Reflection, Consolidation, and the Summaries That Lie
> **Working claim:** An agent that reflects is an agent that improves without retraining, but reflection is *generative*, and generative means it invents structure that was not in the evidence.

Key Takeaways
- Reflection, Consolidation, and the Summaries That Lie is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: An agent that reflects is an agent that improves without retraining, but reflection is generative, and generative means it invents structure that was not in the evidence. A summary can compress three correct episodes into one confidently wrong generalization. A reflection can promote a coincidence to a pattern. The discipline of consolidation is to let the agent derive higher-order memory while keeping every derived claim traceable to the raw events that justify it, and to invalidate the derivation the moment those events are corrected.
Why agents reflect at all
An agent accumulates episodic memory relentlessly, every action, every tool result, every turn. Raw episodes are the most truthful memory the system has, because they record what happened without interpretation. They are also useless at scale. You cannot recall ten thousand raw episodes into a prompt, and you cannot reason over them directly (see Lost in the Middle for the finding that language models attend unevenly to long contexts, making raw-episode flooding doubly counterproductive). So the agent must compress: turn many low-level events into a few high-level memories it can actually use. That compression is reflection, and it is what lets an agent get better over time without anyone touching its weights (see MemGPT for the foundational treatment of managing tiered memory tiers through paging and compression in long-running agents).
Generative Agents made this mechanism explicit and influential. Its agents periodically paused, retrieved their most salient recent observations, and reflected, asked themselves what those observations implied, and wrote the answers back as higher-level memories that then informed future behavior. A character who observed many small interactions with a neighbor would reflect into "I get along well with this person, " and that synthesized belief shaped subsequent actions. Reflexion applied the same idea to task performance: after a failed attempt, the agent wrote a verbal self-critique into memory ("I failed because I didn't check the precondition"), and recalling that critique on the next attempt improved the outcome, learning from experience, stored as text, with no gradient update.
This is genuinely powerful. It is also the most dangerous thing in this book, because reflection is the one memory operation that creates claims the user never made. The write gate in Chapter 4 governed candidates extracted from what the user said. Reflection governs candidates the agent invented. A summary is the agent speaking, not the user, and an agent's confident generalization about a person is a hypothesis dressed as a fact.
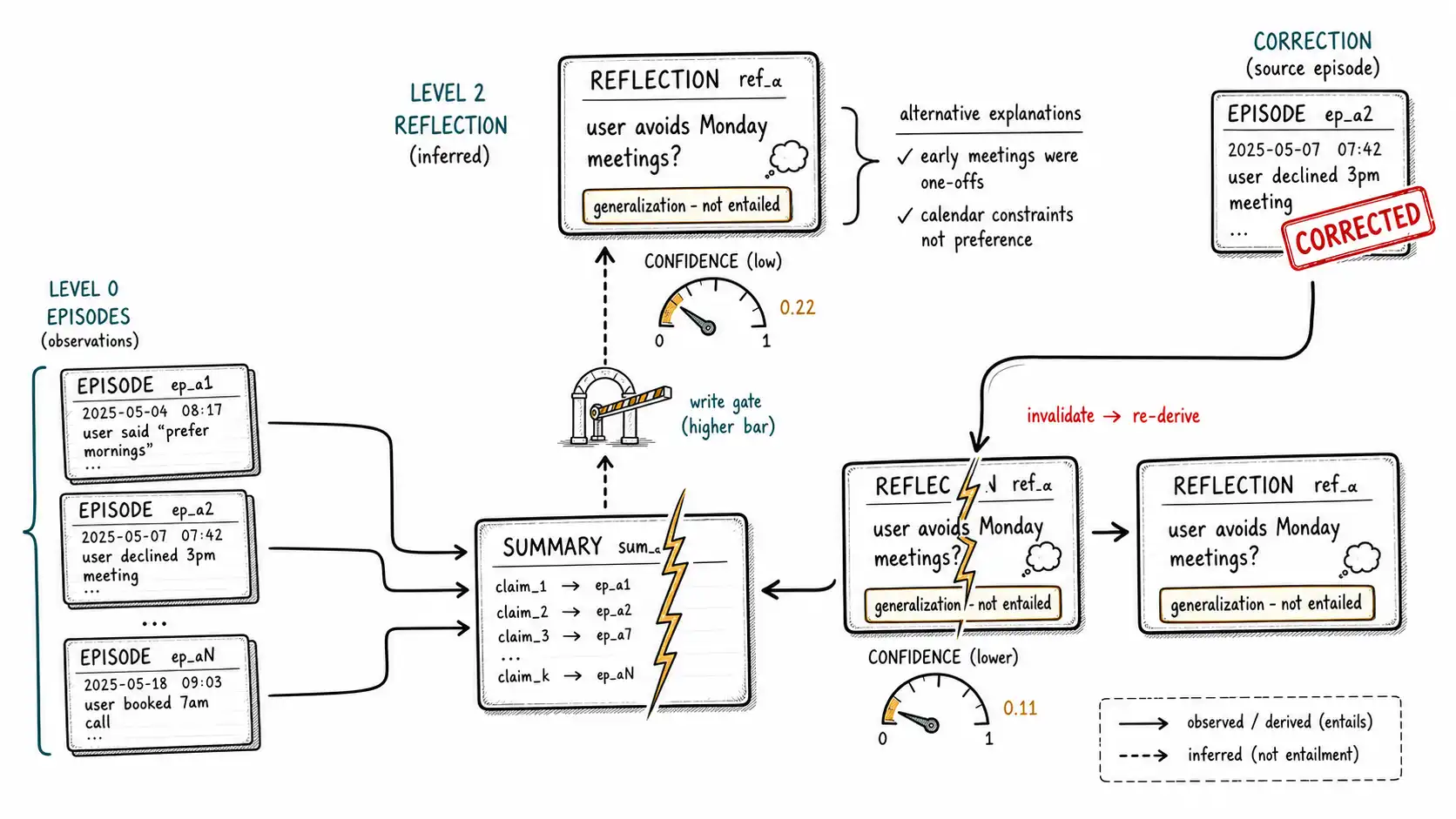
The three levels of memory, and the lie that lives between them
It helps to see consolidation as moving up a ladder of abstraction, because each rung is further from the evidence and closer to invention.
- Level 0, raw episodes. "User rescheduled the Monday call to Thursday." Truthful, specific, voluminous.
- Level 1, summaries. "User rescheduled three calls this week." A faithful compression: every claim in it traces to specific episodes, and it asserts nothing the episodes do not support.
- Level 2, reflections. "User dislikes Monday meetings." A generalization: it goes beyond the episodes to assert a durable disposition. The episodes are consistent with it, but they do not entail it. The user may have rescheduled those three Monday calls for three unrelated reasons.
The lie lives in the jump from Level 1 to Level 2. A faithful summary is low-risk; it is compression, and you can verify it against its sources. A reflection is high-risk; it is inference, and the same evidence supports many incompatible reflections."Dislikes Monday meetings" and "had an unusually chaotic week" and "is rescheduling around a one-time conflict" all fit the same three episodes. The reflection picks one and writes it as a durable belief the agent will act on, and if it picks wrong, you have manufactured a false preference exactly like the 7 a. m. memory, except this time the agent invented it from real data, which makes it more insidious because the provenance looks clean. The episodes are real. The generalization is a guess.
So the central rule of consolidation: treat summaries and reflections as different objects with different write rules. A summary may be written relatively freely because it adds no new claims. A reflection is a candidate fact like any other and must clear the full write gate, and, because it is the agent's invention rather than the user's statement, it should clear it at a higher bar: more corroborating episodes, lower default confidence, and a strong bias toward confirmation before it is allowed to drive behavior.
Provenance-preserving summaries
The mechanism that keeps consolidation honest is the same one that keeps everything else honest: provenance. A summary or reflection must carry the IDs of the episodes it rests on, so that it can be verified, explained, and, critically, invalidated when those episodes change.
// A SUMMARY: faithful compression, every claim traces to sources.
{
"memory_id": "sum_01HX...",
"kind": "summary",
"subject": "user:8831",
"text": "Over the past week the user rescheduled three meetings: the Monday "
"planning call (to Thursday), the Tuesday 1:1 (to Wednesday), and the "
"Monday review (cancelled).",
"source_episode_ids": ["ep_a1", "ep_a2", "ep_a3", "ep_a4"],
"claims": [ // each claim mapped to its supporting episodes
{"claim": "rescheduled Monday planning call to Thursday", "episodes": ["ep_a1"]},
{"claim": "rescheduled Tuesday 1:1 to Wednesday", "episodes": ["ep_a2"]},
{"claim": "cancelled Monday review", "episodes": ["ep_a3"]}
],
"covers_window": {"from": "2026-03-02", "to": "2026-03-08"},
"owner_scope": "user:8831"
}// A REFLECTION: a generalization beyond the evidence; gated like a candidate fact.
{
"memory_id": "ref_01HX...",
"kind": "reflection",
"subject": "user:8831",
"claim": "User tends to avoid Monday meetings",
"derived_from": ["sum_01HX...", "ep_a1", "ep_a3"],
"inference_type": "generalization", // NOT entailed by sources; it's a guess
"confidence": 0.45, // low: 3 episodes, one week, alt. explanations
"alternative_explanations": [
"one-off scheduling conflict that week",
"unrelated reasons per meeting"
],
"confirmed_by_user": false,
"yields_to_live_intent": true,
"owner_scope": "user:8831"
}The reflection schema carries two fields the summary does not, and they are the antidote to overgeneralization. inference_type: generalization marks the claim as not entailed by its sources, a flag that recall and the write gate read to apply the higher bar. And alternative_explanations forces the consolidation step to enumerate the other readings of the same evidence, which both lowers confidence honestly and gives a reviewer (or the user) the context to reject the reflection. A reflection that cannot name an alternative explanation for its evidence is almost always overconfident, because real evidence rarely supports only one generalization.
The consolidation pipeline
Consolidation runs in _post_task (Chapter 3) and on a slower periodic schedule, never in the hot loop. The pipeline has distinct stages, and separating them keeps faithful compression away from risky inference.
def consolidate(subject: str, ctx: MemoryContext, now: datetime):
# 1. Gather raw episodes not yet summarized, within a window.
episodes = ctx.episodic.unsummarized(subject, window=last_7_days(now))
if len(episodes) < MIN_EPISODES_TO_SUMMARIZE:
return # nothing worth compressing yet
# 2. SUMMARIZE: faithful compression. Every claim must map to episode IDs;
# a claim that cannot be grounded in a source episode is dropped.
summary = summarize_with_grounding(episodes)
summary = drop_ungrounded_claims(summary, episodes) # no free-floating assertions
ctx.summaries.write(summary) # low bar: adds no new claims
# 3. REFLECT: propose generalizations - but as CANDIDATES, not memories.
reflections = propose_reflections(summary, episodes) # may be empty; that's fine
# 4. GATE each reflection at the higher bar for invented claims.
for r in reflections:
r.confidence = reflection_confidence(r, episodes) # corroboration-weighted
decision = write_gate(r.as_candidate(), ctx, subject_user(subject))
# Reflections about preferences/dispositions are routed to confirmation
# far more aggressively than user-stated facts.
if r.is_disposition() and not decision.committed:
ctx.confirmation_queue.add(r) # ask before acting on a guessThree design choices in that pipeline carry the chapter's argument. drop_ungrounded_claims enforces that summaries stay at Level 1, if the summarizer slips a generalization into the summary text ("the user seems frustrated lately"), it is dropped, because a summary may only assert what its episodes assert. propose_reflections is allowed to return nothing, most weeks, an agent should reflect into no new durable beliefs about a person, because most weeks contain no robust pattern, and a pipeline that always produces reflections is a pipeline manufacturing patterns from noise. And reflections run through the same write gate as any candidate, plus an aggressive confirmation route for dispositions, because a guessed disposition is the highest-risk memory the system produces.
A bad summary, dissected
Concreteness helps. Here is a summary that creates a false preference, and exactly where it goes wrong.
The agent, a coding assistant, observes three episodes over a week: in episode one, the user reverted an auto-formatting change; in episode two, the user asked the agent not to reformat a file it was editing; in episode three, the user manually fixed indentation the agent had changed. A reflection step writes: "User prefers no automatic formatting; disable auto-format for this user." The agent dutifully stops formatting anything.
Now the lie. The three episodes are real and consistent with the reflection. But the correct generalization was narrower: the user objected to the agent reformatting files it was only partially editing and unrelated code, not to formatting in general, they are perfectly happy with auto-format on code the agent writes from scratch. The reflection over-generalized from "objected to formatting in these three specific contexts" to "prefers no formatting, " and the agent now under-serves the user, producing unformatted new code the user then has to format by hand. The user is mildly annoyed but never connects it to a "memory", they just think the agent got worse. The summary was confident, sourced, and wrong in scope, and it degraded the agent silently.
The defenses, in order: the reflection's alternative_explanations should have included "objects to reformatting unrelated/partial code, not all formatting, " which would have lowered its confidence below the threshold to act. The disposition route should have triggered a confirmation ("Want me to stop auto-formatting entirely, or just files you're mid-edit on?"). And the negative-memory framing from Chapter 5 fits better than a broad preference: three specific "do not reformat this" memories are more truthful than one sweeping "prefers no formatting, " because they assert only what the evidence supports. Over-generalization is the failure; specificity is the cure.
Summary invalidation: the cracked card
Summaries and reflections inherit a problem that raw episodes do not have: they can be invalidated by changes to their sources. Suppose the user corrects an underlying fact: "actually, I cancelled that Monday review because the room was double-booked, not because of the day." That correction changes an episode (or adds a correcting one), and any summary or reflection derived from it is now potentially stale. A consolidation system that writes summaries and never revisits them accumulates derived memories built on corrected foundations, the cracked card, still in the archive, still being recalled, resting on a fact that no longer holds.
So derived memory needs invalidation, and provenance is what makes it possible. When an episode is corrected, superseded, or deleted, the system finds every summary and reflection that lists it in source_episode_ids and marks them for re-derivation, not silent deletion (which would lose useful compression) but a flag that says "your sources changed; re-summarize and re-reflect."
def on_episode_changed(episode_id: str, ctx: MemoryContext):
# Find every derived memory resting on this episode.
affected = ctx.find_derived_from(episode_id) # summaries + reflections
for d in affected:
ctx.mark_for_rederivation(d.memory_id, reason=f"source {episode_id} changed")
# Until re-derived, lower its recall confidence so it can't strongly
# drive behavior on a foundation we know shifted.
ctx.dampen_confidence(d.memory_id, factor=0.5)
# Re-run consolidation for the affected subjects on the next cycle.
ctx.enqueue_rederivation(subjects={d.subject for d in affected})-- The query behind find_derived_from: which derived memories cite this episode?
SELECT d.memory_id, d.kind, d.subject
FROM derived_memory d
JOIN derived_provenance p ON p.memory_id = d.memory_id
WHERE p.source_episode_id =:changed_episode_id
AND d.revoked_at IS NULL;The dampen_confidence step matters: between the moment a source changes and the moment re-derivation runs, the derived memory is suspect, and it should not drive behavior at full strength while suspect. Halving its recall confidence keeps it available (it may still be mostly right) while ensuring it cannot dominate an action on a foundation the system knows has shifted (see MemoryBank for the Ebbinghaus-inspired decay model that motivates continuous confidence adjustment as evidence ages or shifts). This is the consolidation analogue of supersession: derived memory is never trusted as immutable; it is always one source-correction away from re-derivation.
Re-summarization after corrections
A subtlety the invalidation logic exposes: when you re-derive, you must re-derive from the corrected evidence, not from the old summary. It is tempting to "patch" a summary in place, edit the one claim that changed, but patching loses the chance to re-evaluate the reflections, which may have rested on the now-corrected claim. The Monday-review correction does not just change one line of the summary; it removes a data point from the reflection "avoids Monday meetings, " which now rests on two episodes instead of three and should drop in confidence accordingly, perhaps below the threshold to exist at all. Re-derivation is therefore bottom-up: re-summarize from corrected episodes, then re-reflect from the corrected summary, re-running the higher-bar gate. A reflection that no longer clears the bar is revoked, not patched. This is more expensive than patching, which is why it runs on a cycle rather than synchronously, but it is the only way to keep Level 2 honest as Level 0 changes.
Separating user-authored facts from model-inferred reflections
A final discipline that pays off everywhere downstream: keep a hard, queryable distinction between what the user said and what the agent inferred. A user-authored fact ("I'm vegetarian") and a model-inferred reflection ("seems health-conscious") are both durable memories, but they have radically different trust levels, and conflating them is how an agent ends up confidently asserting its own guesses as the user's stated facts. Store the distinction as a first-class field: authored_by: user | agent, and let recall, explanation, and governance treat them differently. When the agent explains an action, "you told me you're vegetarian" is a defensible citation; "I inferred you seem health-conscious" is an admission of a guess, and the user deserves to know which one drove the agent's behavior. The reflection mechanism is what lets an agent learn; the user/agent authorship distinction is what keeps it honest about what it actually knows versus what it merely suspects.
What this chapter sets up
Reflection is the engine of weight-free improvement, and it is the engine of manufactured false beliefs, and it is the same engine. We have tried to keep it honest: summaries faithfully compress and assert nothing new; reflections are flagged as inference, gated at a higher bar, forced to enumerate alternatives, and biased toward confirmation; derived memory is invalidated and re-derived bottom-up when its sources change; and authorship is tracked so the agent never confuses its guesses with the user's facts.
This same engine, pointed at actions instead of facts about people, becomes something even more valuable: an agent that learns how to do things and stores those skills for reuse. That is procedural memory, and it is powerful enough, and dangerous enough, to deserve its own chapter.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.