dominant failure is forgetting to expire it: a completed task that lingers and gets recalled as if still open, or an abandoned one that the agent keeps trying to resume. Long-horizon tasks (Chapter 8) are where this store earns its keep, because they outlive any single session.
6. Environmental memory: what the world looks like through tools
Environmental memory is the agent's cached model of external state known through tools: the current contents of a directory, the open tickets in a queue, the rows in a table, the state of a deployment. It is distinct from semantic memory because it is about the world, not the user, and because it goes stale fast and silently, the file changed, the ticket closed, the deploy finished, without any conversation to signal the change. The cardinal rule for environmental memory is trust but verify with a TTL: cache it for performance, but treat it as a hint, not ground truth, and re-fetch before acting on anything consequential. An agent that acts on a stale environmental memory ("the file still has that bug") is acting on a fact that was true and quietly stopped being true.
7. Shared / social / team memory: what the workspace knows
The moment more than one user or agent shares a context, you need shared memory: facts about a workspace rather than an individual."This team deploys on Tuesdays." "The on-call rotation is in the runbook." "Customer ACME's account owner is in the West region." Shared memory introduces scoping (who can read it), write authority (who can establish a team fact), and conflict (two members assert different things), concurrency and trust problems the single-user types do not have. It is also a poisoning surface: a malicious member can write a false team fact that the agent then applies for everyone. Chapter 9 covers shared memory in multi-agent systems in depth.
8. System memory: the constraints the agent operates under
System memory holds the agent's operating constraints: available tools, policies, rate limits, capability scopes, the current model version, feature flags. It differs from the others because its source is the operator, not the user or the world, and because it should generally not be model-writable at all, the agent reads system memory but does not author it. Conflating system memory with user memory is a security problem: if the agent can "remember" a relaxation of its own constraints (a user persuades it that "the policy was changed"), you have a privilege-escalation path. System constraints live in configuration the model cannot rewrite, not in the same store as user preferences.
9. Audit memory: the record for accountability, not the model
Audit memory is the odd one out: it exists not to be recalled into prompts but to answer questions after the fact. Every durable write, every recall, every correction, every deletion is logged immutably. When a memory produces a wrong answer, audit memory is how you trace what was written, when, from what evidence, who saw it, and what happened next. It is append-only, immutable, retained on its own schedule, and, critically, it must survive the deletion of the memory it describes, because "we deleted this user's data on this date" is itself a record you must keep. Audit memory is invisible to the agent and indispensable to the operator.
The taxonomy as a table
Here is the whole taxonomy as a single decision table, the artifact to pin above your desk, because every column is a question the design must answer for each type.
| Type | Source | Write rule | Read rule | Decay / expiry | Primary risk |
|---|---|---|---|---|---|
| Episodic | Direct observation of turns/actions | Append-only, no interpretation | By time, task, or as evidence for derivation | Age out raw; keep summaries | Volume; PII accumulation |
| Semantic | Derived from episodes (gated) | Confirmed/high-evidence only; provenance required | By relevance + recency + confidence | Re-confirm; supersede on conflict | False / stale facts |
| Preference | Derived; ideally confirmed | Confirmation preferred over inference; visible + editable | Applied as defaults, yields to live intent | Re-confirm periodically | Creepy / wrong; recurring harm |
| Procedural | Success of an action sequence | Tested before persist; versioned | By task match; prefer latest stable version | No auto-expiry; retire on failure | Drift; large blast radius |
| Task | User goals + agent decomposition | On task creation/update | By active task scope | Expire on done/abandoned | Stale open tasks; zombie goals |
| Environmental | Tool results about the world | Cache with TTL; mark as hint | Re-verify before consequential action | Short TTL; re-fetch | Acting on stale world state |
| Shared/team | Workspace members + agents | Authority-scoped; conflict-aware | Scoped to workspace membership | Per-policy | Poisoning; cross-user leakage |
| System | Operator configuration | Not model-writable | Always available as constraints | On config change | Privilege escalation if writable |
| Audit | The memory system itself | Append-only, immutable | Operators only, never the model | Own retention schedule | Must outlive deletions |
The point of the table is not to memorize it but to internalize that a write to one store is not a write to another. The 7 a. m. failure was, in taxonomy terms, an episodic observation (the user said a sentence) being written directly as a preference (the agent's default), skipping the confirmation rule that the preference column demands. With the taxonomy in place, the bug is not "memory is hard"; it is a specific, nameable rule violation: a preference write that did not satisfy the preference write rule.
Schemas for the user-facing stores
The taxonomy becomes real when it becomes schema. Here are JSON shapes for the four user-facing types most likely to bite you. They share a provenance and ownership spine, because a memory is a claim with a source, and diverge where their lifecycles diverge.
// EPISODIC - append-only, the evidence layer
{
"episode_id": "ep_01HX...",
"actor": "user:8831", // who/what produced the event
"kind": "utterance | action | tool_result | observation",
"content": "Sure, because I love 7 a.m. meetings",
"occurred_at": "2026-03-04T14:22:10Z",
"session_id": "sess_77a2",
"tool_call_id": null, // set when kind == tool_result
"owner_scope": "user:8831" // never null; drives access + deletion
}// SEMANTIC - derived fact, must point back to episodes
{
"memory_id": "mem_01HX...",
"subject": "user:8831",
"claim": "User's timezone is US/Pacific",
"category": "attribute",
"source_episode_ids": ["ep_01HX...", "ep_01HY..."], // provenance, plural
"evidence_spans": ["I'm on the west coast"],
"confidence": 0.91, // calibrated, not a raw logit (Ch. 13)
"created_at": "2026-03-04T14:25:00Z",
"last_confirmed_at": "2026-03-04T14:25:00Z",
"expires_at": null, // attributes rarely expire; re-confirm instead
"superseded_by": null,
"revoked_at": null,
"owner_scope": "user:8831",
"consent_basis": "stated_directly"
}// PREFERENCE - acted on repeatedly; confirmation + visibility are mandatory
{
"memory_id": "pref_01HX...",
"subject": "user:8831",
"claim": "Default meeting time: morning",
"category": "preference",
"source_episode_ids": ["ep_01HX..."],
"confidence": 0.55, // single sarcastic source -> low, not 0.88
"confirmed_by_user": false, // <-- the field whose absence caused the incident
"applies_when": "scheduling AND agent has latitude on time",
"yields_to_live_intent": true, // present request overrides this default
"visible_to_user": true,
"editable_by_user": true,
"owner_scope": "user:8831"
}// TASK - has a lifecycle; expires on completion/abandonment
{
"task_id": "task_01HX...",
"subject": "user:8831",
"objective": "Migrate billing service to new schema",
"status": "in_progress | blocked | done | abandoned",
"subtasks": [
{"id": "st1", "desc": "data backfill", "status": "done"},
{"id": "st2", "desc": "cutover", "status": "blocked",
"blocker": "staging env unavailable"}
],
"decisions": [
{"choice": "keep old endpoint one release", "rationale": "client lag",
"episode_id": "ep_01HZ..."}
],
"created_at": "2026-02-01T09:00:00Z",
"expires_at": null, // tasks expire by status, not by clock
"owner_scope": "user:8831"
}Three things to notice across the schemas. First, owner_scope is never null and appears in every type; ownership is not optional, because it drives both access control and deletion (Chapter 11). Second, only the derived types (semantic, preference) carry source_episode_ids; the episodic type is the source, and the task type carries provenance per decision. Third, the preference schema's confirmed_by_user and yields_to_live_intent fields encode, as data, the two lessons of Chapter 1, confirm before acting, and let the live request win.
The SQL skeleton
For teams that want a relational backbone rather than a document store, here is a minimal multi-table design that preserves the taxonomy. The separation into tables is the point; resist the urge to UNION them into one.
-- The evidence layer. Append-only; never UPDATE or DELETE in normal ops.
CREATE TABLE episodic_memory (
episode_id TEXT PRIMARY KEY,
actor TEXT NOT NULL,
kind TEXT NOT NULL, -- utterance|action|tool_result|observation
content TEXT NOT NULL,
occurred_at TIMESTAMPTZ NOT NULL,
session_id TEXT,
owner_scope TEXT NOT NULL,
tool_call_id TEXT
);
-- Derived facts and preferences share a table but differ by category + rules.
CREATE TABLE semantic_memory (
memory_id TEXT PRIMARY KEY,
subject TEXT NOT NULL,
claim TEXT NOT NULL,
category TEXT NOT NULL, -- attribute|preference|relationship|...
confidence REAL NOT NULL,
confirmed_by_user BOOLEAN NOT NULL DEFAULT FALSE,
created_at TIMESTAMPTZ NOT NULL,
last_confirmed_at TIMESTAMPTZ,
expires_at TIMESTAMPTZ,
superseded_by TEXT REFERENCES semantic_memory(memory_id),
revoked_at TIMESTAMPTZ,
owner_scope TEXT NOT NULL,
consent_basis TEXT NOT NULL
);
-- Provenance is a join table: a memory can rest on several episodes.
CREATE TABLE memory_provenance (
memory_id TEXT NOT NULL REFERENCES semantic_memory(memory_id),
episode_id TEXT NOT NULL REFERENCES episodic_memory(episode_id),
evidence_span TEXT,
PRIMARY KEY (memory_id, episode_id)
);
-- Audit is its own immutable table; it must outlive deletions elsewhere.
CREATE TABLE memory_audit (
audit_id BIGSERIAL PRIMARY KEY,
at TIMESTAMPTZ NOT NULL DEFAULT now(),
op TEXT NOT NULL, -- write|recall|correct|revoke|hard_delete
memory_id TEXT, -- may reference an already-deleted row
actor TEXT NOT NULL, -- agent, user, or operator
detail JSONB NOT NULL
);The memory_provenance join table is where "a claim with a source" becomes enforceable: a semantic memory with zero provenance rows is, by construction, a rumor, and you can write a constraint or a periodic check that flags any such orphan. The memory_audit table referencing a memory_id that may no longer exist is deliberate, the audit trail must record that a memory once existed and was deleted, which is impossible if the audit row is foreign-keyed to require a live memory.
How each type decays: the lifecycle view
Decay is where the taxonomy proves its worth, because the types decay along completely different axes, and a single store cannot express that.
- Episodic decays by age and volume: raw episodes are eventually aged out or rolled into summaries, because you cannot keep every turn forever, but the derived semantic memories and the audit log persist. The episode is the receipt; you keep the receipt long enough to verify the derived facts, then you may shred the receipt while keeping the facts and the audit record.
- Semantic decays by re-confirmation: a fact does not expire on a clock so much as it grows uncertain the longer it goes unconfirmed. MemoryBank modeled this explicitly with an Ebbinghaus-inspired forgetting curve, where memory strength decays over time and is refreshed on re-access. You do not have to adopt that exact curve, but the principle, confidence should fall with staleness and rise on re-confirmation, is sound.
- Preference decays by behavioral contradiction: a preference is undermined not by time but by the user repeatedly doing the opposite. A morning-meeting preference should weaken every time the user reschedules to the afternoon, regardless of how long ago it was set.
- Procedural does not decay on a clock at all; it is retired by failure. A skill that worked yesterday and fails today should be flagged, versioned, and possibly rolled back, but its non-use is not evidence against it.
- Task decays by status transition, not time: it lives until it is done or abandoned, then it should stop being recalled as active (while remaining in the record).
- Environmental decays by a short TTL: it is stale almost immediately and must be re-verified.
A single store with one TTL cannot express six different decay semantics. That is the final, decisive argument for the taxonomy: not theoretical tidiness, but the brute fact that these objects die in incompatible ways, and a store that cannot let them die correctly will fill with stale, false, and zombie memories that no amount of better retrieval can rescue.
What this chapter sets up
The taxonomy is the map. Every later chapter operates on a region of it. The write gate (Chapter 4) is the door from episodic evidence into the derived stores. Recall (Chapter 5) reads across the user-facing types under a budget. Reflection (Chapter 6) is a controlled, gated derivation that produces new semantic and procedural memories from episodes. Skill libraries (Chapter 7) are procedural memory done seriously. Task memory (Chapter 8) is the long-horizon lifecycle. Shared memory (Chapter 9) adds scoping and authority. Forgetting (Chapter 10) implements the six decay semantics above. Governance (Chapter 11) operates on owner_scope and the audit log. Security (Chapter 12) defends the write gate against poisoning. And evaluation (Chapter 13) measures whether the whole thing makes the agent better.
But before any of that, we have to look at where memory actually lives in an agent, not at the bookends of a turn, but woven through every step of the action loop. That is the next chapter, and it is where agent memory stops resembling chatbot memory and becomes its own discipline.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.