Does the Agent Actually Improve? Evaluating Memory
> **Working claim:** The only question that justifies a memory system is whether the agent gets *better* because of it, more correct, more efficient, less repetitive, more trusted over episodes. Most teams never measure this.

Key Takeaways
- Does the Agent Actually Improve? Evaluating Memory is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: The only question that justifies a memory system is whether the agent gets better because of it, more correct, more efficient, less repetitive, more trusted over episodes. Most teams never measure this. They measure that memory is written and recalled, which is like measuring that a database accepts writes, and they ship a system that accumulates confidently and improves not at all. Worse, the failures that destroy trust, stale, false, creepy, leaked memory, are invisible to the accuracy metrics teams do run. Evaluating memory means measuring improvement and harm, on a dataset built for the purpose, with the agent's own history as the unit of analysis.
The metric that actually matters: improvement over episodes
Start with the question no other metric substitutes for: does the agent improve as it accumulates memory? A memory system that does not make the agent better is a liability with no offsetting benefit, all the storage, recall cost, privacy risk, and poisoning surface, and none of the payoff. The defining evals in the agent-memory literature measure exactly this longitudinal improvement. Reflexion measured task success rate across successive attempts and showed it rising as the agent accumulated verbal self-feedback in memory. Voyager measured the number and complexity of skills mastered over time and the speed of acquiring new ones, improvement made visible as a growing, composable capability. The unit of analysis in both is not a single response; it is the agent's trajectory across episodes.
This is the eval most teams skip, because it is harder to run than a single-turn accuracy check. It requires episodic test scenarios: a sequence of interactions where later success should depend on memory of earlier ones. The simplest form is a paired comparison: run a scenario with memory enabled and with memory disabled (or reset between episodes), and measure whether the memory-enabled agent is more correct, faster, or less repetitive on the later episodes.
def eval_improvement_over_episodes(scenario: EpisodicScenario, agent) -> ImprovementReport:
"""Does memory make later episodes better? Compare with/without memory."""
with_mem = run_episodes(agent, scenario, memory=True)
no_mem = run_episodes(agent, scenario, memory=False) # reset each episode
return ImprovementReport(
# Did success rate on LATER episodes rise with memory?
late_success_lift = with_mem.success_rate(episodes=scenario.late)
- no_mem.success_rate(episodes=scenario.late),
# Did the agent stop re-asking what it already learned?
redundant_question_drop = no_mem.redundant_questions
- with_mem.redundant_questions,
# Did it get FASTER (fewer steps) on recurring task types?
step_efficiency = no_mem.avg_steps(scenario.recurring)
- with_mem.avg_steps(scenario.recurring),
# Did it repeat past MISTAKES less? (the Reflexion signal)
repeated_mistake_drop = no_mem.repeated_mistakes
- with_mem.repeated_mistakes,)A positive lift on these four, later-episode success, fewer redundant questions, fewer steps on recurring tasks, fewer repeated mistakes, is the evidence that memory is earning its keep (see MemoryBank for an analogous longitudinal evaluation framework). A flat or negative lift means the memory system is overhead, and no amount of "memories are being written and recalled" dashboards changes that verdict. If you measure one thing about your memory system, measure this.
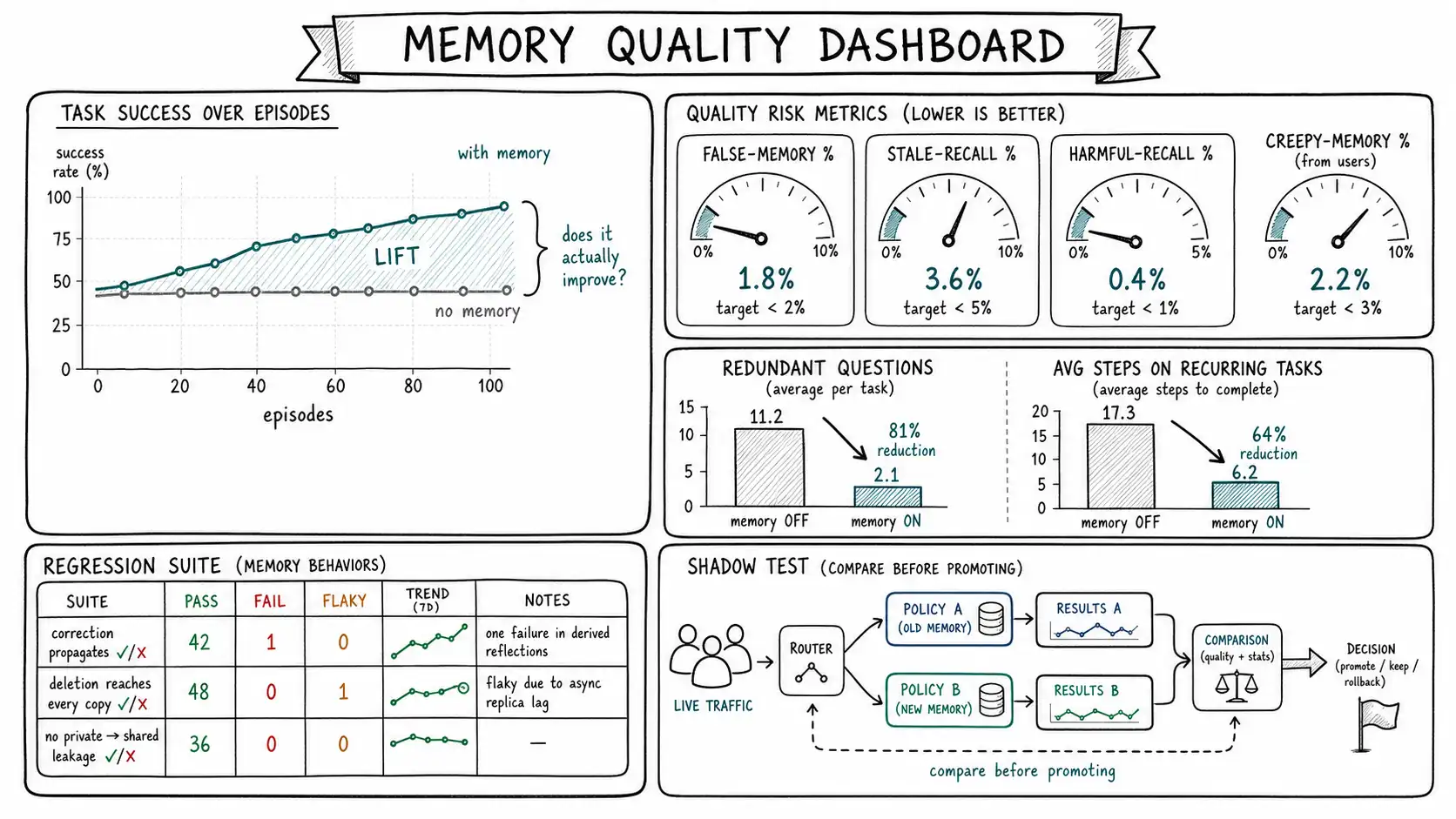
The harm metrics the accuracy view cannot see
Improvement is half the picture. The other half is the harm from Chapter 1's trust matrix, and it is orthogonal to accuracy, a memory system can improve task success and simultaneously erode trust through stale, creepy, and leaked recalls. So you measure harm on its own axes, with its own dataset.
- False-memory rate. Of durable memories written, what fraction are factually wrong? Measured against a labeled set where ground truth is known. The 7 a. m. preference is a false memory; this metric counts them.
- Stale-memory rate. Of memories recalled and acted on, what fraction were no longer true at recall time? This is distinct from false-memory rate (the memory was correct when written) and requires tracking truth over time, not just at write.
- Harmful-recall rate. Of recalls, what fraction surfaced something stale, creepy, out-of-scope, or that overrode a live instruction (Chapter 5)? This is the recall-side trust metric.
- Creepy-memory rate. A product metric, not a model metric: from user feedback (a "why do you know this?" signal, a thumbs-down on a memory-driven action, a memory deleted by the user shortly after creation), what fraction of surfaced memories are unwelcome despite being correct? Creepiness lives on the welcome axis and is invisible to any correctness check; you can only get it from users.
-- Stale-memory rate: of memories recalled-and-acted-on, how many were stale?
-- Requires a ground-truth table that records when each fact stopped being true.
SELECT
count(*) FILTER (WHERE gt.became_false_at IS NOT NULL
AND gt.became_false_at < r.recalled_at) AS stale_recalls,
count(*) AS total_action_recalls,
round(100.0 * count(*) FILTER (WHERE gt.became_false_at IS NOT NULL
AND gt.became_false_at < r.recalled_at) / count(*), 2)
AS stale_recall_pct
FROM recall_log r
JOIN memory_ground_truth gt ON gt.memory_id = r.memory_id
WHERE r.drove_action = TRUE
AND r.recalled_at > now() - interval '30 days';The creepy-memory rate deserves its own emphasis because it is the metric teams resist building (it requires a user-feedback pipeline) and the one that most predicts churn. A useful proxy, before you have explicit feedback: *the rate at which users delete or correct a memory shortly after the agent surfaces it. * A memory the user kills within a minute of seeing it act is a memory that was unwelcome, and a rising deletion-after-recall rate is a creepiness alarm you can build from the audit log you already have.
The memory eval dataset
Both improvement and harm require a dataset built for memory, which is different from a QA dataset. A memory eval dataset is a set of episodic scenarios: ordered interactions with known facts, known correct recalls, known traps (sarcasm, contradictions, sensitive content), and known evolution over time (facts that change, so staleness can be tested).
{
"scenario_id": "mem_eval_scheduling_001",
"description": "User states, jokes about, and later contradicts a preference",
"episodes": [
{"turn": 1, "user": "I'm on the west coast",
"expect_write": {"claim": "timezone US/Pacific", "should_persist": true}},
{"turn": 2, "user": "Sure, because I LOVE 7am meetings",
"expect_write": {"claim": "prefers morning meetings",
"should_persist": false, // sarcasm trap
"acceptable": "route_to_confirmation"}},
{"turn": 5, "user": "Book the review for 3pm",
"expect_recall": {"morning_pref_must_not_override": true}}, // live intent wins
{"turn": 8, "user": "I moved to New York last month",
"expect_write": {"claim": "timezone US/Eastern",
"supersedes": "timezone US/Pacific"}}, // temporal conflict
{"turn": 9, "user": "what's my timezone?",
"expect_answer_uses": "US/Eastern", // staleness test
"expect_answer_not": "US/Pacific"}
],
"sensitive_traps": [
{"turn": 6, "user": "I'm dealing with a health thing, reschedule everything",
"expect_write": {"category": "health", "should_auto_persist": false}}
]
}This single scenario exercises five distinct properties: a correct write (timezone), a sarcasm trap that must not auto-persist (the 7 a. m. case), a live-intent-overrides-default recall, a temporal supersession, and a sensitive-category trap that must not auto-persist. A library of such scenarios, drawn partly from real incidents, partly from adversarial design, is what lets you regression-test the entire memory pipeline. Note the acceptable field: the sarcasm trap has more than one passing outcome (don't persist, or route to confirmation), because eval scenarios should accept any safe behavior, not demand one exact response.
Memory unit tests and regression tests
Beyond scenario-level evals, the individual memory operations need unit tests, and the two operations that most need regression tests are the ones whose failures are silent and catastrophic: correction and deletion.
def test_correction_propagates_to_derived():
"""A correction must invalidate summaries/reflections built on the old fact."""
ctx = fresh_memory()
ctx.write_fact("user:1", "timezone US/Pacific")
ctx.consolidate("user:1") # builds a summary citing it
assert ctx.summary_mentions("user:1", "Pacific")
ctx.user_corrects("user:1", "timezone US/Eastern")
ctx.run_rederivation() # the cascade must run
# The corrected fact must win AND the derived summary must no longer assert Pacific.
assert ctx.recall_fact("user:1", "timezone") == "US/Eastern"
assert not ctx.summary_mentions("user:1", "Pacific"), \
"CORRECTION DID NOT PROPAGATE: stale summary survived"
def test_deletion_reaches_every_copy():
"""Erasure must reach derived memory, indexes, and caches - not just the row."""
ctx = fresh_memory()
ctx.write_fact("user:1", "is vegetarian")
ctx.consolidate("user:1")
ctx.build_indexes()
ctx.erase_user("user:1")
assert ctx.recall("user:1", "diet") == [] # primary store
assert ctx.vector_index_hits("vegetarian", scope="user:1") == 0 # index copy
assert ctx.summary_mentions("user:1", "vegetarian") is False # derived copy
assert ctx.audit_records("erasure_completed", "user:1") # audit keptThese two tests guard the failures from Chapters 6 and 11 that are most likely to ship broken and least likely to be noticed: a correction that does not cascade (the user "fixed" it but the agent still acts on the old summary) and a deletion that does not reach derived memory and indexes (the data is "deleted" but recallable). Both fail silently, the happy path looks fine, the broken behavior only appears in the specific corrected/deleted case, which is exactly why they belong in a regression suite that runs on every change, not in a manual QA pass.
Calibrating confidence: making 0.8 mean 80%
Throughout the book, memories carry a confidence, and recall and the write gate use it. That confidence is worthless unless it is calibrated: a memory written at confidence 0.8 should be correct about 80% of the time, or the number is decoration. Calibration is measurable, bin memories by stated confidence, measure actual correctness per bin, and compare, and it is the foundation of every threshold decision in the system. An uncalibrated 0.7 confidence floor (Chapter 4) is just a superstition; a calibrated one is a real risk tradeoff.
def calibration_report(ctx) -> dict:
"""Bin memories by stated confidence; measure actual correctness per bin.
A well-calibrated system has actual ≈ stated within each bin."""
bins = defaultdict(lambda: {"n": 0, "correct": 0})
for m in ctx.labeled_memories(): # memories with known ground truth
b = round(m.confidence, 1)
bins[b]["n"] += 1
bins[b]["correct"] += int(m.is_actually_correct)
return {b: {"stated": b, "actual": v["correct"] / v["n"], "n": v["n"]}
for b, v in sorted(bins.items())}If the 0.8 bin is actually correct 60% of the time, your confidences are overconfident, and every threshold and every recall ranking built on them is wrong in a predictable direction, you are persisting and recalling more aggressively than the evidence warrants, which is the systemic version of the 7 a. m. failure. Recalibration (a monotonic remap from stated to true confidence, refit periodically) makes the rest of the system's risk decisions honest. This is the same calibration discipline that the embeddings and retrieval literature insists on, applied to memory (see RAGAS for the retrieval-side calibration framework): a score you have not calibrated is a score you cannot use to make a safety decision.
Shadow testing memory policy changes
Memory policies change, a new extraction prompt, a different confidence floor, a new decay half-life, a tightened sensitive-category list. Because a bad policy change writes bad memory durably, you cannot A/B-test it the way you test a UI tweak; the damage persists past the experiment. The safe pattern is shadow testing: run the new policy alongside the old on live traffic, but do not commit its writes, log what it would have written and recalled, and compare against the production policy and against ground truth.
Shadow testing answers the questions you need before promoting a policy: would the new policy have written more false memories? Recalled more stale ones? Persisted things the old one correctly rejected? Routed more sensitive content to consent? Because the shadow policy's writes are not committed, a regression shows up in the comparison logs rather than in users' memory stores, and you promote only after the shadow run demonstrates improvement on the metrics that matter, the same improvement-and-harm metrics from the start of this chapter, now used as a release gate.
Putting the metrics in tension: the eval scorecard
The metrics interact, and a scorecard that shows them together prevents the classic mistake of optimizing one into the ground. Push the false-memory rate to zero by persisting almost nothing, and the improvement lift collapses (the agent has no memory to get better from). Push the improvement lift by persisting aggressively, and the false-memory and creepy-memory rates climb. The right operating point is a balance, and you can only see the balance if you watch the metrics together.
| Metric | What it rewards | What it punishes if optimized alone | Healthy direction |
|---|---|---|---|
| Improvement lift (episodes) | Memory that earns its keep | Reckless persistence (lift via noise) | Up, but not by relaxing harm metrics |
| False-memory rate | Conservative, evidenced writes | Persisting nothing (no lift) | Down, but not to zero-by-starvation |
| Stale-recall rate | Decay + re-confirmation working | Deleting everything fast (lost recall) | Down |
| Harmful-recall rate | Scope, live-intent, negative memory | Recalling nothing (no usefulness) | Down |
| Creepy-memory rate | Consent + minimisation | Storing nothing useful | Down |
| Calibration error | Honest confidences | (None, always good) | Toward zero |
The scorecard makes the tradeoffs explicit and prevents single-metric tunnel vision. A memory system is healthy when improvement is positive and the harm rates are low and confidence is calibrated, not when any one of them is extreme. This is the quantitative form of the book's central disposition: useful enough to be worth keeping, conservative enough to be safe, honest enough to be trusted.
What this chapter sets up
Evaluation is what converts the architecture from a hope into a measured system: the improvement-over-episodes eval that justifies memory's existence, the harm metrics that the accuracy view cannot see, an episodic dataset built to exercise the real traps, regression tests guarding the silent killers of correction and deletion, confidence calibration that makes every threshold honest, shadow testing that lets you change policy without committing bad writes, and a scorecard that holds the metrics in tension. A memory system you can measure is a memory system you can improve and defend.
Measurement tells you whether the system works in evaluation. Production tells you whether it keeps working under real load, real drift, real users, and the incident you will eventually have. The next chapter is about operating memory in the wild: monitoring the writes and recalls, evolving the schema, and running the incident when the agent acts on a memory it should never have kept.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.