The Write Gate: Deciding What Deserves to Persist
> **Working claim:** Reading memory is a ranking problem you can iterate on; writing memory is a commitment you live with. A bad read pollutes one action and is gone.

Key Takeaways
- The Write Gate: Deciding What Deserves to Persist is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: Reading memory is a ranking problem you can iterate on; writing memory is a commitment you live with. A bad read pollutes one action and is gone. A bad write is recalled into every relevant future action, for everyone in scope, until a human finds and removes it. So the write gate is the most important component in the system, its default disposition is do not persist, and a candidate fact must earn persistence by clearing every question in the MEMORY framework, not merely by having been said.
The asymmetry, stated precisely
Everything about the write gate follows from one asymmetry, so it is worth stating it as a property rather than an intuition.
A read error has blast radius one and lifetime transient. The agent recalls the wrong memory, takes one suboptimal action, and the next recall might be correct. The error does not propagate; it does not persist; it does not affect other users. You can A/B-test your ranker and roll back a bad change.
A write error has blast radius every future relevant action and lifetime until detected. The agent persists a false fact, and that fact is recalled into every subsequent action where it is relevant, for the owning user, and in shared scopes, for everyone in scope, until a human notices and removes it. If the false fact is plausible and confidently worded, it may never be noticed; it just quietly steers behavior wrong for months. And if the write captured something it was not permitted to keep, you do not have a quality bug; you have a compliance breach with deletion obligations.
This asymmetry dictates the design posture: be liberal about reads, conservative about writes. Read widely and filter; you can always rank, suppress, and ignore. Write narrowly and gate; every durable memory is a long-term liability you carry, secure, justify, and eventually delete. The write gate is the institution that enforces this conservatism, and its default verdict is reject. A candidate does not get persisted because it failed to be rejected; it gets persisted because it affirmatively cleared every gate.
Candidate facts versus durable memories
The first structural move, and the one most teams skip, is to refuse the shortcut of writing whatever the extractor produces. There are two distinct objects, and collapsing them is the root cause of ungoverned memory.
A candidate fact is something the system noticed: an extraction step ran over the task's episodic record and proposed a possible durable claim. Candidates are provisional, untrusted, cheap, and plentiful, a good extractor over-produces, surfacing many possibilities including noise, jokes, hypotheticals, and transient state. A candidate is a nomination, not a decision.
A durable memory is a candidate that passed the gate: evidenced enough, useful enough, permitted, non-contradictory, and assigned an owner and a lifecycle. It is what gets written, recalled, and acted upon.
The extractor's job is to propose; the gate's job is to dispose. When teams wire the extractor directly to the store, they have deleted the only component whose entire purpose is to say no, and a memory system with no ability to say no fills with contradictions, transient asides, misread sarcasm, and things the user explicitly did not want kept.
@dataclass
class CandidateFact:
subject: str # who/what it's about, e.g."user:8831"
claim: str # the proposed durable statement
category: str # attribute|preference|relationship|procedural|...
source_episode_ids: list[str] # provenance: which episodes proposed it
evidence_spans: list[str] # the exact text that justified it
extractor_confidence: float # raw, uncalibrated; the gate recalibrates
observation_count: int # how many distinct episodes support itThat observation_count field is doing quiet, important work. A claim supported by one episode is a guess; a claim supported by five episodes across three sessions is a pattern. The gate treats them differently, and it can only do so if the extractor reports it. This is also where the write amplification discipline from Chapter 3 pays off: because we extract once per task over the whole episodic record rather than per step, the extractor can actually count corroborating observations instead of seeing each utterance in isolation (see MemoryBank for the Ebbinghaus-inspired corroboration model that motivates counting observation frequency as evidence strength).
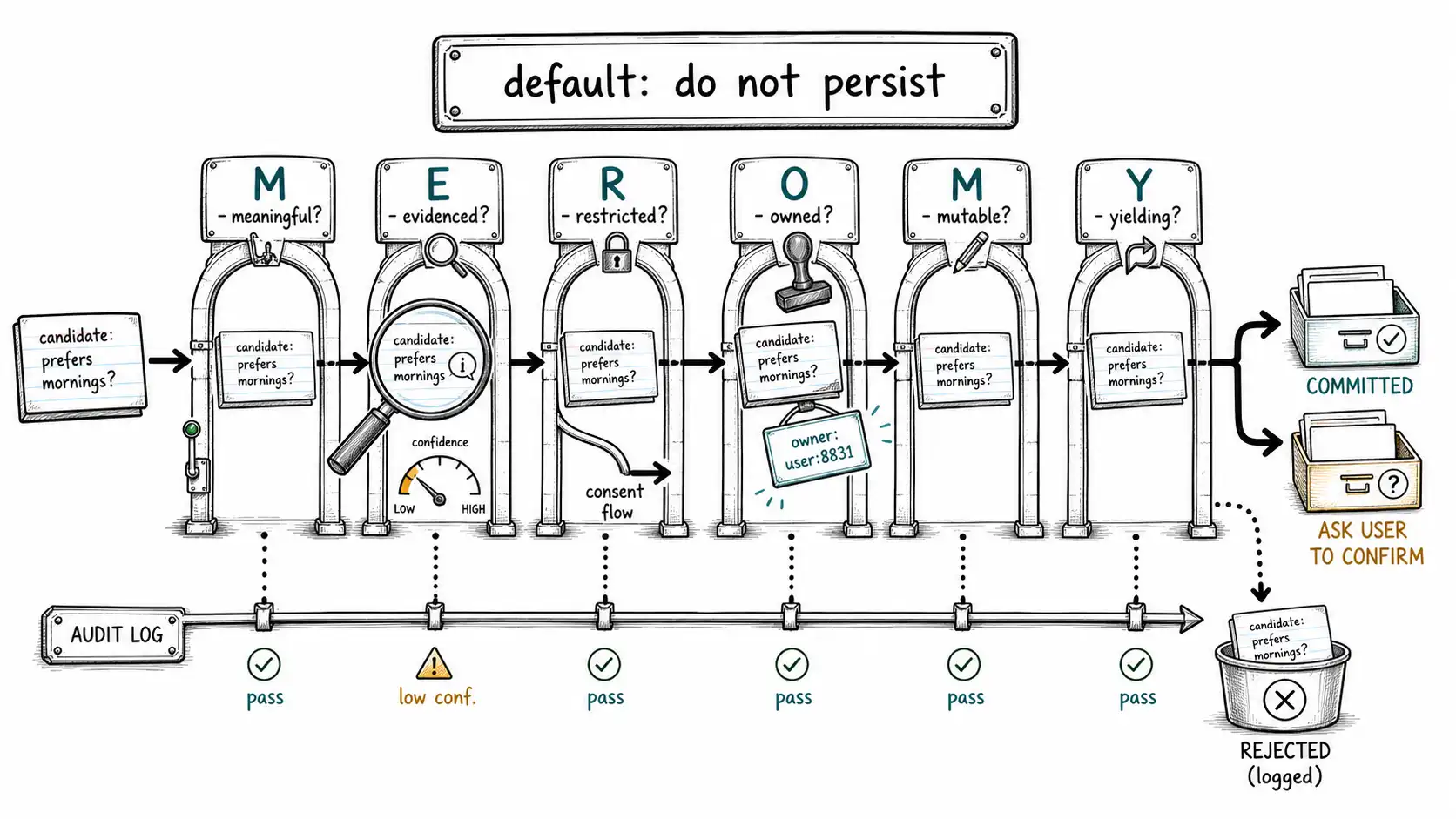
The six gates of MEMORY
The MEMORY framework from the front matter is, operationally, the write gate. A candidate must clear six checks. Some are blocking (fail and the candidate is rejected or routed to confirmation); some are modifying (they do not block but adjust confidence, scope, or expiry). Order matters: cheap structural checks first, expensive model-based checks last, so that most noise is rejected before you spend an inference on it.
M: Meaningful: is this worth persisting at all?
The first and most-often-skipped question. Most of what an agent observes is not worth a durable claim. Transient state ("I'm in a rush today"), conversational filler, one-off context that will never recur, none of it earns a row. The Meaningful gate rejects candidates that are unlikely to be useful in a future task, and it is deliberately strict, because the cost of forgetting something marginal is low (you can re-learn it) and the cost of remembering everything is a polluted store.
A practical heuristic: a candidate is meaningful if recalling it would plausibly change a future action."User's timezone is Pacific" changes scheduling actions, meaningful."User said 'thanks'" changes nothing, not meaningful. Preferences and attributes that recur across tasks are meaningful; ephemeral mood and circumstance are not. This gate alone, applied honestly, removes the majority of candidate volume.
E: Evidenced: what supports it, and how strongly?
A candidate with no source_episode_ids is rejected outright, a memory with no source is a rumor by definition. But the Evidenced gate goes further than presence of provenance; it asks whether the evidence supports the strength of the claim. This is where the 7 a. m. failure is caught. The evidence span "Sure, because I love 7 a. m. meetings" mentions the topic of meeting times, but a literal reading of a non-literal sentence over-states the user's actual belief. The Evidenced gate runs a literalness check, is this sarcastic, hypothetical, quoted, or conditional?, and if the evidence may be non-literal, it does not reject but downgrades confidence and flags for confirmation. The claim that came in at extractor-confidence 0.88 leaves the Evidenced gate at calibrated-confidence 0.4 with a confirmation flag.
M: Mutable: can we correct, expire, and delete it later?
A candidate that cannot be assigned a correction and deletion path should not be written, because an immutable false memory is the worst kind. In practice the Mutable gate is mostly bookkeeping, assign a memory_id, a default expires_at appropriate to the category, and ensure the store supports supersession and revocation, but it is a genuine check in one case: derived memories whose source is about to be deleted. If a candidate's only evidence is an episode the user has asked to be erased, persisting a derived claim from it launders deleted data back into the store, defeating the deletion. The Mutable gate refuses to derive durable memory from to-be-erased evidence.
O: Owned: who controls it?
Every durable memory has exactly one owner_scope, a user, a tenant, or a workspace, and the Owned gate assigns it and refuses to write without it. This is not metadata hygiene; it is the foundation of both access control and deletion. A memory with an ambiguous owner is a cross-tenant leak waiting to happen (Chapter 12) and a deletion request that cannot be honored (Chapter 11). The gate also enforces scope coherence: a candidate derived from a private user episode cannot be written into a shared team scope, because that would expose one user's data to the workspace. The owner of a derived memory is the most-restrictive owner of its evidence, never less restrictive.
R: Restricted: what policy limits its use?
The Restricted gate classifies sensitivity. Some categories, health, finance, legal status, anything in your regulated-data inventory, must never be written by automatic extraction; they are routed to an explicit consent flow or simply not persisted at all, per policy aligned with frameworks like the NIST AI RMF and the sensitive-information-disclosure risk in the OWASP LLM Top 10. The Restricted gate is where "memory minimization" becomes mechanical: the default for sensitive categories is do not persist, and any exception is an explicit, logged, consented decision, not an extractor's confidence score.
Y: Yielding: will recalling it help without dominating?
The last gate looks forward to recall. A candidate that, when recalled, would override the user's likely future intent rather than inform it is dangerous even if true. A preference is written with yields_to_live_intent: true so that recall treats it as a default the present request can override (Chapter 5). A "negative memory", "do not suggest restaurant X again", is written with the recall semantics of a constraint, not a fact. The Yielding gate sets the recall metadata that keeps a memory in its place: informing the agent, not commandeering it.
The gate in code
Here is the gate as a single function, ordered cheap-to-expensive, with each MEMORY check visible. It returns a WriteDecision that is always logged, including rejections, because a rejected write is itself an audit event, and a pattern of rejections (many sensitive candidates from one user) is a signal worth monitoring.
def write_gate(c: CandidateFact, ctx: MemoryContext, user: User) -> WriteDecision:
d = WriteDecision(candidate=c)
# M - Meaningful (cheap structural check first).
if not is_meaningful(c):
return d.reject("not meaningful; would not change a future action")
# E - Evidenced (presence is structural; strength may need a model).
if not c.source_episode_ids:
return d.reject("no provenance")
literalness = classify_literalness(c.evidence_spans) # sarcasm/hypothetical
calibrated = recalibrate(c.extractor_confidence, literalness, c.observation_count)
d.confidence = calibrated
if literalness!= "literal":
d.flag("non-literal evidence; require confirmation")
# R - Restricted (sensitivity routing happens before any auto-write).
if c.category in SENSITIVE_CATEGORIES:
return d.route_to_consent(user) # never auto-persist sensitive
# O - Owned (assign and check scope coherence).
d.owner_scope = most_restrictive_owner(c.source_episode_ids, ctx)
if not d.owner_scope:
return d.reject("ambiguous ownership")
# M - Mutable (refuse to derive from to-be-erased evidence; set lifecycle).
if any(ctx.is_pending_erasure(e) for e in c.source_episode_ids):
return d.reject("evidence pending erasure; would launder deleted data")
d.expires_at = default_ttl_for(c.category)
# Confidence floor AND confirmation policy together.
if c.category == "preference" and (calibrated < 0.6 or d.flagged):
return d.route_to_confirmation(user) # ask, do not assume
if calibrated < CONFIDENCE_FLOOR[c.category]:
return d.reject(f"below confidence floor for {c.category}")
# Contradiction check (expensive: may compare against existing memory).
conflict = ctx.find_contradiction(c, d.owner_scope)
if conflict:
return d.resolve_conflict(conflict) # supersede/merge, never silent overwrite
# Y - Yielding (set recall metadata so the memory informs, not dominates).
d.recall_semantics = recall_semantics_for(c.category) # default|constraint|negative
return d.commit()Read the gate against the 7 a. m. incident and it stops the failure at three independent points: the Evidenced gate flags the sarcastic span as non-literal and downgrades confidence; the recalibrated confidence (well under 0.6 for a single-observation preference) trips the preference-specific confirmation route; and even if both somehow passed, the yields_to_live_intent recall semantics would let the user's live request override the default. The incident required all three of these to be absent. The naive if confidence >= 0.7: insert had none of them.
The candidate scoring rubric
Teams ask for a number, so here is a defensible rubric for recalibrate and the Meaningful gate, expressed as a scoring table rather than a black-box model. The point is that confidence is constructed from observable factors, not handed down by an extractor.
| Factor | Effect on persistence score | Rationale |
|---|---|---|
| Observation count = 1 | strong penalty for preferences/attributes | one mention is a guess, not a pattern |
| Observation count ≥ 3 across sessions | strong boost | corroboration across time is the best evidence |
| Evidence literalness = sarcastic/hypothetical/quoted | strong penalty + confirmation flag | non-literal text over-states belief |
| User stated it directly and unambiguously | boost | direct statement is the cleanest evidence |
| Derived from a tool result (untrusted source) | penalty + no auto-write | untrusted provenance (Chapter 12) |
| Category is sensitive | route to consent, do not score for auto-write | policy, not confidence |
| Contradicts an existing high-confidence memory | route to conflict resolution | never silently overwrite |
| Recency of evidence | mild boost for recent | stale evidence supports stale facts |
This rubric is not the final word, Chapter 13 is about calibrating it so that a 0.8 actually means 80% of such memories are correct, but it makes the construction of confidence inspectable, which a raw extractor logit never is. A reviewer can look at a written memory, see it scored 0.4 because it had one non-literal observation, and understand exactly why it was routed to confirmation.
Confirmation prompts that do not manipulate
When the gate routes a candidate to confirmation, the wording matters, and it is an ethics-of-product question, not just UX. A confirmation prompt should make it easy to say no, present the inference neutrally, and never use a default or a dark pattern to harvest a yes. Compare:
- Manipulative: "I'll set your meetings to mornings since you love them! (Tap to undo)", assumes consent, frames disagreement as effort, and pre-commits the write.
- Neutral: "Want me to default new meetings to mornings? You can change this anytime in Memory settings. [Yes] [No, ask each time]", states the inference, offers a real no, points to the control surface, and does not write until answered.
The neutral version also writes the user's answer as the durable memory, not the agent's inference, confirmed_by_user: true with the confirmation episode as provenance, which is a far stronger basis than an extractor's reading of a sarcastic sentence. Confirmation does not just reduce false memory; it upgrades the evidence from inference to declaration.
Conflict detection at write time
The Restricted and contradiction checks deserve a closer look at the data layer, because "never silently overwrite" is easy to say and easy to violate. When a candidate contradicts an existing memory, the gate must detect the contradiction before committing, which means querying the store for memories about the same subject and category that assert something incompatible.
-- Find existing, live memories that may contradict a candidate before write.
-- Same subject + category, not revoked, not expired, not already superseded.
SELECT memory_id, claim, confidence, last_confirmed_at
FROM semantic_memory
WHERE subject =:subject
AND category =:category
AND revoked_at IS NULL
AND superseded_by IS NULL
AND (expires_at IS NULL OR expires_at > now())
ORDER BY confidence DESC, last_confirmed_at DESC;The candidate claim and each existing claim then go to a contradiction check (a model call or a structured comparison, depending on category). If they agree, the candidate is a re-confirmation, bump the existing memory's last_confirmed_at and confidence rather than writing a duplicate. If they contradict, you do not overwrite; you supersede: write the new memory, set the old one's superseded_by to the new memory_id, and keep the chain. Supersession preserves the audit trail (you can see the timezone changed from Pacific to Eastern and when) and makes correction reversible (if the new fact turns out wrong, the old one is still recoverable). Silent overwrite, the UPDATE... SET claim =: new that most teams write, destroys the history and makes a wrong correction unrecoverable.
Why not every repeated statement is a memory
A closing caution, because the rubric's boost for observation count invites a misreading. Corroboration across sessions is strong evidence that the user keeps saying something, which is not the same as that it is true and should be acted on. A user who repeatedly complains "this is so slow" is not asserting a durable performance fact; they are venting, repeatedly, about transient states. An agent that promotes repeated venting to a durable "the user thinks the product is slow" memory has confused frequency for fact. The Meaningful gate is the defense: repetition of something that would not change a future action if recalled is still not meaningful, no matter how often it is repeated. The gate counts observations as evidence of patterns worth acting on, not as a popularity vote that overrides judgment about whether the thing belongs in memory at all.
What this chapter sets up
The write gate is the heart of the system, and we have now built it: the candidate/durable distinction, the six MEMORY checks, the scoring rubric, non-manipulative confirmation, and supersession over silent overwrite. Everything downstream depends on it. Recall (Chapter 5) trusts that what it reads cleared the gate. Reflection (Chapter 6) runs its derived claims through the same gate, because a reflection is just another candidate with a more elaborate provenance (see Reflexion and Generative Agents for the two foundational treatments of how reflection-generated memory should be gated against external evidence before persisting). Procedural memory (Chapter 7) adds a testing requirement on top of the gate. Governance (Chapter 11) operates on the owner_scope and consent_basis the gate assigned. And security (Chapter 12) hardens the gate against an adversary deliberately crafting candidates to slip through it.
We have decided what gets in. Next we decide what comes out, and discover that recall, which everyone assumes is the easy half, has its own way of being quietly wrong.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.