Procedural Memory and Skill Libraries
> **Working claim:** Facts let an agent answer; skills let an agent *act*. A skill library is the memory that turns a hard-won success into a reusable capability, and it is the closest thing an agent has to genuine improvement.

Key Takeaways
- Procedural Memory and Skill Libraries is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: Facts let an agent answer; skills let an agent act. A skill library is the memory that turns a hard-won success into a reusable capability, and it is the closest thing an agent has to genuine improvement. But a skill is executable memory, which means a bad skill does not give one wrong answer, it produces wrong behavior every time it is invoked, and worse, the agent composes new skills on top of it. Procedural memory therefore needs what no other memory type does: tests, versions, and a retirement path.
What procedural memory is, and why it is different
Every other memory type in this book stores claims about the world: what happened, what is true, what the user prefers, what is open. Procedural memory stores methods for acting in the world: how to run this repository's tests, how to deploy to staging, how to research a company, how to craft a pickaxe. It is the difference between knowing that and knowing how, and for an agent the second is often more valuable, because the whole point of an agent is to act.
The landmark demonstration is Voyager, an agent that played Minecraft by building a growing library of executable skills. When it figured out how to do something, chop wood, craft a tool, fight a mob, it wrote that procedure as a callable program into a skill library, indexed by a description of what the skill accomplished. Later, facing a harder task, it retrieved relevant skills and composed them into more complex behavior, building a curriculum of increasingly capable actions on top of the simpler ones it had already mastered. The result was an agent that got measurably better over time without any change to the underlying model. The skills were the learning.
That is the promise and the shape of procedural memory: a store of reusable, composable, executable methods that grows as the agent succeeds. But three properties make it unlike the fact-stores, and each property is also a hazard:
- It is executable. A skill is code, or a structured plan, or a tool sequence, something that runs. This is wonderful because it means a skill can be tested, which no fact can. It is dangerous because a wrong skill does damage when invoked, not just gives a wrong answer.
- It composes. Skills build on skills. This is the source of compounding capability, and the source of compounding fragility: a bug in a low-level skill propagates into every higher-level skill that calls it.
- It has a large, recurring blast radius. A false fact is recalled when relevant; a bad skill runs every time the task type recurs, for as long as it stays in the library, which can be a very long time.
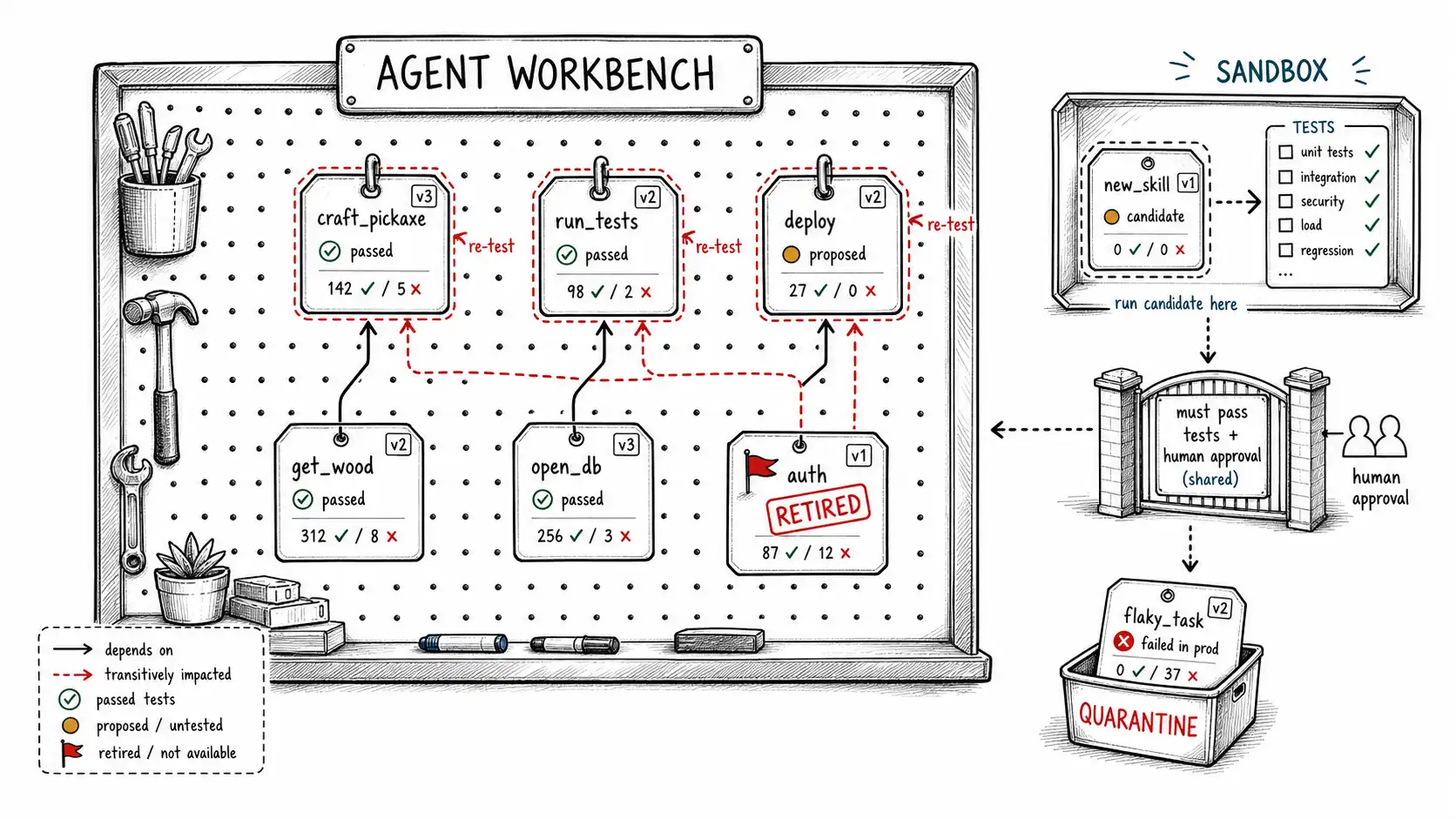
The skill schema
A skill is not a snippet of code in a vector store. It is a governed artifact with everything needed to retrieve it, run it safely, test it, version it, and retire it. Here is the manifest.
{
"skill_id": "skill_run_tests_repoX",
"name": "run_integration_tests",
"description": "Run the integration test suite for repository X, including DB setup.",
"trigger_signature": { // when this skill is a candidate for recall
"task_type": "run_tests",
"preconditions": ["repo == 'X'", "branch checked out", "venv available"]
},
"body": {
"kind": "tool_sequence", // or "code" | "plan"
"steps": [
{"tool": "shell", "cmd": "source.venv/bin/activate"},
{"tool": "shell", "cmd": "export TEST_DB_URL=$STAGING_DB"},
{"tool": "shell", "cmd": "pytest -m integration"}
]
},
"postconditions": ["test report produced"],
"version": 4,
"status": "stable", // proposed | stable | deprecated | retired
"provenance": {
"learned_from_episode_ids": ["ep_q1", "ep_q2"],
"first_succeeded_at": "2026-01-12T10:00:00Z"
},
"tests": ["test_runs_clean", "test_handles_missing_db"],
"success_count": 41,
"failure_count": 2,
"last_success_at": "2026-03-09T08:00:00Z",
"last_failure_at": "2026-02-20T11:00:00Z",
"owner_scope": "workspace:eng-platform",
"approved_by": "user:lead-9921" // human approval for shared/high-impact skills
}Several fields exist precisely because a skill is executable and the others are not. trigger_signature with explicit preconditions lets recall match a skill on applicability rather than fuzzy similarity, you do not want to invoke "run integration tests" on a repo where the preconditions do not hold. tests names the verification suite the skill must pass before it is trusted. version and status are the lifecycle. success_count/failure_count are the running evidence of whether the skill still works. And approved_by records that a human signed off, which for shared or high-impact skills is mandatory, because an unreviewed skill written into a team library will run on everyone's behalf.
The write gate for skills: success is necessary, not sufficient
A skill becomes a candidate when an action sequence succeeds. Voyager's heuristic was essentially this: if the agent accomplished a new task, refactor the actions into a reusable skill and store it. That is a reasonable trigger, but "it worked once" is a dangerously weak basis for "store it as a reusable capability, " because a one-time success can be luck, can depend on transient state, or can succeed by side effects you do not want repeated.
So procedural memory has its own write gate, layered on top of the MEMORY gate from Chapter 4 and stricter in one specific way: a skill must pass tests before it is trusted, not just succeed once (see Reflexion for the complementary approach of using verbal outcome feedback across trial episodes to improve reliability rather than a one-shot success).
def propose_skill(episodes: list[Episode], ctx: MemoryContext) -> SkillDecision:
# 1. Extract a candidate skill from a successful action sequence.
candidate = refactor_actions_into_skill(episodes)
# 2. Generalize carefully: the skill must NOT hard-code transient values.
# (e.g. a literal ticket ID, a one-time token, today's date.)
leaks = find_transient_literals(candidate) # over-specific = won't generalize
if leaks:
candidate = parameterize(candidate, leaks) # turn literals into parameters
# 3. Generate and RUN tests in a sandbox before trusting the skill.
tests = synthesize_skill_tests(candidate) # incl. precondition failures
result = run_in_sandbox(candidate, tests)
if not result.all_passed:
return SkillDecision.reject(f"failed tests: {result.failures}")
# 4. Status starts at 'proposed', not 'stable'. It earns 'stable' by
# succeeding in real use N times (see promotion below).
candidate.status = "proposed"
# 5. Shared/high-impact skills require human approval before any use.
if candidate.owner_scope.is_shared() or candidate.is_high_impact():
return SkillDecision.route_to_approval(candidate)
return SkillDecision.commit(candidate)Two steps deserve emphasis. find_transient_literals / parameterize addresses the most common skill-learning failure: the agent succeeded by doing something specific to the moment, referencing ticket #4471, using a token that has since expired, assuming today is a weekday, and stored those specifics as if they were part of the method. A skill that hard-codes transient state will fail or, worse, do the wrong thing the next time the task type recurs with different specifics. Generalization is not optional; an over-specific skill is a landmine. And the proposed versus stable distinction means a freshly-learned skill is available but unproven: the agent may use it, but recall knows it is provisional, and it must accumulate real successes before it is trusted enough to be composed into other skills.
Composition and the propagation of bugs
Composition is where procedural memory earns its power and its fragility in the same motion (see Toolformer for how language models self-learn to call tools and Generative Agents for how composite action sequences get stored as reusable social and task behaviors). When skill B calls skill A, B inherits A's correctness. If A is solid, B builds on a foundation. If A has a subtle bug, B has that bug too, and so does C which calls B, and the agent's growing capability is quietly growing on a crack.
This argues for treating the skill library as a dependency graph, not a flat list, and reasoning about it the way you reason about a software dependency tree.
# Skills form a DAG: each skill records which other skills it composes.
@dataclass
class Skill:
skill_id: str
depends_on: list[str] # skill_ids this skill calls
version: int
status: str
def dependents_of(skill_id: str, ctx) -> set[str]:
"""Every skill that (transitively) composes the given skill."""
out, frontier = set(), [skill_id]
while frontier:
s = frontier.pop()
for d in ctx.skills.calling(s): # direct callers
if d not in out:
out.add(d)
frontier.append(d)
return outThe payoff comes at retirement (below): when a skill goes bad, dependents_of tells you the full blast radius, every higher-level skill that is now suspect because it composed the broken one. Without the dependency graph, retiring a bad low-level skill leaves a fleet of higher-level skills silently calling a retired or fixed dependency, behaving inconsistently. With it, you can re-test and re-version the whole affected subtree. A skill library without dependency tracking is a codebase without a build graph: it works until a change ripples, and then nobody can find what broke.
Skill drift: when a working skill quietly stops working
The most insidious procedural failure is not a bad skill at birth; it is a good skill that decays. The world the skill acts in changes, the test command changes, the API the skill calls is deprecated, the staging URL moves, the file structure is refactored, and the skill, frozen as it was when learned, now does the wrong thing. This is skill drift, and it is procedural memory's version of the stale-fact problem from Chapter 2, except the stakes are higher because the skill executes.
Drift is detected not by time (a skill unused for a month is not necessarily stale) but by failure signal. The success_count/failure_count and last_failure_at fields exist for this. A skill whose recent failure rate climbs is drifting, and the system should respond before it does more damage:
def assess_skill_health(skill: Skill, ctx) -> SkillHealth:
recent = ctx.skill_runs.recent(skill.skill_id, window=last_30_days())
if not recent:
return SkillHealth. IDLE # not stale, just unused
failure_rate = sum(r.failed for r in recent) / len(recent)
if failure_rate > FAIL_THRESHOLD:
# Drift detected. Demote so recall won't prefer it, and flag for repair.
ctx.skills.set_status(skill.skill_id, "deprecated")
ctx.alerts.skill_drift(skill, failure_rate)
return SkillHealth. DRIFTING
if failure_rate > WARN_THRESHOLD:
return SkillHealth. DEGRADING
return SkillHealth. HEALTHYDemotion to deprecated is deliberately reversible and non-destructive: the skill is not deleted (it may be repairable, and its provenance is valuable), but recall stops preferring it, so the agent falls back to solving the task from scratch (slower but correct) rather than confidently running a broken procedure (fast but wrong). The fallback-to-first-principles behavior is the safety net: a drifting skill should degrade the agent to "figures it out again, " never to "does the wrong thing efficiently."
Versioning learned procedures
Because skills change, repaired after drift, generalized after an over-specific first version, improved when the agent finds a better method, they must be versioned, and versioning procedural memory is closer to versioning software than versioning data. The principles transfer: never mutate a stable version in place; create a new version; keep the old one until the new one has proven itself; and let dependents pin to a version if a change would break them.
The lifecycle of a skill version:
| Status | Meaning | Recall behavior | How it transitions |
|---|---|---|---|
proposed | Learned and passed tests, unproven in real use | Available but marked provisional; not composed into stable skills | Promote to stable after N real successes |
stable | Proven in production use | Preferred for recall; safe to compose | Demote on drift; supersede on improvement |
deprecated | Drifting or superseded by a better version | Not preferred; agent prefers alternatives or first principles | Repair → new version, or retire |
retired | Removed from active use | Never recalled | Kept in record for audit + dependency analysis |
The proposed → stable promotion is the procedural analogue of confirmation for preferences. A freshly learned skill, like a freshly inferred preference, is a hypothesis. It earns trust through repeated real-world success, not through having worked once in the episode that birthed it. Promoting on first success is how a lucky one-off becomes a trusted-but-fragile capability that fails the third time the task recurs.
The runbook for retiring a bad skill
When a skill is found to be actively harmful, it does the wrong thing, it was poisoned (Chapter 12), or drift has made it dangerous rather than merely degraded, you need a retirement runbook, because retiring procedural memory is not a single DELETE. The skill executes, it composes, and it may be mid-use.
- Quarantine immediately. Set status to
retiredand add the skill to a recall denylist so no new invocation can pick it up. This stops the bleeding before you understand the full scope. - Find the blast radius. Run
dependents_of(skill_id)to enumerate every higher-level skill that composed it. All of them are now suspect, because they inherited the broken behavior. - Demote the subtree. Set every dependent to
deprecatedso the agent stops preferring them and falls back to first principles while you assess. - Audit recent invocations. Query the episodic and audit logs for every action the bad skill took recently: this is the list of potential harms to review and, where possible, reverse. (Did the broken deploy skill push bad config? Where, and when?)
- Repair or replace. Fix the skill as a new version, re-run the full test suite plus a regression test for the specific failure, and re-test the dependent subtree against the repaired version.
- Re-promote cautiously. The repaired skill re-enters as
proposed, notstable. It must re-earn trust, exactly as if it were new, because trust does not survive a serious failure intact. - Record the incident. Write the failure, its cause, and the retirement to the audit log, and add the failure case as a permanent regression test so the same drift cannot recur silently.
-- Step 4: every action a suspect skill took recently, for harm assessment.
SELECT e.episode_id, e.occurred_at, e.content, e.tool_call_id, e.owner_scope
FROM episodic_memory e
WHERE e.kind = 'action'
AND e.skill_id =:retired_skill_id
AND e.occurred_at > now() - interval '30 days'
ORDER BY e.occurred_at DESC;The runbook exists because procedural memory is the one memory type whose failures change the world. A bad fact gives a wrong answer the user can ignore. A bad skill may have already deployed broken config, deleted the wrong files, or sent the wrong emails, across every task where it ran. Retirement is therefore an incident response, not a cleanup, and it is the strongest argument for the tests, versions, dependency graph, and audit trail this chapter has insisted on: without them, you cannot even answer "what did the bad skill do, and to whom?"
Catastrophic forgetting versus unsafe accumulation
There is a tension worth naming, because it shapes how aggressively you prune procedural memory. Forget too much and the agent suffers catastrophic forgetting, it loses hard-won skills and re-solves the same problems repeatedly, the opposite of improvement. Accumulate too much and the library fills with stale, drifting, redundant, and unproven skills, recall slows and degrades, and the agent's behavior becomes unpredictable as it picks among overlapping skills of varying quality, unsafe accumulation.
The resolution is the same disposition the whole book argues for, applied to skills: be conservative about what you promote to stable, liberal about deprecating the drifting, and retire (but retain in record) rather than delete. A healthy skill library is small and trusted, not large and uneven (see MemGPT for the design principle of treating external procedural memory as deliberately-paged state rather than an unlimited accumulation). The agent that remembers ten skills it can rely on absolutely is more capable than the one that remembers a hundred it must constantly second-guess, the same lesson as remembering-less from Chapter 1, now applied to the memory of how to act.
What this chapter sets up
Procedural memory is where an agent's improvement becomes concrete and where the consequences of bad memory become physical, because skills execute. We have built it as governed software: a manifest with triggers and tests, a write gate that demands passing tests and parameterized generalization rather than one lucky success, a dependency graph for composition, drift detection by failure signal, version lifecycle, and a retirement runbook for when a skill goes bad.
Skills are how an agent remembers how to act. But action happens in service of goals, and goals outlive sessions, an agent works on something for days, gets interrupted, resumes, hands off. Remembering an in-flight objective across that span is its own problem, and most frameworks handle it badly by stuffing it into the conversation history. The next chapter builds long-horizon task memory as the first-class store it deserves to be.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.