Long-Horizon Task Memory
> **Working claim:** Real agents do not finish in one session. They work on something for days, get interrupted, resume, hand off, and come back after the world has changed.

Key Takeaways
- Long-Horizon Task Memory is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: Real agents do not finish in one session. They work on something for days, get interrupted, resume, hand off, and come back after the world has changed. The memory that carries an objective across that span, open goals, completed subtasks, blocked dependencies, decisions and their rationale, is a distinct store with a distinct lifecycle, and most agent frameworks fail it by stuffing task state into the conversation history, where it decays, gets truncated, and cannot survive a restart.
The conversation-history trap
Watch how most agents handle a multi-day task and you see the same anti-pattern. The agent tracks the task in the conversation: the plan is a message it wrote at the start, the progress is scattered across subsequent messages, the decisions are buried in the back-and-forth, and the whole thing is reconstructed each session by replaying the transcript into the context window. It works for a short task in a single sitting. It fails the moment the task is long, and it fails in three specific ways.
First, truncation. A multi-day task accumulates more transcript than fits in the window. Something gets dropped, and what gets dropped is usually the early planning and the middle decisions, the structural memory of why the task is shaped the way it is, leaving the agent with recent chatter and no spine. The agent forgets its own plan.
Second, no restart survival. The conversation lives in a session. Kill the process, hit a rate limit, lose the connection, and the in-flight task state, what is done, what is blocked, what was decided, evaporates, because it was never anywhere durable. The agent resumes from the last persisted message, which is not the same as the last state.
Third, no structure to query. Task state buried in prose cannot be queried. You cannot ask "what subtasks are blocked across all active tasks?" or "show me every decision the agent made on this objective and why, " because the answers are scattered across a transcript that only a model can read, and only approximately. The task has no schema, so it has no observability.
The fix is the same move as Chapter 2: pull task state out of the undifferentiated history and into a first-class, schema'd, durable store with its own lifecycle (see ReAct for the foundational interleaving of reasoning and acting that makes explicit task state necessary). MemGPT's insight applies directly, the model's context is scarce working memory, and durable state must live outside it, paged in deliberately. Task state is exactly the kind of durable state that does not belong in the window; it belongs in a store the window reads from.
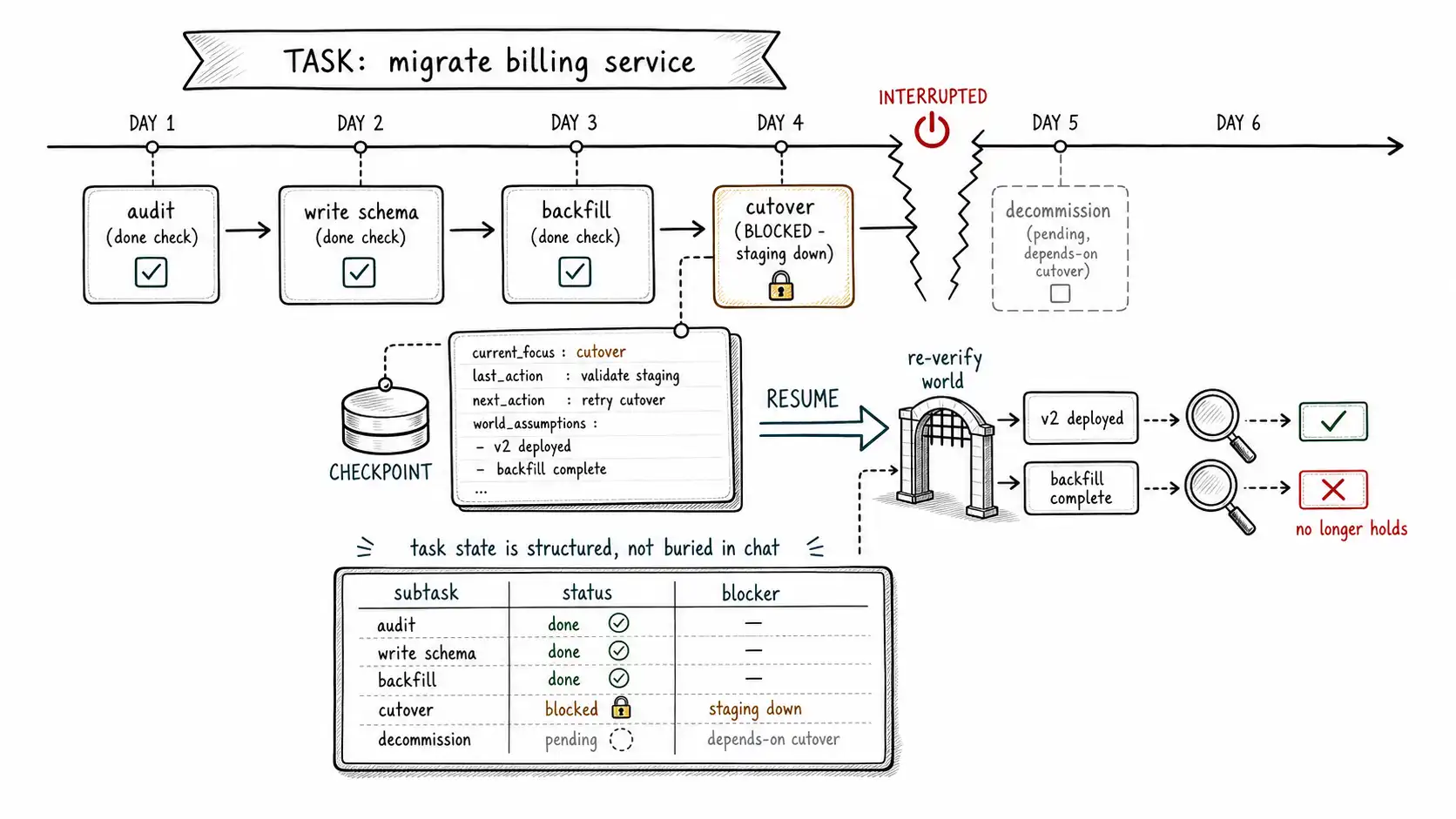
The task memory schema
A task is a small state machine with a memory. The schema captures the objective, its decomposition, its lifecycle status, the decisions made along the way with their rationale, and, crucially for resumption, enough to reconstruct where the agent was without replaying the entire transcript.
{
"task_id": "task_01HX...",
"owner_scope": "user:8831",
"objective": "Migrate the billing service from the legacy schema to v2",
"status": "in_progress", // pending|in_progress|blocked|done|abandoned
"created_at": "2026-02-01T09:00:00Z",
"updated_at": "2026-03-09T14:00:00Z",
"plan": [
{"id": "st1", "desc": "audit legacy schema usage", "status": "done"},
{"id": "st2", "desc": "write v2 schema + migration", "status": "done"},
{"id": "st3", "desc": "backfill historical data", "status": "done"},
{"id": "st4", "desc": "cut over write path", "status": "blocked",
"blocker": {"reason": "staging env unavailable",
"since": "2026-03-08T17:00:00Z",
"owner": "infra-team"}},
{"id": "st5", "desc": "decommission legacy endpoint", "status": "pending",
"depends_on": ["st4"]}
],
"decisions": [
{"id": "d1", "choice": "keep legacy endpoint live for one release",
"rationale": "downstream clients lag on adoption",
"made_at": "2026-02-10T11:00:00Z", "episode_id": "ep_d1"},
{"id": "d2", "choice": "backfill in batches of 50k, off-peak",
"rationale": "avoid prod load spike observed on first attempt",
"made_at": "2026-02-22T02:00:00Z", "episode_id": "ep_d2"}
],
"resume_context": { // the minimal state to pick up cleanly
"current_focus": "st4",
"last_action": "attempted cutover; staging returned 503",
"next_intended_action": "retry cutover once infra confirms staging is up",
"world_assumptions": ["v2 schema deployed to prod", "backfill complete"]
}
}Three parts of this schema do work the conversation history cannot. The plan is a structured, queryable decomposition with per-subtask status and explicit dependencies (depends_on), so the agent, and a human dashboard, can answer "what is blocking progress?" with a query, not a re-read. The decisions list with rationale and episode_id is the task's reasoning memory: it records not just what was decided but why, with a pointer to the episode where it happened, so a resuming agent does not re-litigate settled choices and a reviewing human can understand the task's shape. And resume_context is the checkpoint: the minimal state needed to pick up cleanly, which is the antidote to both truncation and restart-loss.
Checkpointing: surviving the interruption
The single most important operation in long-horizon task memory is the checkpoint, durably writing enough state that the agent can resume correctly after an interruption it did not anticipate. Chapter 3 introduced the working/durable split; here it becomes concrete. Working memory (the transient task scratchpad) is fast and dies with the process. The checkpoint is the periodic, durable snapshot of progress, not the transient hypotheses, but the settled facts: which subtasks are done, what was decided, where the agent is blocked, what it intends to do next.
def checkpoint(task: Task, working: WorkingMemory, ctx: MemoryContext):
"""Persist durable progress. Called after each meaningful state change,
NOT on every loop iteration (that would be write amplification)."""
task.plan = working.plan_with_statuses() # settled subtask statuses
task.decisions = working.decisions # decisions are durable
task.resume_context = ResumeContext(
current_focus=working.current_subtask,
last_action=working.last_action_summary,
next_intended_action=working.planned_next,
world_assumptions=working.assumptions_acted_on, # what the agent believes is true
)
task.updated_at = now()
ctx.task_memory.upsert(task) # durable, read-your-writes
# NOTE: transient hypotheses in `working` are deliberately NOT persisted.The checkpoint cadence is a tradeoff. Checkpoint on every loop iteration and you re-incur the write amplification problem from Chapter 3. Checkpoint too rarely and an interruption loses real progress. The right cadence is after each meaningful state change, a subtask completes, a decision is made, a blocker appears, because those are the events that, if lost, cost the agent real re-work. Routine reasoning steps that change no durable state do not warrant a checkpoint.
Note what the checkpoint deliberately excludes: the agent's transient hypotheses (see Reflexion for the complementary pattern of storing only externally-verified trial outcomes rather than in-flight reasoning). The debugging hypothesis "maybe it's a race condition" from Chapter 3 stays in working memory and dies with the process, because persisting it would resurrect a guess as durable task state on resume. The checkpoint persists what is settled, not what is being considered.
Resumption: picking up without re-deriving the world
A week later, or five minutes later, after a crash, the agent resumes. Resumption is not "replay the transcript." It is "load the checkpoint, re-verify the world, and continue from resume_context." The order matters, and the middle step is the one agents skip.
def resume(task_id: str, ctx: MemoryContext) -> WorkingMemory:
task = ctx.task_memory.load(task_id)
if task.status in ("done", "abandoned"):
raise TaskNotResumable(task.status)
working = WorkingMemory.from_task(task) # plan, decisions, focus
# CRITICAL: the world may have changed while we were away. Re-verify the
# assumptions the checkpoint recorded before acting on them.
for assumption in task.resume_context.world_assumptions:
if not ctx.verify_against_world(assumption): # re-fetch, don't trust cache
working.invalidate_assumption(assumption)
working.add_note(f"assumption no longer holds: {assumption}")
# Re-check the blocker: maybe it cleared while we were away.
for st in task.blocked_subtasks():
if ctx.is_blocker_cleared(st.blocker):
working.unblock(st.id)
return workingThe verify_against_world step is the difference between an agent that resumes intelligently and one that resumes dangerously. The checkpoint recorded that the agent believed "v2 schema deployed to prod" and "backfill complete." A week later, those may no longer be true, someone rolled back the schema, the backfill was reverted during an unrelated incident. An agent that resumes by trusting its week-old world_assumptions and proceeds to "decommission legacy endpoint" on the basis that "backfill complete" can cause real damage if the backfill was undone. This is environmental memory (Chapter 2) at its most dangerous: state about the world that went stale silently while the agent was not watching. The resumption protocol re-verifies before trusting, treating the checkpoint's world-assumptions as hints to re-check, not facts to act on.
The task lifecycle and the zombie-task problem
Task memory expires by status transition, not by clock (Chapter 2), and the dominant failure is the zombie task: a task that should be terminal but never got marked terminal, so it lingers, gets recalled as active, and the agent keeps trying to make progress on something already done or long abandoned.
Zombies come from missing transitions. A task completes but no done is written (the agent finished and moved on without closing the record). A task is implicitly abandoned, the user stopped caring three weeks ago, but nothing marked it abandoned, so the agent keeps surfacing "want to continue the migration?" long after it is irrelevant. The cure is to make terminal transitions explicit and detectable, and to sweep for staleness.
-- Find candidate zombie tasks: in-progress but untouched for a long time, or
-- blocked with a blocker that's gone stale. These need a human or a sweep.
SELECT task_id, owner_scope, objective, status, updated_at
FROM task_memory
WHERE status IN ('in_progress', 'blocked')
AND updated_at < now() - interval '21 days'
ORDER BY updated_at ASC;A periodic sweep over that query does not auto-delete, abandoning a real, still-wanted task is its own failure, but it flags stale tasks for resolution: ask the user ("are you still working on the billing migration?"), auto-abandon after a longer grace period with a notification, or escalate a stuck blocker. The principle mirrors the negative-memory and confirmation patterns: when in doubt about whether a task is still alive, ask, do not silently assume either way. A task wrongly kept alive nags; a task wrongly abandoned loses work. The sweep surfaces the ambiguity for a cheap human decision rather than guessing.
Decisions are memory too
A subtle but high-value part of task memory is the decision log, and it deserves its own emphasis because it is the part agents most need and most often lack. An agent on a long task makes consequential choices, "keep the legacy endpoint for one release, " "backfill in batches to avoid load spikes", and those choices have rationale that is expensive to rediscover and dangerous to contradict. An agent that does not remember why it chose batched backfilling may, on resume, helpfully "optimize" by switching to a single bulk backfill and reproduce the exact production load spike the original decision was made to avoid.
So decisions are first-class task memory, stored with rationale and provenance, and recall surfaces relevant past decisions whenever the agent is about to act in their domain. This is also a negative-memory pattern: a decision often encodes a constraint ("do not bulk-backfill, it spikes prod"), and recalling the decision is recalling the constraint. The decision log turns the agent's hard-won lessons within a task into durable guidance for the rest of that task, which is the within-task analogue of the skill library's across-task learning (see Generative Agents and Voyager for architectures where accumulated task experience drives durable capability improvement).
Handoff: task memory between agents and to humans
Long-horizon tasks frequently change hands, one agent hands off to another (Chapter 9), or the agent hands off to a human, or a human resumes a task an agent started. Task memory is what makes handoff possible, and the test of good task memory is whether a different actor can pick up the task from the record alone. This is a stronger requirement than self-resumption, because the new actor has none of the implicit context the original held in its head (or its working memory).
The resume_context, decisions, and structured plan are designed to pass this test. A human opening the task should see: the objective, what is done, what is blocked and why, what decisions were made and their rationale, and what the agent intended to do next. If they can pick up from that without interviewing the original agent or reading the transcript, the task memory is complete. If they have to reconstruct context from chat history, the task memory has failed and you are back in the conversation-history trap. Handoff readiness is a useful design lens: write task memory as if a stranger will resume it, because eventually one will, including the agent itself, a week later, which has forgotten everything not in the record.
What this chapter sets up
Long-horizon task memory is the store that lets an agent be useful on work that does not fit in a session: a structured plan with dependencies, a decision log with rationale, checkpoints that survive interruption, a resumption protocol that re-verifies the world before trusting stale assumptions, a lifecycle that expires by status with a sweep for zombies, and a handoff-ready record that a stranger could resume. It is the temporal backbone of an agent that works at the scale of real projects rather than single questions.
So far every memory type has belonged to one agent serving one owner. The moment you have multiple agents, an orchestrator and its sub-agents, a fleet of specialists, a workspace several agents share, memory becomes a concurrent, scoped, trust-laden problem, with new failure modes that single-agent memory never faces. That is the next chapter, and it is where memory stops being a private notebook and becomes shared infrastructure.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.