Shared and Private Memory in Multi-Agent Systems
> **Working claim:** A single agent's memory is a private notebook.

Key Takeaways
- Shared and Private Memory in Multi-Agent Systems is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: A single agent's memory is a private notebook. The moment you have several agents, an orchestrator and its sub-agents, a fleet of specialists, a workspace they all touch, memory becomes shared infrastructure with concurrency, scoping, and trust problems that no single-agent design faces. Shared memory is the mechanism by which a team of agents becomes more than the sum of its parts, and it is the mechanism by which one agent's mistake, or one user's malice, becomes everyone's problem.
Why multi-agent memory is a different problem
Single-agent memory is a notebook one actor reads and writes. The actor sees its own writes, trusts its own observations, and the only conflicts are with its own past. Multi-agent memory breaks all three of those comforts at once. Now several actors read and write the same store; an actor reads memory another actor wrote and must decide how much to trust it; and conflicts arise not just across time but across agents holding different beliefs simultaneously. These are the classic problems of shared mutable state, concurrency, visibility, and trust, wearing an agent costume, and they do not go away because the actors are language models. They get harder, because the actors are non-deterministic and can be manipulated through their inputs.
Generative Agents hinted at the upside: agents that observed each other and remembered shared events coordinated emergent group behavior, a party got planned because information propagated through a population of memories. That propagation is exactly the value of shared memory: a sub-agent that discovers a fact writes it once, and every other agent that needs it can read it, so the team does not re-derive the same thing ten times. It is also exactly the risk: a sub-agent that writes a wrong fact propagates it to every agent that reads it, and a malicious actor who can write to shared memory can steer the whole fleet.
So the governing question for multi-agent memory is not "how do agents share?" but "what may be shared, by whom, with whom, and how much is it trusted?" Sharing without scoping and trust is not collaboration; it is a shared attack surface.
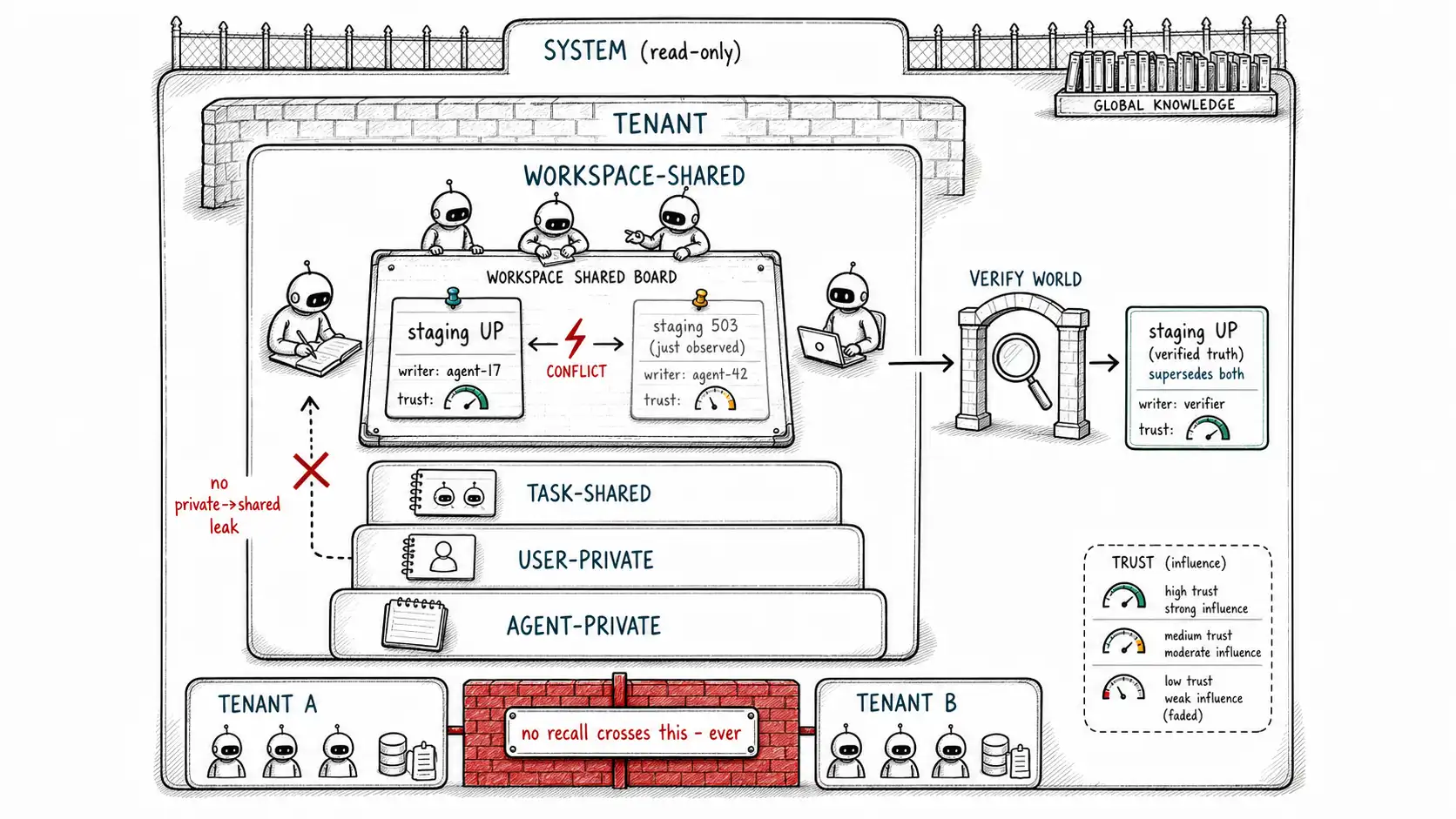
The scope hierarchy
The foundation is a scope hierarchy that says, for every memory, who may read it and who may write it. The single-agent owner_scope from Chapter 2 generalizes into a small lattice. Getting this lattice right is the whole ballgame, because scope is a hard boundary (Chapter 5): a recall query filters by scope before ranking, and a memory outside the requester's scope is invisible, not down-ranked.
| Scope | Readable by | Writable by | Example |
|---|---|---|---|
| Private (agent) | One agent instance | That agent | A sub-agent's working hypotheses, never exposed to siblings |
| Private (user) | One user's agents | The user's agents (gated) | "User is in Pacific time", personal, not the team's |
| Shared (task) | Agents working one task | Agents assigned to the task | "Cutover blocked on staging", relevant to this task's agents |
| Shared (workspace) | All agents in a workspace | Authorized agents/users | "This team deploys on Tuesdays", a team fact |
| Tenant | Everything under one tenant | Tenant admins / system | Org-wide policy and configuration |
| System | All agents (read-only) | Operators only | Tool availability, global constraints |
Two boundaries in this lattice are load-bearing for safety. The user-private to workspace-shared boundary is where most leaks happen: a fact about a single user must not be promoted to the workspace where the team can see it, unless the user consented to share it. The write gate's "most-restrictive owner" rule (Chapter 4) enforces this, a memory derived from a user-private episode cannot be written to a workspace scope. The tenant boundary is the one whose violation is a breach: under no ranking, no relevance, no convenience may one tenant's memory surface in another tenant's recall. We return to enforcing it adversarially in Chapter 12; here it is a structural invariant of the scope lattice.
What may be shared, and what must stay private
Not every memory type belongs in shared scope, and the taxonomy from Chapter 2 maps onto sharing rules that are worth making explicit, because the default instinct ("share everything so agents coordinate") is wrong.
- Episodic memory is mostly private by default. One agent's raw action log is not automatically the team's; sharing raw episodes broadly is a privacy and volume problem. Specific shared events (a deployment everyone should know about) are promoted deliberately.
- Semantic facts about the user are user-private unless the user shared them. The team does not need to know everything one member told their personal assistant.
- Semantic facts about the world/workspace are the natural shared content: "the staging URL is X, " "the on-call rotation is Y." These are exactly what a team of agents should pool.
- Procedural skills are often workspace-shared and high-value to share, the skill one agent learned for deploying this service should be available to all of them (see Voyager for the canonical treatment of shared skill libraries in multi-agent exploration), but, per Chapter 7, shared skills require human approval before use, because a shared skill runs on everyone's behalf.
- Task memory is task-shared among the agents collaborating on that task, which is what makes handoff (Chapter 8) possible.
- System memory is globally readable, operator-writable, never agent-writable.
The general rule: share facts about the shared world; keep facts about individuals private; gate shared procedures behind approval. A memory's subject, is this about the world, the workspace, or a person?, largely determines its natural scope, and conflating "the team should know how to deploy" with "the team should know what Sam told their assistant" is the multi-agent version of the single-store mistake.
Write authority: who gets to establish a shared fact
Shared memory needs write authority, a question single-agent memory never asks. When any agent can write any workspace fact, the workspace memory becomes whatever the loudest or most-manipulated agent says it is. Authority answers "who is allowed to establish a fact for the workspace, " and it is distinct from "who can read it."
def write_shared_memory(candidate: CandidateFact, agent: Agent,
scope: Scope, ctx: MemoryContext) -> WriteDecision:
d = WriteDecision(candidate)
# 1. Scope coherence: a shared write must not launder private data upward.
if derived_from_more_private_scope(candidate, scope, ctx):
return d.reject("would expose private data to a broader scope")
# 2. Write authority: not every agent may establish a workspace fact.
if not ctx.authority.may_write(agent, scope, candidate.category):
return d.route_to_authority_review(candidate, scope) # needs an authorized writer
# 3. Trust-weighting: shared facts carry the writer's identity + trust level,
# so readers can weigh them. A fact from a high-trust source outranks
# the same fact from an untrusted one.
d.writer_identity = agent.id
d.writer_trust = ctx.trust_level(agent, scope)
d.confidence *= d.writer_trust # untrusted writers produce weak memories
# 4. The standard MEMORY gate still applies on top of all the above.
return write_gate(candidate, ctx, scope_owner(scope)).merge(d)The writer_trust weighting is the key multi-agent idea, and it generalizes a defense we will need against poisoning (Chapter 12). A shared memory is not just a claim; it is a claim from a source with a trust level (see MemGPT for the foundational treatment of managing differentiated trust across memory tiers in long-running agents). A fact established by an authorized agent or a verified human is high-trust and recalls strongly. A fact written by a low-privilege sub-agent, or derived from untrusted external content, is low-trust and recalls weakly, present but unable to dominate. This means shared memory degrades gracefully under bad writes: a poisoned or mistaken low-trust write does not silently become workspace truth, because its trust weight keeps it from out-ranking the legitimately-established facts (see OWASP LLM Top 10 for the prompt injection and sensitive-information risks that motivate this trust-weighted design). A memory is a claim with a source becomes, in shared scope, *a memory is a claim with a source whose trust level governs its influence. *
When two agents disagree
The conflict that single-agent systems never see: two agents hold contradictory beliefs about the same shared subject at the same time. Agent A's memory says the staging environment is up; agent B just observed it returning 503. They are not disagreeing across time (the supersession case from Chapter 4), they disagree concurrently, and the shared store has to resolve it without letting the wrong one win.
Naive resolution, last-write-wins, is exactly wrong here, because the last writer is not necessarily the most correct; it is just the most recent, and an agent acting on stale data could overwrite a fresh, correct observation. Resolution should weigh evidence recency, source trust, and verifiability:
def resolve_shared_conflict(a: Memory, b: Memory, ctx: MemoryContext) -> Resolution:
# Prefer the claim backed by the more recent DIRECT observation of the world.
if a.is_direct_observation() and b.is_direct_observation():
winner = max(a, b, key=lambda m: m.observed_at) # freshest observation wins
elif a.is_direct_observation()!= b.is_direct_observation():
winner = a if a.is_direct_observation() else b # observation beats inference
else:
winner = max(a, b, key=lambda m: m.writer_trust) # trust breaks inference ties
# For consequential, verifiable facts, don't resolve by argument - VERIFY.
if winner.is_verifiable() and winner.is_consequential():
truth = ctx.verify_against_world(winner.claim) # re-fetch the actual state
return Resolution.from_world(truth, supersedes=[a, b])
return Resolution(winner=winner, loser=other(a, b, winner),
action="supersede") # keep both in record; mark currentThe escape hatch in the middle is the most important line: for a verifiable and consequential shared fact, the right resolution is not to pick a winner by trust or recency but to go check the world. The agents disagree about whether staging is up; rather than reasoning about who is more trustworthy, re-fetch and find out. This is environmental memory's "trust but verify" (Chapter 2) applied to inter-agent conflict, and it dissolves a whole class of disputes that no amount of trust-weighting resolves correctly, because the world has a ground truth the agents are merely modeling, and when you can cheaply consult it, you should.
Orchestrator and sub-agent memory
A common multi-agent shape is hierarchical: an orchestrator decomposes a task and spawns sub-agents, each handling a piece. Memory in this shape has a specific discipline. Sub-agents should have private working memory for their own reasoning (which the orchestrator does not need and should not be cluttered with) and write their results and durable findings to a task-shared scope the orchestrator and siblings can read. The anti-pattern is sub-agents writing their raw working memory to the shared scope, the orchestrator drowns in sub-agents' scratchpads, and the shared scope fills with transient hypotheses that should have died with each sub-task.
# Sub-agent: private scratchpad, shared results.
class SubAgent:
def run(self, subtask, shared: SharedMemory):
scratch = WorkingMemory() # PRIVATE: my reasoning, my hypotheses
result = self.solve(subtask, scratch) # ... iterate privately ...
# Write only the DURABLE FINDING to shared scope, gated + trust-tagged.
shared.write_finding(
Finding(subtask_id=subtask.id, conclusion=result.conclusion,
evidence=result.evidence_episode_ids, writer=self.id),
scope=Scope.task(subtask.task_id))
# scratch is discarded; it was never shared.This mirrors the working/durable split from Chapter 3, lifted to the multi-agent level: private working memory is to a sub-agent what working memory is to a single agent, the place to think, not the place to record. What gets shared is the finding, gated and trust-tagged, not the thinking. An orchestrator reading clean findings can coordinate; an orchestrator reading raw scratchpads is just running a noisier single agent.
Cross-agent staleness and cache coherence
Multi-agent memory revives the read-after-write coherence problem from Chapter 3, now across agents. Agent A writes a shared fact; agent B reads shared memory a moment later, does B see A's write? On an eventually-consistent shared store, maybe not, and B acts on a view of shared state that is already obsolete. Across a fleet making rapid shared writes, this can produce agents acting on mutually inconsistent views, with no single agent able to detect the divergence.
The defenses are, again, drawn from distributed systems, and the point is that you cannot wish them away by treating the store as "just memory." For consequential shared facts, prefer read-your-writes or stronger consistency on the shared task scope (it is small and bounded per task). For facts about the external world, do not rely on shared-memory coherence at all, re-verify against the world before consequential action, because the world is the real source of truth and shared memory is only a cache of beliefs about it. And design shared writes to be idempotent and conflict-aware (supersession, not blind overwrite) so that even out-of-order writes converge to a sensible state. The recurring lesson: shared agent memory is a distributed database with non-deterministic clients, and it deserves the same rigor about consistency you would give any shared mutable state (consistent with the NIST AI Risk Management Framework's Govern function, which treats shared infrastructure integrity as an organizational risk, not just a technical one).
What this chapter sets up
Multi-agent memory is where memory becomes infrastructure: a scope lattice that hard-bounds visibility, sharing rules keyed to what a memory is about, write authority so not every agent can establish a workspace fact, trust-weighting so bad writes degrade gracefully, conflict resolution that prefers fresh observation and verifies the world for consequential facts, an orchestrator/sub-agent split that shares findings rather than scratchpads, and consistency discipline for the shared store. It is the difference between a team of agents that compounds its knowledge and a fleet that propagates its mistakes.
Two threads run through everything so far and now demand their own chapters. The first is forgetting, every memory type decays differently, conflicts resolve over time, and a memory system that cannot forget is a liability, which is the next chapter. The second is the dark side of shared memory we have only gestured at: an adversary who deliberately writes false memory to steer the fleet, the subject of Chapter 12.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.