Use Case Playbooks
This chapter turns use case playbooks into a concrete operating problem for the memory systems book.

Key Takeaways
- Use Case Playbooks is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: The architecture in this book is general, but every product applies it differently, because what is meaningful to remember, what is forbidden, and what failure costs vary enormously between a coding agent and a healthcare-adjacent assistant. A playbook is the architecture instantiated for a domain: what to remember, what never to, the write and read policies, the consent model, the evaluation focus, and the specific failures that will hurt you. Use these as starting points, not gospel, but do not start from zero, because the failures in each domain are predictable, and predictable failures deserve to be designed against in advance.
How to read a playbook
Each playbook below follows the same six lenses, applied with domain-specific judgment rather than as a rote template. Remember names the high-value memories worth the liability. Never remember names the categories that are forbidden or not worth the risk. Write policy sets the gate's posture for the domain. Read policy sets recall's posture. Consent sets the user-control model. Evaluate names the metric that matters most here. Top failure names the specific way this domain's memory goes wrong. The MEMORY framework (Meaningful, Evidenced, Mutable, Owned, Restricted, Yielding) is the lens behind every line; the playbooks just tune its weights for each domain's risk.
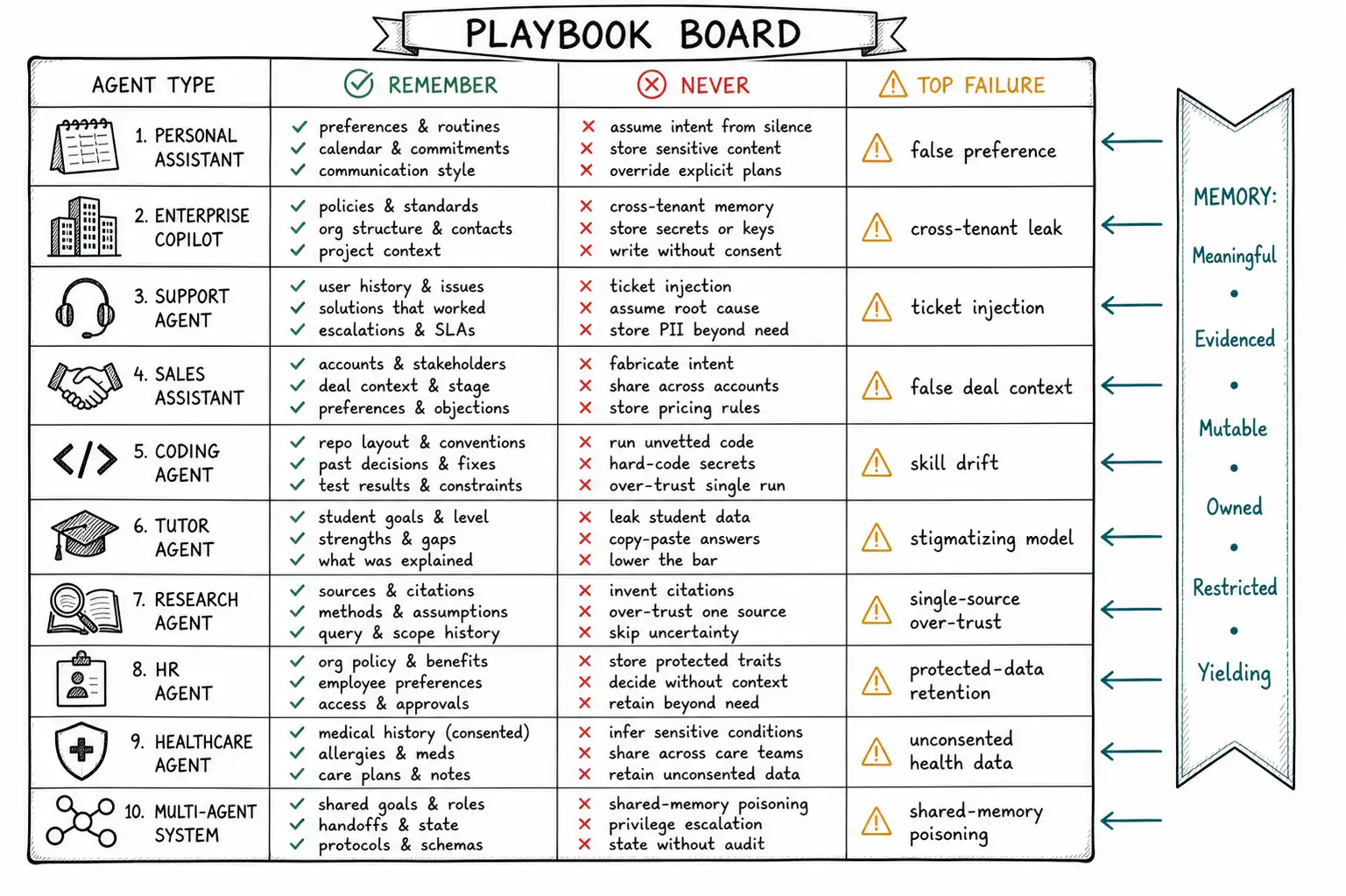
Personal assistant
The canonical case, and the one the 7 a. m. incident came from. A personal assistant serves one user across calendar, email, tasks, and life logistics, and its value is continuity, knowing the user without being told twice.
- Remember: stable preferences (communication style, default meeting times once confirmed), durable attributes (timezone, family members' names, recurring commitments), open personal tasks, past corrections.
- Never remember: sensitive health/financial/legal details without explicit consent (Chapter 11); one-off moods and circumstances; anything stated sarcastically without confirmation.
- Write policy: conservative on preferences, confirm before persisting (the direct fix for 7 a. m.); decay preferences on behavioral contradiction (Chapter 10).
- Read policy: the live instruction always beats the stored default; surface few memories; make memory visible in a control panel.
- Consent: opt-in memory with a visible, editable control panel; sensitive categories require explicit per-category consent.
- Evaluate: creepy-memory rate (from "why do you know that?" signals and delete-after-recall) and harmful-recall rate, trust is the product.
- Top failure: the false preference from an unconfirmed or non-literal utterance, acted on silently for weeks.
Enterprise copilot
An assistant inside a company's tools, docs, tickets, code, dashboards, serving employees within a tenant. The defining constraint is isolation and permission, because the data is the company's and the blast radius of a leak is organizational.
- Remember: the user's role and team, their recurring workflows, project context, workspace facts (deploy cadence, ownership maps), per-user tool preferences.
- Never remember: anything crossing a tenant boundary (Chapter 11); credentials or secrets (
never_store); data the user lacked permission to see in the first place, memory must not become a permission-laundering channel. - Write policy: enforce
owner_scoperigorously; a memory derived from a permission-scoped document inherits that scope; shared/workspace writes require write authority (Chapter 9). - Read policy: scope-before-score is non-negotiable; recall must respect the same permissions as the source documents, so memory never surfaces what the user could not have retrieved directly.
- Consent: governed by employer policy and the tenant's data agreements, not just individual opt-in; align with NIST AI RMF governance functions.
- Evaluate: tenant-isolation tests (adversarial, Chapter 11) gating every deploy; permission-respecting recall.
- Top failure: cross-tenant or cross-permission leakage, a breach, not a bug.
Customer support agent
An agent handling support conversations, often across many customers, often ingesting untrusted customer-provided content (tickets, emails, attachments). The defining constraint is poisoning resistance and per-customer scoping.
- Remember: the customer's account context, prior issues and resolutions, stated preferences (contact channel, language), product configuration relevant to support.
- Never remember: content from one customer's ticket as a fact about another; untrusted ticket text as durable instruction (Chapter 12); payment details.
- Write policy: ticket and email content is
untrusted_external, it becomes episodic evidence but never originates durable memory on its own (the cardinal rule of Chapter 12); authority claims in tickets ("I'm a premium customer with unlimited returns") route to verification, never auto-persist. - Read policy: strictly scoped to the current customer; negative memory ("do not offer this customer a refund, flagged for abuse") fires on triggers.
- Consent: per the support data policy; retention limited (resolved issues age out).
- Evaluate: poisoning fixtures (Chapter 12); per-customer scope isolation; stale-resolution rate (recalling a fix that no longer applies after a product change).
- Top failure: indirect injection via a malicious ticket that plants a false durable fact (an unauthorized entitlement) applied to future interactions (see OWASP LLM Top 10 for the indirect prompt injection risk class this failure belongs to).
Sales assistant
An agent supporting sales, tracking prospects, deals, interactions, and preferences across a long sales cycle. The defining constraint is long-horizon accuracy and not inventing the customer.
- Remember: deal stage and history, stakeholder map and roles, stated needs and objections, commitments made, next steps (this is long-horizon task memory, Chapter 8).
- Never remember: inferred personal traits about prospects that you would not say to their face (a creepy-memory and a legal risk); unverified competitive intelligence as fact.
- Write policy: distinguish the prospect said from the rep inferred (authorship, Chapter 6); commitments and next steps are high-value task memory with decisions logged.
- Read policy: surface deal context and prior commitments before any prospect-facing action; recall the decision log so the agent does not contradict prior promises.
- Consent: governed by CRM data policy and applicable privacy law for prospect data.
- Evaluate: task-memory accuracy (does it correctly track deal state across months?); false-memory rate on stakeholder facts.
- Top failure: a stale or invented fact about a prospect ("they said budget is approved") that the rep acts on and that was never true, a deal-losing and trust-losing error.
Coding agent
An agent that writes, debugs, and maintains code across repositories and sessions. This is procedural memory's heartland (Chapter 7) and the domain where bad memory most directly executes.
- Remember: per-repo skills (how to build, test, deploy, the Voyager-style skill library), project conventions and style, recurring fixes, architectural decisions (Chapter 8 decision log), the user's coding preferences scoped correctly (the formatting lesson from Chapter 6).
- Never remember: secrets, tokens, or credentials encountered in code (
never_store); a one-off success as a trusted skill (require theproposed → stablepromotion). - Write policy: skills must pass tests before trust and be parameterized, not hard-coded to transient state (Chapter 7); preferences must be specific ("don't reformat partial edits") not over-generalized ("never format").
- Read policy: match skills on precondition/applicability, not fuzzy similarity; prefer first-principles fallback over a drifting skill.
- Consent: per-repo and per-org; shared skills in a team library require human approval.
- Evaluate: improvement-over-episodes (Reflexion-style: does it repeat fewer mistakes, solve recurring tasks in fewer steps?); skill drift detection.
- Top failure: skill drift, a skill that worked yesterday silently does the wrong thing today after the environment changed, and over-generalized preferences that quietly degrade output.
Tutoring agent
An agent teaching a learner over many sessions. The defining constraint is a long-horizon model of the learner that must be accurate, encouraging, and never stigmatizing.
- Remember: mastered concepts, persistent misconceptions, learning pace and style preferences, past struggles framed constructively, curriculum progress (long-horizon task memory).
- Never remember: stigmatizing characterizations ("struggles with math, " "lazy"), a creepy and harmful memory even if statistically supported; sensitive personal circumstances disclosed in passing.
- Write policy: record evidence-based mastery (got these problems right) rather than trait inferences (is good/bad at this); reflections about the learner gated at the higher bar (Chapter 6) and biased toward constructive framing.
- Read policy: recall the learner's prior struggles to adapt teaching, not to limit expectations; surface mastered concepts to build on them.
- Consent: for minors, parental/guardian consent and strict data minimisation; clear visibility for learner and guardian.
- Evaluate: improvement-over-episodes (does the learner actually progress?); absence of stigmatizing memories.
- Top failure: a fixed, stigmatizing model of the learner that the agent acts on, limiting the learner rather than adapting to them.
Research agent
An agent conducting multi-step research across documents, the web, and tools. The defining constraint is source trust and not laundering unverified claims into facts.
- Remember: verified findings with provenance, the research plan and progress (long-horizon task), source quality assessments, dead ends (negative memory: "this source is unreliable").
- Never remember: content from an untrusted webpage as a durable fact without corroboration (Chapter 12); a single source's claim promoted to verified truth.
- Write policy: every finding carries its source and trust class; web/document content is
untrusted_externaland requires independent corroboration to become a durable fact; the independent-source check (Chapter 12) defeats a single source repeating itself. - Read policy: recall findings with their provenance so the agent can weigh them; surface conflicting findings rather than silently picking one.
- Consent: lower personal-data stakes, but source-attribution and IP considerations apply.
- Evaluate: false-memory rate on findings; corroboration discipline (are durable findings actually multi-sourced?).
- Top failure: indirect injection or single-source over-trust, a poisoned or unreliable source's claim consolidated into a confident "finding" the agent then builds on.
HR assistant
An agent supporting HR processes, policy questions, onboarding, employee queries. The defining constraint is high-sensitivity data and strict access control.
- Remember: an employee's role and team, their stated process preferences, the status of open HR tasks (onboarding steps, requests), general (non-sensitive) policy context.
- Never remember: protected-category information (health, disability, complaints, compensation specifics) without explicit lawful basis and strict scoping; one employee's data accessible to another.
- Write policy: sensitive HR categories are
explicit_consent_onlyornever_store(Chapter 11); most HR-sensitive content stays out of durable memory entirely. - Read policy: strictly scoped; recall respects the HR access model; sensitive memories never surface in non-HR contexts.
- Consent: explicit, documented, aligned with employment and privacy law; full visibility and erasure support.
- Evaluate: sensitive-category leakage tests; access-control isolation; deletion correctness (erasure must be complete and verified).
- Top failure: retention or disclosure of protected-category data, a legal and ethical breach with severe consequences.
Healthcare-adjacent assistant
An assistant that touches health information without being a regulated medical device, wellness, scheduling, symptom triage handoff. The defining constraint is maximum caution: assume the strictest applicable regime.
- Remember: only what is necessary and consented, appointment logistics, stated communication preferences, explicitly consented relevant health context with short retention.
- Never remember: diagnoses or health details by inference; anything that would constitute a medical record without the controls a medical record demands; sensitive data beyond its consented purpose or retention.
- Write policy: health is
explicit_consent_onlywith short retention and no auto-extraction (Chapter 11); default is do not persist health content at all; every health memory is logged and reviewable. - Read policy: the narrowest possible scope; never surface health memory in a context the user did not anticipate (creepy memory here is also a harm).
- Consent: explicit, specific, time-bounded, revocable; assume applicable health-privacy regimes apply.
- Evaluate: sensitive-data handling audits; consent-coverage (every health memory traces to a consent); deletion completeness.
- Top failure: storing inferred or unconsented health information, or retaining it beyond purpose, a severe privacy and trust violation, potentially a regulatory one.
Multi-agent workspace
A workspace where several agents (and humans) collaborate over shared memory, the synthesis of Chapter 9. The defining constraint is shared-state governance: scoping, write authority, trust-weighting, and conflict resolution across actors.
- Remember: shared workspace facts (conventions, ownership, schedules), task state shared among collaborating agents, approved shared skills, per-agent and per-user private memory kept private.
- Never remember: one user's private data promoted to shared scope without consent (the private→shared leak, Chapter 9); unauthorized team facts; sub-agents' raw scratchpads in shared scope.
- Write policy: scope coherence (no private→shared laundering); write authority for workspace facts; trust-weighting so low-trust writes cannot dominate; shared skills require human approval.
- Read policy: scope lattice strictly enforced; conflicts resolved by evidence recency, source trust, and world-verification for verifiable facts, never last-write-wins.
- Consent: layered, individual consent for personal data, workspace policy for shared data, tenant policy for isolation.
- Evaluate: scope-isolation tests; conflict-resolution correctness; poisoning resistance for shared memory (an unauthorized member cannot establish a workspace policy).
- Top failure: shared-memory poisoning (one bad write becomes the fleet's belief) or private→shared leakage (one member's personal data exposed to the workspace).
The pattern across every playbook
Read down the playbooks and the same structure recurs under different domain risks, which is the point: the architecture is one thing, instantiated ten ways. Every domain has high-value memories worth their liability and forbidden categories that are not. Every domain's write policy is some tuning of the same gate, more conservative where the data is sensitive (healthcare, HR), more skill-focused where the agent acts (coding), more poisoning-resistant where input is untrusted (support, research). Every domain's read policy is the same scope-before-score, live-intent-wins, surface-few discipline, tightened where isolation matters most. Every domain's top failure is a specific instance of the five from Chapter 1, false, stale, creepy, unauthorized, poisoned, with the domain deciding which one hurts most.
That recurrence is the book's final argument. You do not build a different memory system for each agent. You build one governed write-and-recall system, types, gate, recall, reflection, skills, tasks, sharing, forgetting, governance, security, evaluation, operations, and you tune its posture to the domain's risk (see MemGPT for the foundational architecture that treats the full memory lifecycle as a single managed system rather than a collection of ad-hoc stores). The MEMORY framework is the tuning interface: Meaningful and Yielding tune usefulness, Evidenced and Mutable tune correctness, Owned and Restricted tune safety. A coding agent leans on Evidenced and Mutable (skills must be tested and retirable); a healthcare assistant leans on Restricted and Owned (consent and scope dominate); a personal assistant leans on Yielding (the live request beats the stored default). Same six questions, different weights.
What this chapter: and the book: comes to
The playbooks close the loop the introduction opened. The 7 a. m. memory was a personal assistant's false preference, written from a non-literal utterance, recalled with confidence, overriding the user's real intent, with no provenance, no consent, no correction path, and no measure of its blast radius. Every chapter since has built a piece of the answer, and the personal-assistant playbook now states the fix in two lines: *confirm before persisting preferences; let the live instruction beat the stored default. * The whole architecture exists so that those two lines are enforceable, auditable, correctable, and testable, so that the failure cannot recur silently, and when a different failure comes, you can run the incident instead of apologizing for it.
The question you started with was "Can the agent remember?" The question you end with is the one the back cover promised: Should this become memory, who owns it, how will it be used, and how can it be forgotten? An agent that can answer those four questions about every durable claim it holds is an agent that remembers usefully, provably, and forgettably, because a memory is a claim with a source, not a vibe.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.