Recall Is Not Retrieval
> **Working claim:** Retrieval finds memories that match a query. Recall decides which of those memories should actually shape the agent's next action, and that is a different, harder problem.

Key Takeaways
- Recall Is Not Retrieval is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: Retrieval finds memories that match a query. Recall decides which of those memories should actually shape the agent's next action, and that is a different, harder problem. A memory can be relevant, recent, and high-confidence and still be the wrong thing to inject, because it is out of scope, because it contradicts the user's live instruction, or because surfacing it costs more trust than it returns. The recall layer's job is not to maximize matches; it is to assemble the smallest set of memories that improves the current action without dominating it.
The word "recall" is hiding two operations
When a team says "the agent recalls the user's preferences, " they are describing two operations that have been fused and should be pulled apart. The first is retrieval: given the current task, find candidate memories that match. This is the part a vector store does, similarity search, maybe with metadata filters. The second is recall proper: from those candidates, select, rank, scope, and frame the few that should enter the prompt and shape behavior. Retrieval is necessary and easy. Recall is the hard part, and it is where agents go wrong in ways that retrieval metrics never catch.
The distinction matters because optimizing retrieval, better embeddings, a reranker, a higher top-k, does nothing for the failures that actually hurt. The 7 a. m. preference was perfectly retrieved: it matched the scheduling task, it was recent, it was high-confidence. Retrieval did its job flawlessly. The failure was in recall: the system selected a stale, wrong preference and let it dominate the user's live request. No improvement to the retriever fixes that, because the retriever was never wrong. The recall layer was missing.
Generative Agents framed retrieval as a weighted combination of relevance, recency, and importance, a good start, and we will build on it. But agents need more than a ranking score. They need scoping (whose memory may surface here), conflict resolution against the live instruction, budgeting against context limits, and framing so a recalled memory informs rather than commandeers. Ranking is one of five jobs, and the smallest source of real failures.
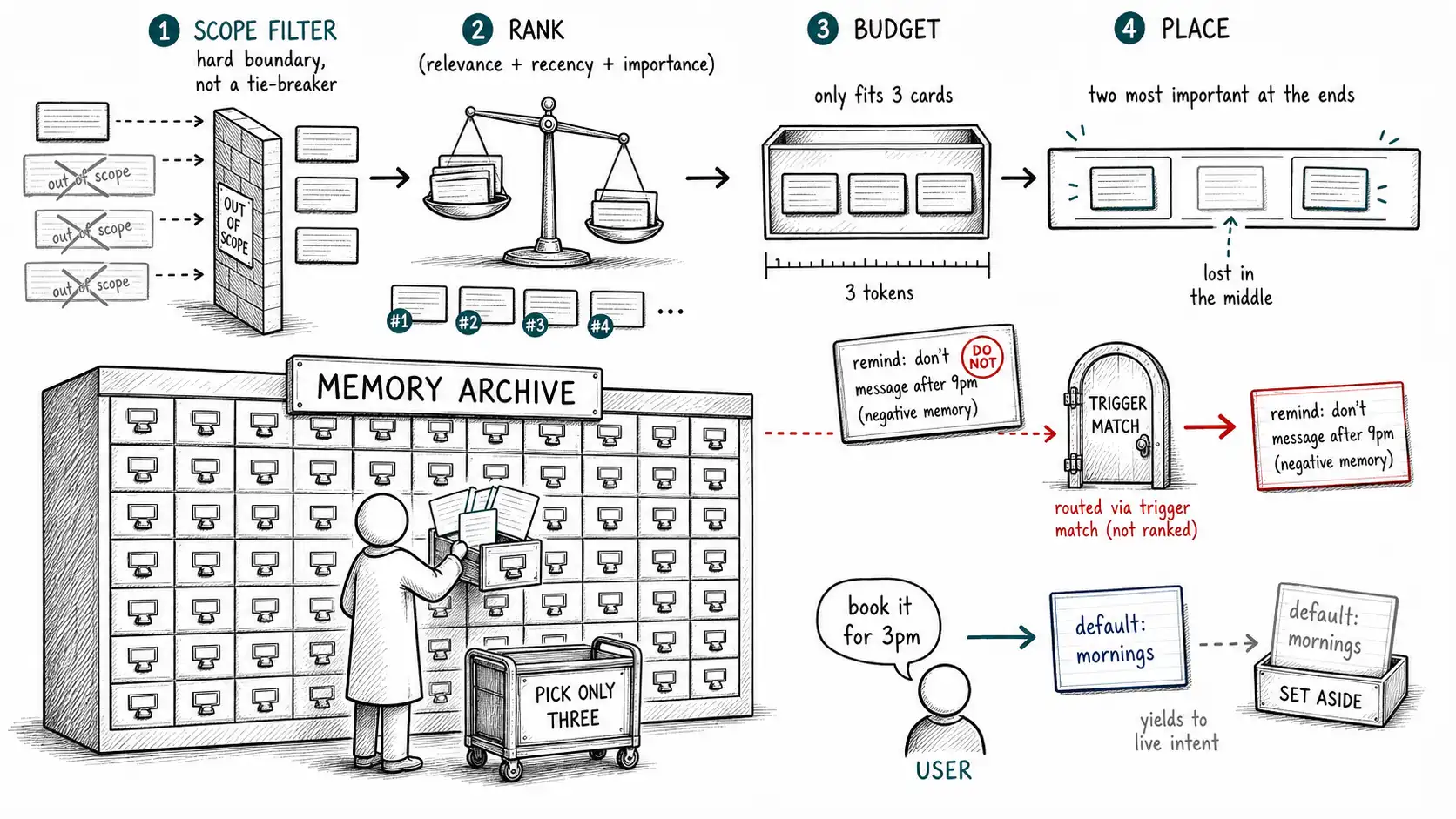
The three-signal score, and its limits
Start with the standard recall score, because it is genuinely useful before it is dangerous. A memory's recall priority combines three signals:
- Relevance, how well it matches the current task. Semantic similarity plus metadata match (category, subject, entities mentioned).
- Recency, how recently it was created or re-confirmed. A fact confirmed yesterday outranks one from a year ago, all else equal.
- Importance: a stored measure of how consequential the memory is, set at write time."User is allergic to penicillin" is more important than "user mentioned liking jazz once."
def recall_score(m: Memory, task: Task, now: datetime) -> float:
relevance = semantic_match(m, task) + metadata_match(m, task)
age_days = (now - (m.last_confirmed_at or m.created_at)).days
recency = math.exp(-age_days / m.half_life_days) # category-specific decay
importance = m.importance # set at write (0..1)
return (W_REL * relevance) + (W_REC * recency) + (W_IMP * importance)This is a fine retrieval ranker (see MemoryBank for the Ebbinghaus-inspired decay model that this recency term is derived from). Its limits are exactly the failures it cannot see. It will happily rank a stale preference highly if it was recently re-confirmed by the agent's own erroneous repetition (the rumination problem from Chapter 3). It will surface an in-scope-but-creepy memory because creepiness is not one of its terms. It will inject a memory that contradicts the user's current sentence because it scores the memory in isolation from the live instruction. The three-signal score decides what matches; it does not decide what should win. Treating it as the whole recall layer is the most common recall mistake.
Scope before score
Before any ranking, recall must apply scope, and scope is a hard boundary, not a ranking penalty. This is the single most important recall rule for multi-tenant and multi-user systems, and getting it wrong is not a quality problem: it is a data breach.
A recall query carries the requesting identity: which user, which tenant, which workspace, in which session. Memories are filtered to those the requester is permitted to see before they are scored, and a memory outside scope is not down-ranked, it is invisible. The reason scope must precede scoring is that a sufficiently relevant out-of-scope memory could otherwise out-score in-scope ones and leak. You never want a world where "this other tenant's memory was just so relevant it surfaced anyway."
-- Scope is a WHERE clause that runs before ranking, never a tie-breaker after.
SELECT memory_id, claim, category, confidence, importance,
created_at, last_confirmed_at, half_life_days, recall_semantics
FROM semantic_memory
WHERE owner_scope = ANY(:permitted_scopes) -- HARD boundary: user + their workspaces
AND revoked_at IS NULL -- deleted memories never recall
AND superseded_by IS NULL -- only the current version of a fact
AND (expires_at IS NULL OR expires_at > now()) -- expired memories never recall
AND category = ANY(:relevant_categories)
ORDER BY confidence DESC
LIMIT:retrieval_k; -- over-fetch candidates; recall narrows furtherThree of those WHERE clauses are doing safety work that ranking cannot do. revoked_at IS NULL guarantees a deleted memory cannot resurface no matter how relevant, deletion that only down-ranks is not deletion (Chapter 11). superseded_by IS NULL guarantees the agent recalls the current version of a fact, not the outdated one it replaced, the antidote to acting on the obsolete-but-detailed memory. expires_at > now() guarantees a stale-by-policy memory is gone. These are correctness invariants enforced at the query, not heuristics applied at the prompt, because a heuristic the model can override is not an invariant.
The context budget: recall competes for attention
Even after scope and scoring, recall faces a constraint the retrieval framing ignores: the recalled memories must fit, and fitting is not just about token limits. Lost in the Middle established that models attend unevenly across a long context, information in the middle of a crowded prompt is attended to least reliably. A memory you recall and bury in the middle of twenty other memories may be functionally invisible to the model, and a wrong memory placed prominently may win over a correct one placed poorly. So recall has a budget, and spending it well means recalling few, high-value, well-placed memories rather than many.
This inverts the instinct. The instinct is "recall everything relevant so the agent has full context." The reality is that every marginal memory dilutes the signal and risks pushing a load-bearing memory into the inattentive middle. The recall budget should be small, often a handful of memories, and the selection should be ruthless. MemGPT's entire design is about this: the model's directly-visible context is a scarce resource, and memory is paged in deliberately rather than dumped. Treat your recall budget the way an OS treats physical memory: precious, explicitly managed, and worth evicting from.
def pack_memories(candidates: list[Memory], task: Task, budget_tokens: int):
ranked = sorted(candidates, key=lambda m: recall_score(m, task, now()),
reverse=True)
selected, used = [], 0
for m in ranked:
cost = token_count(render_memory(m))
if used + cost > budget_tokens:
continue # skip; do not truncate a memory mid-claim
selected.append(m)
used += cost
# Place highest-priority memories at the edges, not the middle (Lost in the
# Middle): most-important first and last, lower-priority in the interior.
return edge_weighted_order(selected)The edge_weighted_order is not superstition; it is a direct response to the positional-attention finding. If you have five memories and the model attends best to the start and end of the block, put the two most consequential ones there. The budget cap and the placement together do more for recall quality than any reranker, because they respect how the model actually consumes the context rather than assuming uniform attention.
When memory and the live instruction disagree
Here is the recall failure that retrieval can never address, because it is not about the memory at all, it is about the relationship between the memory and the user's current words. The user has a stored preference for morning meetings (suppose, this time, it is correct and confirmed). Today they say: "Book the review for 3 p. m." The recall layer surfaces the morning preference. What should the agent do?
The answer is not subtle, but systems get it wrong constantly: the live instruction wins. A stored preference is a default, an inference about what the user usually wants in the absence of a specific instruction. A live instruction is a specific instruction. A default that overrides a specific instruction is not a helpful memory; it is an agent arguing with its user. This is why the preference schema in Chapter 2 carried yields_to_live_intent: true and why the write gate set recall_semantics. The metadata exists so recall can resolve this conflict deterministically rather than leaving it to the model's mood.
def resolve_against_live_intent(memory: Memory, live_intent: Intent) -> Disposition:
if not memory.yields_to_live_intent:
return Disposition. INFORM # e.g. a hard constraint, always applies
if live_intent.specifies(memory.dimension):
# User gave a specific value on the same dimension the memory defaults.
return Disposition. SUPPRESS_AS_DEFAULT # don't inject as a competing default
# (optionally: note the discrepancy for confirmation, never act on it)
return Disposition. INFORM # no live instruction on this dimensionWhen the user says 3 p. m. and the memory is a 9 a. m. default, the memory is suppressed as a default, it does not enter the prompt as a competing instruction. Optionally, the agent may note the discrepancy ("I've booked 3 p. m.; want me to update your usual morning default?") but it does not act on the stale default. The general principle: recall serves the current task; it does not relitigate the user's explicit choices. A memory system that makes the agent stubborn is worse than one with no memory, because stubbornness reads as the agent thinking it knows better than you.
Negative memory: remembering what not to do
A category of memory that retrieval-centric designs miss entirely: negative memory, the durable record of what the agent should not do."Do not suggest restaurant X, the user had a bad experience." "Never auto-merge this user's PRs." "This customer asked not to be contacted by phone." Negative memories are some of the highest-value memories an agent can hold, because violating them is precisely the failure users remember, and they have different recall semantics: a negative memory should be recalled whenever its trigger condition is approached, even if the current task does not obviously match it on similarity.
The danger with negative memory is that similarity-based retrieval may not surface it at the right moment. The user is planning a dinner; the agent considers restaurants; the negative memory "do not suggest restaurant X" should fire, but if it was stored as a terse note, its embedding may not strongly match the current task framing. So negative memories are best stored with explicit trigger conditions rather than relying on similarity, and recall checks triggers separately from the similarity path.
{
"memory_id": "neg_01HX...",
"subject": "user:8831",
"claim": "Do not suggest restaurant 'Alto' for dinner recommendations",
"category": "negative",
"recall_semantics": "constraint",
"trigger": {"action_type": "recommend", "domain": "restaurant"},
"source_episode_ids": ["ep_01HZ..."],
"evidence_spans": ["never recommend Alto again, that was a disaster"],
"yields_to_live_intent": false, // a 'do not' is not a default to override
"owner_scope": "user:8831"
}Note yields_to_live_intent: false: a negative memory is a constraint, not a default, so it does not quietly yield. If the user explicitly says "actually, book Alto, " that is a live override of a constraint and should be confirmed, not silently obeyed, the asymmetry is deliberate, because the cost of violating a "do not" is high.
Citations: recall that can defend itself
A recalled memory that shapes an action should be traceable back to its source, both for the agent's own reasoning and for after-the-fact audit. When the agent acts on "user is in Pacific time, " it should be able to point to the episode where that was established. This is the recall-side payoff of the provenance the write gate insisted on: a memory is a claim with a source, and recall carries the source forward.
@dataclass
class RecalledMemory:
memory_id: str
claim: str
confidence: float
source_episode_ids: list[str] # carried from the store
recalled_at: datetime
recall_reason: str # why this surfaced: "matched scheduling task"The recall_reason and source_episode_ids serve three purposes. For the agent, they let it weigh a memory's trustworthiness ("this is from a direct statement" versus "this was inferred from a tool result"). For the user, they enable explanations ("I scheduled mornings because you set that default on March 4, change it?"). For the operator, they make the incident in Chapter 14 tractable: when a wrong memory drives a bad action, the recall log shows exactly which memory surfaced, why, and from what evidence. A recall that cannot explain itself is a recall you cannot debug.
Measuring recall: precision, recall, and the metric that matters
Borrowing the framing from retrieval evaluation, and from tools like RAGAS for retrieval quality, we can measure the recall layer with familiar metrics, but the interesting one is agent-specific. Standard recall precision asks: of the memories surfaced, how many were relevant and correct? Standard recall recall asks: of the memories that should have surfaced, how many did? Both matter. But the metric that predicts user trust is harmful-recall rate: how often did recall surface a memory that was stale, creepy, out of scope, or that overrode a live instruction? A system can have excellent precision and recall and still erode trust through harmful recalls, because the harmful-recall axis is orthogonal to the relevance axis, exactly the lesson of the trust matrix in Chapter 1.
We build the full eval harness in Chapter 13. The point here is that you cannot evaluate recall as if it were retrieval. Retrieval metrics reward matching. Recall must additionally penalize matching the wrong thing at the wrong time, surfacing the stale, the creepy, the out-of-scope, and the live-instruction-overriding, and those penalties are where the real quality of an agent's memory lives.
What this chapter sets up
Recall is the second of the two operations the loop touches most, and we have now separated it cleanly from retrieval: scope is a hard boundary applied first; ranking combines relevance, recency, and importance but is only one of recall's jobs; the budget is small and placement matters because the model attends unevenly; the live instruction beats the stored default; negative memory fires on triggers, not similarity; and every recalled memory carries its source so it can defend itself.
Reads and writes are now both governed. But agents do not only read and write the memories they are given, they manufacture new memories by reflecting on their experience, compressing many episodes into summaries and generalizations. That manufacturing is generative, and generative means it can invent. The next chapter is about reflection and consolidation, and about the summaries that quietly lie.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.