The 7 a. m. Memory
> **Working claim:** The seductive thing about agent memory is that it makes a stateless system feel like it knows you. The dangerous thing is the same thing.

Key Takeaways
- The 7 a. m. Memory is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: The seductive thing about agent memory is that it makes a stateless system feel like it knows you. The dangerous thing is the same thing. Every memory an agent keeps is a claim it will act on later, with confidence, on your behalf, so the first design question is never "can we remember this?" but "should this become a claim the agent acts on, and what happens when it is wrong?"
The incident, slowed down
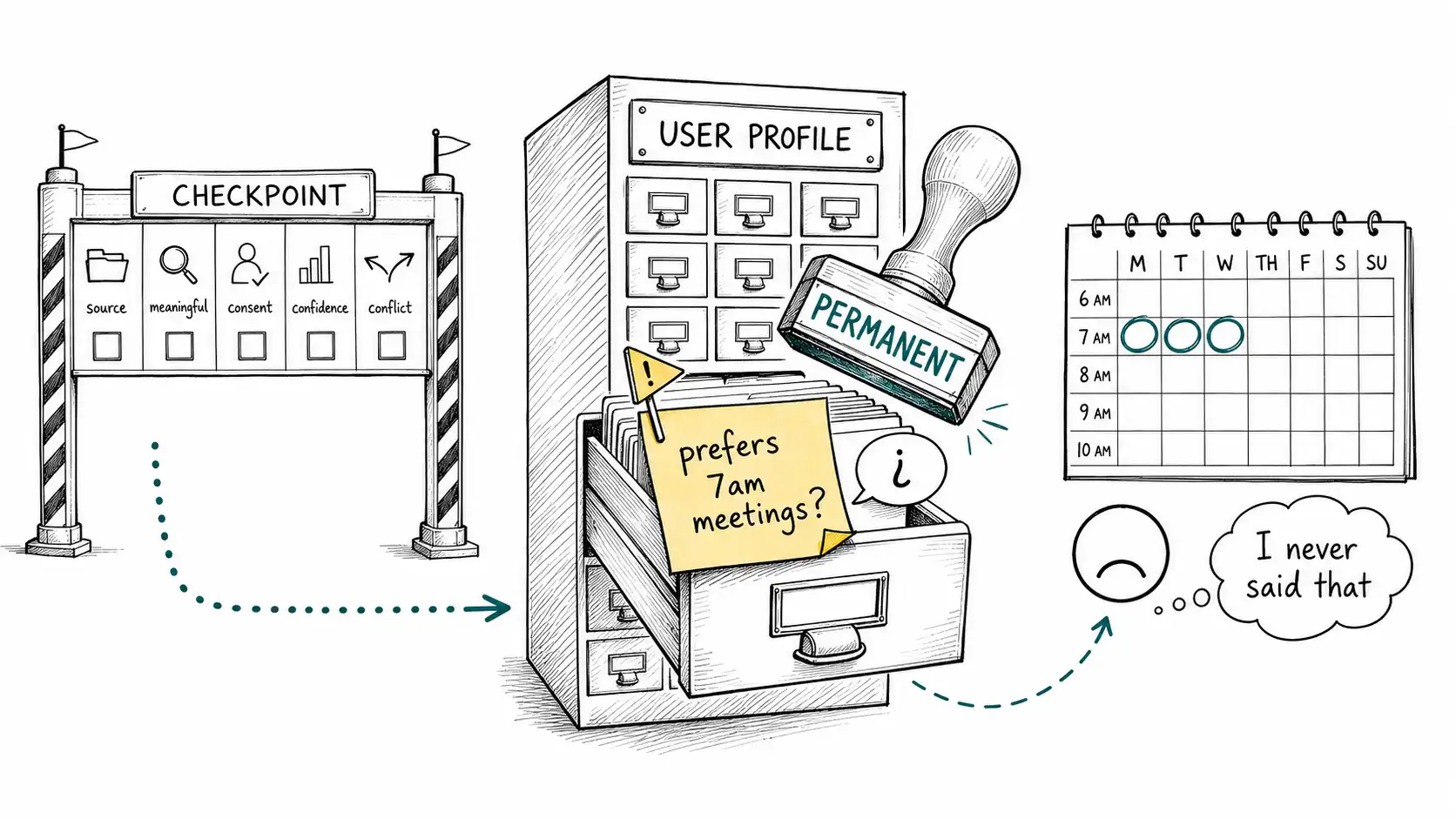
Return to the scheduling assistant from the introduction, but watch it in slow motion, because the speed is where the failure hides. The user said "Sure, because I love 7 a. m. meetings." Here is what the system did with that sentence, step by step.
First, the turn ended and an asynchronous extraction job woke up. Its prompt was reasonable: *Read this conversation and list durable facts about the user that would help in future sessions. Return them as structured claims with a confidence score. * The model read the transcript and returned, among other things:
{
"claim": "User prefers meetings scheduled in the early morning",
"category": "preference",
"confidence": 0.88,
"evidence": "Sure, because I love 7 a.m. meetings"
}Second, a write step took that object and inserted it into the memory store. There was a confidence threshold: 0.7, and 0.88 cleared it comfortably. There was no check for sarcasm, because there is no reliable check for sarcasm; there was no confirmation step, because confirmation felt like friction; there was no contradiction check against prior behavior, because the system did not look. The claim became a durable row.
Third, and this is the step that turns a bad write into a recurring harm, on every subsequent turn where the agent had a scheduling decision to make, a recall step queried the store for relevant memories, found prefers_meeting_time: early_morning with its tidy 0.88, and merged it into the prompt as established fact about the user. The model, doing exactly what it should, honored the user's stated preference. It booked mornings. It defended the choice when asked, citing the preference. The memory was not just stored; it was operationalized, turned into a standing input to every relevant decision.
The harm was not the storage. Storage is cheap and silent. The harm was that the system had no separation between the user said a thing and the user believes a thing the agent should act on, and the gap between those two is the entire discipline of memory engineering.
Why memory is seductive
It is worth being honest about why teams reach for memory, because the pull is real and not foolish. A stateless agent has a specific, grating failure: it has no continuity. Continuity is most of what makes an interaction feel like a relationship rather than a transaction.
Consider what continuity feels like to a user. They tell the agent once that they go by "Sam, " not "Samuel, " and forever after it is Sam, they never correct it again. They mention they are vegetarian while planning one dinner, and three weeks later when the agent suggests a restaurant it quietly filters the menu. They abandon a task on Friday and on Monday the agent says "want to pick up the migration plan where we left off?" without being reminded. Each of these is a small thing. Together they are the difference between a tool you operate and an assistant you trust. The research community noticed this early: MemoryBank framed long-term memory explicitly as the substrate for a companion-like agent that "remembers" the user over time, and Generative Agents made memory the mechanism by which simulated characters behaved consistently across days of simulated life. Continuity is the product.
But notice the asymmetry in those examples. The good cases are facts the user would recognize and endorse, their name, a dietary choice, an explicit task. The 7 a. m. case is a fact the user would reject if shown it. The seduction is that the same machinery produces both, and from the inside they look identical: a structured claim with a confidence score, written to a store, recalled when relevant. The system cannot tell "Sam" from "loves 7 a. m. meetings" by introspection. The difference is in the evidence and the consent, which is precisely what the naive pipeline throws away.
The vocabulary the failure exposes
The incident is useful because it forces distinctions that casual usage blurs."The agent remembers" is doing far too much work. Let us separate what actually got conflated.
There is a difference between conversation history, preferences, facts, tasks, and state, and treating them as one kind of thing is how the failure happened.
| Kind | What it is | Example from the incident | Why it must be governed differently |
|---|---|---|---|
| Conversation history | The raw transcript of what was said | "Sure, because I love 7 a. m. meetings" | High fidelity, low interpretation; it is evidence, not conclusion |
| Preference | A durable choice the agent should default to | "Prefers morning meetings" | Acted on repeatedly; must be confirmed, correctable, overridable |
| Fact | A durable attribute believed true | "Is in US/Pacific timezone" | Can be checked against the world; can go stale |
| Task | An open objective with state | "Booking the Q3 planning call" | Has a lifecycle; must expire when done or abandoned |
| State | Current, transient working context | "Right now we are picking a time" | Lives in the loop; must not be persisted as durable |
The scheduling system took a piece of conversation history, a sarcastic sentence, and promoted it directly to a preference, skipping every step that distinguishes the two. It treated evidence as conclusion. That promotion, performed automatically and silently, is the original sin, and most of this book is about installing the steps that should sit between "the user said something" and "the agent will now act on it forever."
A taxonomy of memory failure
Once you start looking, agent memory fails in a small number of recognizable ways. Naming them is the first defense, because each has a different cause and a different fix.
False memory is a stored claim that was never true. The 7 a. m. preference is the archetype: the extractor manufactured a belief the user does not hold. False memory comes from treating low-evidence utterances as high-evidence facts, and from reflections (Chapter 6) that overgeneralize from thin episodes (see Reflexion for the complementary approach: using externally-verified trial outcomes rather than unverified extraction to produce durable agent memory).
Stale memory is a stored claim that was true and no longer is. The user moved from Pacific to Eastern time. The project they "are working on" shipped two months ago. The colleague they talk to most quit. Stale memory comes from storing facts with no expiry and no re-confirmation, and it is insidious because the memory was correct when written, your provenance trail looks clean.
Creepy memory is a stored claim that is true, in scope, and current, and that the user is unsettled to learn the agent kept. They mentioned a health condition once, in passing, while asking the agent to reschedule something; months later the agent references it unprompted. Nothing is technically wrong. The trust damage is real anyway. Creepy memory comes from storing more than the user expects and surfacing it in contexts they did not anticipate.
Unauthorized memory is a stored claim the system was not permitted to keep, a sensitive category under policy, data the user explicitly asked not to be remembered, or information that crossed a tenant or workspace boundary it should not have crossed. This is not a quality problem; it is a compliance and security problem, and it is covered in depth in Chapters 11 and 12.
Poisoned memory is a stored claim an adversary planted. A malicious document the research agent ingested contains text engineered to be extracted as a durable instruction. A user in a shared workspace writes a "team fact" that is false but self-serving. Tool results carry injected content that the agent persists. Poisoning is memory's worst case because it is adversarial, someone is trying, and it is covered in Chapter 12 (see OWASP LLM Top 10 for the prompt injection and indirect injection risk classes that describe how this attack surface works).
These are not exotic. In a memory system without gates, you will produce all five, and you will not know it, because the system has no instrument that distinguishes a helpful memory from a harmful one. That instrument is what we are going to build.
The user trust matrix
The five failures map onto a simple matrix that I find more useful than any single metric, because it forces the team to look at memory through the user's eyes rather than the system's. Score every memory the agent uses on two axes: was it correct, and was it welcome.
| Welcome (user endorses the agent knowing it) | Unwelcome (user is unsettled the agent knows it) | |
|---|---|---|
| Correct (the claim is true) | Helpful, the goal."It remembered I'm vegetarian." | Creepy, true but over-reaching."Why does it know that?" |
| Wrong (the claim is false/stale) | Annoying, false but harmless-feeling."No, I moved cities." | Unsafe, false and over-reaching. Acts wrongly on sensitive ground. |
Most memory engineering is about moving population from the bottom-right toward the top-left without simply storing less and becoming useless. Note that two of the four quadrants are not about correctness at all. A memory system optimized only for accuracy, only for the correct/wrong axis, will still produce creepy memories, because creepiness lives on the welcome axis, and the welcome axis is about consent, scope, and expectation, not truth. This is why memory cannot be solved as a pure ML problem. It is a product and governance problem with an ML component.
A write that should have been rejected
Here is the write the system performed, and here is the write a governed system performs instead. The difference is not the model; it is the gate around the model.
# What the naive system did: extractor confidence clears a threshold, write.
def naive_write(candidate):
if candidate.confidence >= 0.7:
memory_store.insert(candidate) # one line, and the harm is done
# What a governed system does: the candidate must earn persistence.
def governed_write(candidate, user, prior_memories):
decision = WriteDecision(candidate)
# M - Meaningful: is a one-off utterance worth a durable claim?
if candidate.observation_count < 2 and candidate.category == "preference":
decision.reject("single-observation preference; await confirmation")
return queue_for_confirmation(candidate) # ask, do not assume
# E - Evidenced: provenance is mandatory, and the evidence must support
# the *strength* of the claim, not just mention the topic.
if not candidate.source_event_id:
decision.reject("no provenance")
return decision
if looks_non_literal(candidate.evidence_span): # sarcasm, hypothetical, quoted
decision.flag("evidence may be non-literal; lower confidence, confirm")
# O / R - Owned & Restricted: sensitive categories never auto-persist.
if candidate.category in SENSITIVE_CATEGORIES:
return route_to_consent_flow(candidate, user)
# Contradiction check before write (Mutable depends on knowing the prior).
conflict = find_contradiction(candidate, prior_memories)
if conflict:
return resolve_conflict(candidate, conflict) # never silently overwrite
return commit(candidate, ttl=default_ttl_for(candidate.category))The naive version is one line because the team thought the hard part was extraction. The governed version is longer because the hard part is the decision about persistence, and that decision is exactly where the 7 a. m. memory would have been caught: a single-observation preference, from evidence that looks_non_literal flags as possibly sarcastic, would have been routed to a lightweight confirmation ("Want me to default your meetings to mornings?") instead of silently committed. The user would have said no. There would have been no incident.
Notice the framework hiding in the comments, Meaningful, Evidenced, Owned, Restricted, Mutable. That is the MEMORY framework from the front matter, and you will see it threaded through the book as a checklist for any candidate write, never as a rote chapter template.
Why remembering less can be better
The instinct of a team that has just been burned is to add more checks: better sarcasm detection, higher thresholds, more sophisticated extraction. Sometimes that helps. But the deeper lesson is counterintuitive and worth stating plainly: the right amount of memory is usually less than you can technically store, and often less than the demo wants.
There are three reasons. The first is liability. Every durable memory is something you must later be able to find, correct, secure, justify, and delete. A store of ten thousand high-value memories is an asset. A store of ten million low-value ones is a liability you will be auditing during your next compliance review and your next security incident. Storing less is not a limitation; it is risk management.
The second is recall pollution. Memory competes for context budget and for the model's attention. Lost in the Middle, covered at length in the sibling book, showed that models attend unevenly across a long context; a memory recalled into a crowded prompt may be ignored, or worse, a wrong memory recalled alongside the right one may win. The more marginal memories you recall, the more you dilute the signal. A smaller, higher-precision memory set produces better behavior than a large, noisy one.
The third is trust. Every memory the agent surfaces is a small test of the relationship. Surface the user's name and they feel known. Surface a sarcastic aside as a standing preference and they feel misread. Surface a sensitive fact unprompted and they feel surveilled. The expected value of a marginal memory, one you are not sure is welcome, is often negative, because the downside (creepy, wrong, annoying) is worse than the upside (mildly helpful). When in doubt, do not remember. You can always ask.
This is the disposition the book is trying to install, and it is the opposite of the demo's instinct. The demo rewards remembering everything. The product rewards remembering the right things and being comfortable forgetting the rest.
Memory as a product feature with trust costs
It helps to stop thinking of memory as infrastructure and start thinking of it as a feature with a trust budget. Every product has a finite amount of user trust, earned slowly and spent fast. A memory system spends trust every time it surfaces something, and the spending is asymmetric: a hundred correct, welcome recalls build trust slowly; one creepy or wrong recall spends a lot of it at once. The scheduling team did not lose the user over a thousand bad bookings. They lost her over the realization that the system had silently decided something about her that was wrong, and had been acting on it without telling her.
This reframes the engineering. The goal is not to maximize recall coverage. It is to maximize trust-adjusted usefulness: the helpful recalls minus the trust cost of the creepy, wrong, and unauthorized ones. That objective changes your defaults. You confirm before persisting preferences. You make memory visible so the user is never surprised by what the agent knows. You make it editable so a wrong memory is a thirty-second fix, not a three-week silent harm. You make it forgettable by design, with expiry and deletion as first-class operations rather than afterthoughts (see MemGPT for the foundational treatment of managing memory lifecycles, paging, and deletion as deliberate design choices rather than afterthoughts). None of these improve the model. All of them improve the product, because the product is the model plus the governance around its memory.
What this chapter sets up
The 7 a. m. memory is small, and that is the point. It contains, in miniature, every problem the rest of the book addresses: the difference between evidence and conclusion, the five failure modes, the trust matrix, the write that should have been gated, the case for remembering less, and the reframing of memory as a trust-spending feature. From here the book builds the machinery. Chapter 2 gives us the taxonomy, the distinct kinds of memory an agent actually needs, each with its own rules, because you cannot build gates until you know what you are gating. The chapters after that build the gates themselves: the write gate that would have caught the sarcasm, the recall layer that would have let the live request override the stale preference, the reflection policy that keeps generalizations honest, and the governance that lets a user see, correct, and erase what the agent believes about them.
The sticky note on the desk says "prefers morning meetings." Nobody can remember who wrote it, when, or whether it was ever true. By the end of this book, every note in your agent's archive will be able to answer all three questions itself, because a memory is a claim with a source, not a vibe.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.