Operating Memory in Production
> **Working claim:** A memory system that passes evaluation can still fail in production, because production adds the things evals cannot: real drift, real scale, real cost, schema evolution under live data, and the incident you did not anticipate.

Key Takeaways
- Operating Memory in Production is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: A memory system that passes evaluation can still fail in production, because production adds the things evals cannot: real drift, real scale, real cost, schema evolution under live data, and the incident you did not anticipate. Operating memory means instrumenting every write and recall so you can see harm before users report it, evolving the schema without corrupting the memories already in it, controlling the cost and latency that memory silently adds to every agent action, and having a runbook ready for the day the agent acts on a memory it should never have kept.
The gap between evaluation and production
Evaluation runs on scenarios you designed against a ground truth you labeled. Production runs on traffic you did not design, users who behave in ways you did not anticipate, a world that changes under your stored facts, and a scale that turns rare failures into daily ones. A memory system that scored well in Chapter 13's evals can still degrade in production for reasons the evals could not contain: the user population shifts and your sarcasm-detection assumptions break for a new locale; the agent's tool set changes and skills silently drift; the store grows until recall latency balloons; a schema migration corrupts a field that the recall ranker silently depends on. Operating memory is the discipline of catching these while they are degradations, not yet incidents.
The instrument that makes this possible is the one the architecture has been building toward since Chapter 2: an audit log of every write, recall, correction, revocation, and deletion. In evaluation that log was for verification. In production it is for observability: the difference between knowing your memory system is healthy and assuming it.
Monitoring: what every write and recall emits
Memory operations should emit structured events the way any production system emits telemetry. The events are not the audit log (which is the immutable record); they are the observable stream you build dashboards and alerts on, derived from the same operations.
// Emitted on every durable write attempt (committed, rejected, or routed).
{
"event": "memory.write",
"ts": "2026-03-09T14:22:11Z",
"outcome": "committed | rejected | routed_to_confirmation | quarantined",
"category": "preference",
"owner_scope": "user:8831",
"origin_trust": "trusted | untrusted_external",
"calibrated_confidence": 0.41,
"gate_reason": "non-literal evidence; routed to confirmation",
"observation_count": 1,
"independent_sources": 1
}// Emitted on every recall that drove an action.
{
"event": "memory.recall",
"ts": "2026-03-09T14:25:03Z",
"task_type": "scheduling",
"owner_scope": "user:8831",
"memories_considered": 14,
"memories_injected": 3,
"max_effective_confidence": 0.88,
"stale_candidates_suppressed": 2, // expired/superseded filtered out
"overrode_live_intent": false, // must be rare; spike = harm
"latency_ms": 47
}From these two event types you build the dashboard that tells you whether memory is healthy right now:
- Write outcome mix. A healthy system rejects and routes-to-confirmation a meaningful fraction of candidates. If
committedis 99% of writes, your gate is not gating, it is rubber-stamping, and you are accumulating the noise Chapter 4 warned about. A sudden shift towardcommittedafter a deploy is a regression in the gate. - Untrusted-origin write rate. A spike in
origin_trust: untrusted_externalcandidates is the poisoning probe signal from Chapter 12 (see OWASP LLM Top 10 for the broader sensitive-information disclosure risk class this signal detects). - Override-live-intent rate.
overrode_live_intent: trueshould be near zero (Chapter 5). A spike means recall is fighting users, the most direct trust-destroying signal you have. - Recall precision proxy.
memories_injected / memories_consideredand the suppression counts tell you whether scope and decay filters are doing their job. - Confidence drift. Track the distribution of
calibrated_confidenceover time; a drift means either your population changed or your calibration (Chapter 13) has gone stale and needs refitting.
The monitoring schema
For teams that want the events in a queryable warehouse, here is the table behind the dashboard, and the alert queries that run against it.
CREATE TABLE memory_events (
event_id BIGSERIAL PRIMARY KEY,
ts TIMESTAMPTZ NOT NULL DEFAULT now(),
event_type TEXT NOT NULL, -- write | recall | correct | revoke | delete
outcome TEXT,
category TEXT,
owner_scope TEXT,
origin_trust TEXT,
confidence REAL,
overrode_live_intent BOOLEAN,
latency_ms INTEGER,
detail JSONB
);
-- ALERT: recall is fighting users (override-live-intent rate spike).
SELECT date_trunc('hour', ts) AS hr,
count(*) FILTER (WHERE overrode_live_intent) AS overrides,
count(*) AS recalls,
round(100.0 * count(*) FILTER (WHERE overrode_live_intent)/count(*), 2) AS pct
FROM memory_events
WHERE event_type = 'recall' AND ts > now() - interval '24 hours'
GROUP BY 1 HAVING count(*) FILTER (WHERE overrode_live_intent) > 0
ORDER BY pct DESC;
-- ALERT: write gate stopped gating (commit rate too high after a deploy).
SELECT date_trunc('hour', ts) AS hr,
round(100.0 * count(*) FILTER (WHERE outcome = 'committed')/count(*), 2)
AS commit_pct
FROM memory_events
WHERE event_type = 'write' AND ts > now() - interval '48 hours'
GROUP BY 1 ORDER BY hr;The two alert queries encode the two production failures most likely to ship from a code change: a recall regression that makes the agent override users, and a write-gate regression that makes it persist everything. Both are invisible in offline evals if the regression is in the wiring rather than the logic, and both are caught immediately in production telemetry. The principle: monitor the gate's behavior, not just its existence, because a gate that is present but mis-wired looks fine in code review and disastrous in the event stream.
The cost and latency of memory
Memory is not free, and its bill is easy to miss because it is spread across every agent action rather than concentrated in one place. Chapter 3 named write amplification; production is where it shows up on the invoice. Three costs compound:
- Recall cost is paid on every action that recalls memory: the retrieval query, possibly an embedding of the task, possibly a reranking model call. Multiply by every step of every agentic task and it is significant.
- Write/extraction cost is paid per task (if you batched extraction as Chapter 3 advised) or, if you did not, per step, the difference between a manageable bill and a runaway one.
- Consolidation cost is the periodic reflection/summarization jobs (Chapter 6), which run a model over accumulated episodes and can be expensive at scale.
-- Memory's share of agent cost: recall + extraction + consolidation, per day.
SELECT date_trunc('day', ts) AS day,
sum(cost_usd) FILTER (WHERE event_type = 'recall') AS recall_cost,
sum(cost_usd) FILTER (WHERE event_type = 'write') AS extraction_cost,
sum(cost_usd) FILTER (WHERE event_type = 'consolidate') AS consolidation_cost,
sum(cost_usd) AS total_memory_cost
FROM memory_events
WHERE ts > now() - interval '30 days'
GROUP BY 1 ORDER BY day;The optimization levers follow the MemGPT discipline of treating context as scarce: recall few memories (Chapter 5's small budget is a cost lever as much as a quality one); batch extraction to task boundaries; run consolidation on a cadence proportional to value, not on every task; and cache recall results within a task so repeated recalls of the same memories in one loop do not re-pay the retrieval cost. A memory system that recalls twenty memories per step, extracts per step, and consolidates per task is not just lower-quality than one that recalls three, extracts per task, and consolidates weekly, it is many times more expensive, for worse results.
Schema evolution: migrating live memory
Memory schemas change as the system matures, a new field (the confirmed_by_user you wish you had added at launch), a new category, a changed decay model, a tightened sensitivity classification. Migrating a memory store is harder than migrating an ordinary database, for two reasons specific to memory. First, the data is interpretive: backfilling a new authored_by field across millions of existing memories requires deciding what old memories' authorship was, and getting it wrong mislabels guesses as user-stated facts. Second, the recall ranker depends on the schema: a migration that changes how confidence or effective_confidence is computed silently changes which memories recall, which can shift agent behavior the moment the migration lands, with no code change to point at.
The discipline is to treat schema migration as a behavior change, not just a data change (consistent with the NIST AI RMF Manage function's insistence on continuous risk assessment through deployment changes), and to shadow-test it (Chapter 13) before it touches recall:
def migrate_add_confirmed_field(ctx):
# 1. Add the field with a SAFE default that preserves current behavior.
# Old memories default to confirmed_by_user = FALSE (conservative).
ctx.add_column("semantic_memory", "confirmed_by_user", default=False)
# 2. Backfill interpretively, but conservatively: only mark confirmed where
# we have CLEAR evidence (e.g. provenance is a confirmation episode).
# When in doubt, leave it FALSE - never UPGRADE trust during a migration.
for m in ctx.iter_memories():
if ctx.has_confirmation_episode(m):
ctx.set(m, confirmed_by_user=True)
# 3. Shadow the new ranking (which uses the field) before promoting it.
# Compare recall behavior old-vs-new; promote only if no regression.
report = ctx.shadow_compare_recall(policy="confirmed_field_ranking")
assert report.no_behavior_regression(), reportThe rule embedded in step 2, when in doubt, do not upgrade trust during a migration, is the migration analogue of the write gate's conservatism. A migration that retroactively marks ambiguous old memories as user-confirmed is a migration that manufactures false high-trust memories at scale, silently, across your entire user base. Migrations of memory should only ever preserve or reduce the trust and influence of existing memories unless there is clear per-memory evidence to raise it.
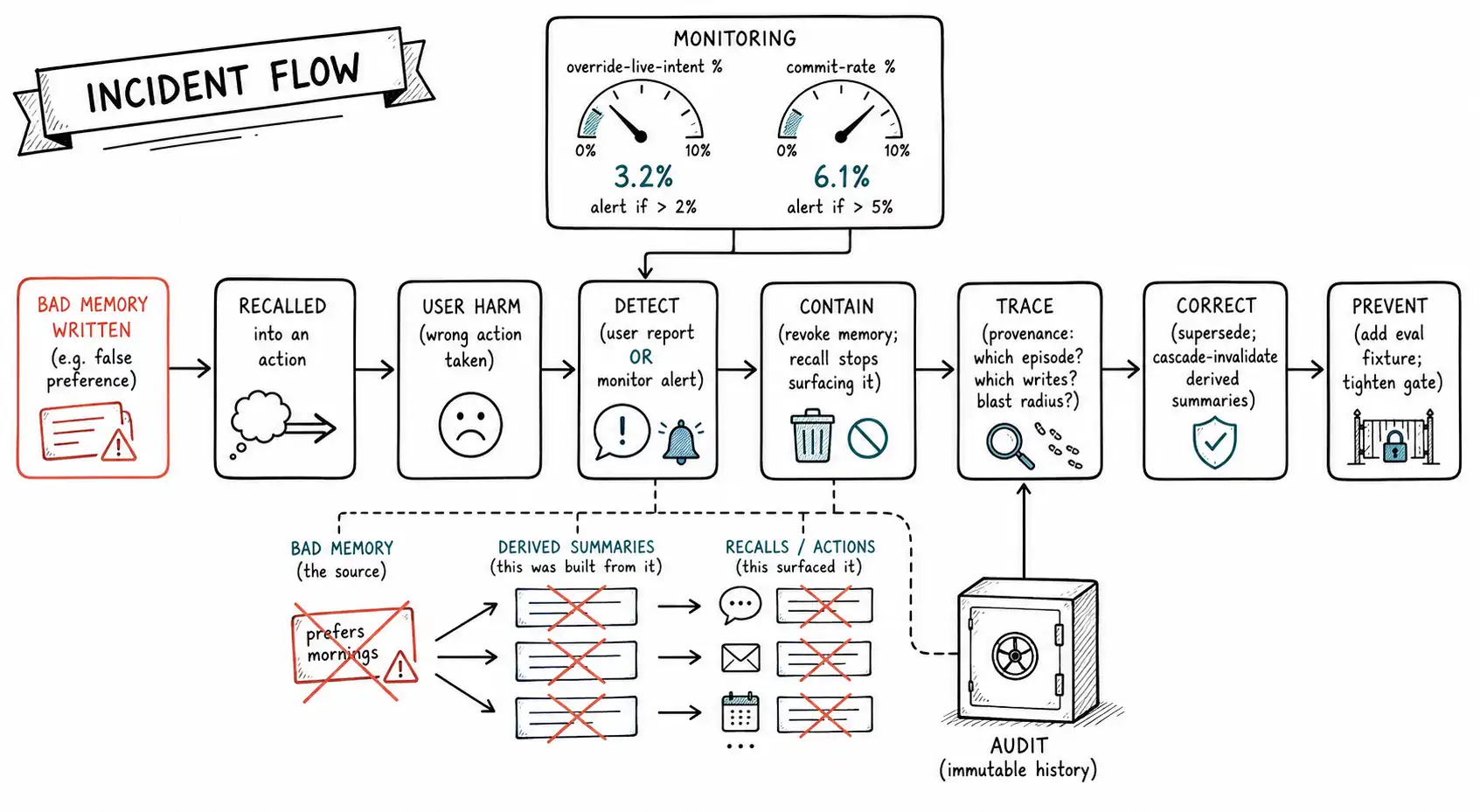
The incident runbook: the agent acted on a memory it should not have kept
Eventually it happens. The agent takes a wrong, harmful, or embarrassing action driven by a memory, a false preference, a stale fact, a poisoned write, a leaked cross-scope memory. This is the incident the whole book has been preparing for, and the architecture's provenance, audit, supersession, and cascade machinery is what makes it survivable. Here is the runbook.
-
Detect and confirm. The signal is a user report, a monitoring alert (override-live-intent spike, untrusted-write spike), or a support escalation. Confirm it is a memory-driven action by pulling the
memory. recallevent for the action and checking which memories were injected. -
Contain immediately. Revoke the offending memory (
revoked_atset, Chapter 10), so recall stops surfacing it now, before you fully understand it. Containment precedes understanding; stop the bleeding first. If the memory is in shared scope, containment also means demoting it across the scope so no other agent recalls it. -
Trace the provenance. Use the memory's
source_episode_ids(Chapter 4) to find where it came from, which episode, what evidence, whether the origin was trusted or untrusted, whether it was confirmed. This answers "how did this get written?" and tells you whether it is a one-off or a class of failures. A memory is a claim with a source, and the incident is where that source finally earns its existence. -
Measure the blast radius. Query for every recall of the bad memory (the recall log) and every derived memory built on it (the provenance join: Chapter 6). The bad memory may have driven many actions and seeded several summaries and reflections. The full blast radius is the bad memory plus everything it influenced.
-- Blast radius of a bad memory: every action it drove + every derivation it fed.
SELECT 'recall' AS kind, r.recalled_at AS ts, r.task_type AS context, r.owner_scope
FROM recall_log r WHERE r.memory_id =:bad_memory_id AND r.drove_action
UNION ALL
SELECT 'derived' AS kind, d.created_at, d.kind, d.subject
FROM derived_memory d
JOIN derived_provenance p ON p.memory_id = d.memory_id
WHERE p.source_memory_id =:bad_memory_id
ORDER BY ts;-
Correct and cascade. Supersede the bad memory with the correct one (if there is a correct version) or revoke it permanently (if it should never have existed). Cascade-invalidate every derived summary and reflection the blast-radius query found, and re-derive them from corrected evidence (Chapter 6). A correction that does not cascade leaves the poison in the derivations.
-
Reverse downstream harm where possible. For each action the bad memory drove, assess whether it can be reversed (the agent booked the wrong meetings, reschedule them; the agent sent the wrong email, follow up). This is the part the system cannot fully automate; it is incident response in the human sense.
-
Prevent recurrence. Add the incident as an eval fixture (Chapter 13) so the exact failure is regression-tested forever. If it was a poisoning attack, add a poisoning fixture (Chapter 12). If it was a gate gap, tighten the gate. The incident becomes a permanent test, which is the only way the same memory failure does not recur.
-
Record it. Write the incident, its provenance, blast radius, and resolution to the audit log and the post-incident record. The audit trail of the incident is itself a memory you must keep.
This runbook is the operational payoff of every conservative choice the book argued for. Provenance makes step 3 possible. The recall log and provenance joins make step 4 possible. Supersession and cascade make step 5 possible. The eval suite makes step 7 possible. A memory system built without these, the single-store, ungoverned blob from Chapter 2, cannot run this runbook at all: it cannot trace the memory's origin, cannot measure the blast radius, cannot cascade the correction, and cannot prevent recurrence. It can only delete the row it happened to find and hope there are no others. The whole architecture is, in the end, the difference between an incident you can run and an incident you can only apologize for.
Operating discipline: the weekly memory review
Beyond incident response, healthy memory operations include a proactive cadence, a weekly review of the memory dashboards the same way a team reviews error rates and latency (see Generative Agents for how the reflection and reranking loop that makes memory useful also requires ongoing calibration of the score weights it uses). The review asks a fixed set of questions: Is improvement-over-episodes still positive? Are the harm rates (false, stale, harmful-recall, creepy) trending the right way? Is the write outcome mix healthy, or is the gate drifting toward rubber-stamping? Is confidence still calibrated, or is it time to refit? Is recall cost growing faster than usage? Are there zombie tasks or drifting skills to retire? Are there poisoning probes in the audit log? This cadence catches the slow degradations that no single alert fires on, the gradual rise in stale recalls as a population's facts age, the slow drift of a skill, the creeping growth of recall cost, and it keeps the memory system in the state the evals certified, rather than letting it decay quietly until the next incident.
What this chapter sets up
Operating memory in production is where the architecture meets reality: structured telemetry on every write and recall, dashboards and alerts that catch the gate drifting and recall fighting users, cost discipline that respects memory's spread-out bill, schema evolution that treats migration as a behavior change and never upgrades trust by default, the incident runbook that the book's provenance and cascade machinery finally makes runnable, and a proactive review cadence that holds the line between incidents. This is the difference between a memory system that works in the demo and one that keeps working in the world.
The architecture is complete and operable. The final chapter turns it into practice: a set of use-case playbooks that apply the whole framework, what to remember, what not to, write policy, read policy, consent, evaluation, and failure risks, to the specific agents you are most likely to build.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.