Privacy, Consent, Deletion, and Governance
> **Working claim:** A memory system that cannot forget is not a feature; it is a liability with a deletion deadline.

Key Takeaways
- Privacy, Consent, Deletion, and Governance is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: A memory system that cannot forget is not a feature; it is a liability with a deletion deadline. The moment an agent stores durable facts about people, you have taken on duties: to ask before keeping sensitive things, to show people what you remember, to let them correct it, to actually erase it when they ask, including from the summaries and reflections it leaked into, and to keep one user's memory from ever surfacing in another's session. These are not nice-to-haves bolted on at the end. They are constraints that must be designed into the schema, the write gate, and the recall path from the first commit.
Memory is personal data, and the law already knows it
Engineers tend to think of agent memory as a technical convenience. Privacy regulators think of it as a store of personal data, and they are right. A durable record that "user 8831 is vegetarian, lives in Seattle, is stressed about a custody case, and prefers to be contacted in the evening" is exactly the kind of profile that data-protection law exists to govern. Under regimes like the GDPR, that record carries obligations: a lawful basis to hold it, a duty of data minimisation (keep only what you need, only as long as you need it), and a right to erasure that lets the user demand it be deleted. The NIST AI RMF frames the same concerns as governance and risk-management functions. And the OWASP LLM Top 10 names sensitive information disclosure as a top application risk, which is precisely what an over-broad memory store, recalled into the wrong context, produces.
The practical consequence: the governance features in this chapter are not optional polish. If your agent remembers things about people in jurisdictions with these laws, which is most jurisdictions, for most products, then consent, visibility, correction, deletion, and isolation are requirements, and a memory architecture that cannot support them is not shippable. The good news is that the architecture we have built, provenance, owner_scope, consent_basis, supersession, revocation, cascade-to-derived, was designed with exactly these duties in mind. Governance is not a new system bolted on; it is the schema fields finally being used for what they were for.
Consent: ask before you keep the sensitive things
Consent is not a checkbox at signup that authorizes remembering everything forever. It is a per-category, ongoing judgment about what the agent may keep, and the architecture should make the default minimal. The write gate's Restricted check (Chapter 4) is the enforcement point: sensitive categories, health, finance, legal status, location patterns, anything in your regulated-data inventory, never auto-persist. They route to an explicit consent flow, or they are simply not kept.
# Consent policy as data: what may be remembered, on what basis, for how long.
CONSENT_POLICY = {
"preference": {"default": "infer_with_confirmation", "retention_days": 365},
"attribute": {"default": "infer_with_confirmation", "retention_days": 365},
"health": {"default": "explicit_consent_only", "retention_days": 90,
"auto_extract": False}, # never auto-extracted, ever
"finance": {"default": "explicit_consent_only", "retention_days": 90,
"auto_extract": False},
"location": {"default": "session_only", "retention_days": 0},
"credentials": {"default": "never_store", "retention_days": 0},}
def consent_required(candidate, policy=CONSENT_POLICY):
rule = policy.get(candidate.category, policy["attribute"])
if rule["default"] == "never_store" or not rule.get("auto_extract", True):
return ConsentVerdict. BLOCK_AUTO # cannot be written by extraction
if rule["default"] == "explicit_consent_only":
return ConsentVerdict. NEEDS_EXPLICIT
if rule["default"] == "session_only":
return ConsentVerdict. NO_DURABLE # live in working memory, never persist
return ConsentVerdict. INFER_WITH_CONFIRM # the default-but-confirmed pathTwo categories in that policy never become durable memory under any automatic path. credentials, passwords, API keys, tokens, are never_store, full stop; an agent that "remembers" a credential has created a secret-sprawl incident. location is session_only: useful for the current task, never persisted as a durable pattern, because a stored history of where someone is is among the most sensitive profiles you can build. Encoding consent as data like this, rather than as scattered if statements, means it is auditable, reviewable by legal and compliance, and changeable without code edits, which is itself a governance property.
Visibility: the user can see what the agent remembers
A memory the user cannot see is a memory the user cannot trust. The single most effective trust-building feature in a memory system is a memory control panel: a place where the user views everything the agent remembers about them, organized by category, with the source and the date. Visibility is also a forcing function on quality, if engineers know users will see the stored memories, they build a store worth showing, which is a store without the 7 a. m. nonsense in it.
The visibility API is a scoped read over the store, returning memories in human-readable form with their provenance:
def list_user_memories(user_id: str, ctx: MemoryContext) -> list[MemoryView]:
"""Everything we remember about this user, for THEM to see. Scope is the
user themselves; this is the one read where the subject is the audience."""
rows = ctx.query(owner_scope=f"user:{user_id}", include_revoked=False)
return [
MemoryView(
id=m.memory_id,
statement=humanize(m.claim), # "You prefer concise answers"
category=m.category,
learned_from=summarize_source(m.source_episode_ids), # "from your message on Mar 4"
confidence_label=label(effective_confidence(m, now())), # high/medium/low
editable=True,
authored_by=m.authored_by, # "you told me" vs "I inferred"
)
for m in rows
]The authored_by distinction from Chapter 6 earns its keep here: showing the user which memories they stated versus which the agent inferred is both honest and useful, because users are far more willing to correct an inference than to argue with their own past words, and the inferences are exactly where the errors cluster. A control panel that surfaces inferences for review turns the user into a free, high-quality correction signal.
Correction and the right to edit
Visibility without editability is a museum. The user must be able to correct what the agent believes, and correction should be a first-class operation that flows through the same supersession machinery as any other change, because a user correction is the highest-quality evidence you can get.
def user_corrects(user_id, memory_id, corrected_claim, ctx):
old = ctx.load(memory_id)
assert old.owner_scope == f"user:{user_id}" # users edit only their own
new = Memory(
claim=corrected_claim,
category=old.category,
confidence=0.99, # user-stated correction: top trust
authored_by="user",
confirmed_by_user=True,
source_episode_ids=[ctx.log_correction_episode(user_id, memory_id)],
owner_scope=old.owner_scope,)
ctx.supersede(old.memory_id, new) # chain preserved, recoverable
ctx.cascade_invalidate_derived(old.memory_id) # summaries/reflections re-deriveThe cascade_invalidate_derived call is the part teams forget, and forgetting it makes correction feel broken to users. A user corrects "I'm in Eastern time, not Pacific, " the system supersedes the fact, and then the agent keeps acting on a summary that says "schedules around West Coast hours, " because the summary was never invalidated. From the user's view, they corrected the memory and the agent ignored them, which is worse than not offering correction at all. Correction must propagate to everything derived from the corrected memory, or it is theater.
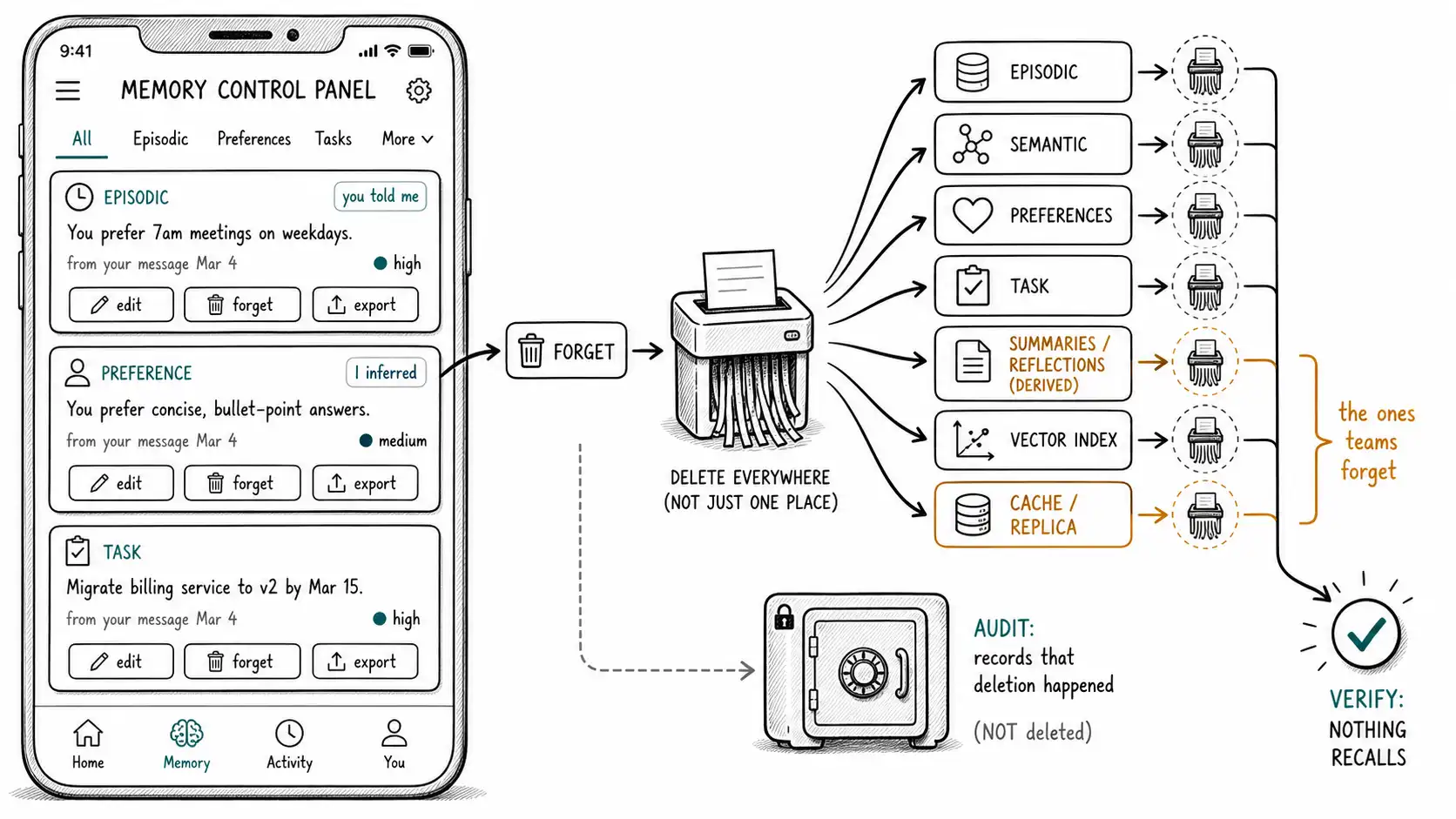
Deletion that actually deletes
The right to erasure is where memory architecture is truly tested, because deletion in a memory system is not a single DELETE statement. A user's data is spread across episodic logs, derived semantic facts, preferences, summaries, reflections, task memory, and possibly shared scopes. Deleting "the user's memory" means finding and erasing it everywhere it propagated, including the derivations that no longer obviously point back to the user. Deletion that misses the derivations is the laundering failure: the raw fact is gone, but a reflection built on it still drives behavior, and the "deleted" information lives on in a form that is harder to find precisely because its source was erased.
def erase_user(user_id: str, ctx: MemoryContext) -> ErasureReport:
report = ErasureReport(user_id=user_id, at=now())
# 1. Record the erasure FIRST - the fact of deletion is itself retained.
ctx.audit("erasure_requested", actor=f"user:{user_id}", detail={...})
# 2. Direct memories: every store keyed to this user.
for store in (ctx.episodic, ctx.semantic, ctx.preference, ctx.task):
report.direct += store.hard_delete(owner_scope=f"user:{user_id}")
# 3. Derived memories: summaries/reflections that cite this user's episodes,
# even if they no longer name the user directly.
derived = ctx.find_derived_from_owner(f"user:{user_id}")
report.derived += ctx.hard_delete_many(derived)
# 4. Shared scopes: facts the user contributed to a workspace. These are
# nuanced - a team fact the user established may need to survive (it's the
# team's), but their PERSONAL data in shared scope must go. Policy decides.
report.shared += ctx.erase_personal_in_shared(user_id)
# 5. Caches, embeddings, search indexes: deletion must reach the copies.
ctx.purge_indexes_for(f"user:{user_id}") # vector index, cache, replicas
# 6. Verify: re-query to confirm nothing recalls. Erasure you can't verify
# isn't erasure.
report.verified = ctx.verify_no_recall(f"user:{user_id}")
ctx.audit("erasure_completed", actor="system", detail=report.as_dict())
return reportThree of these steps are where real deletions fail in production. Step 3 (derived memories) is the laundering trap above. Step 5 (indexes and caches) is the subtle one: a vector index, a search cache, or a read replica can retain a memory that has been deleted from the primary store, and a recall that hits the stale index resurfaces a "deleted" memory, so deletion must reach every copy, which means your architecture must know where the copies are. Step 6 (verification) closes the loop: an erasure you cannot verify is a compliance claim you cannot defend. The pattern throughout: deletion is a workflow with a report, not a statement, and it must be auditable, complete, and verified.
Retention: keep only as long as you need
Data minimisation has a temporal dimension: even data you may keep, you should not keep forever (see Google Vertex AI Agent Engine Memory Bank for a production example of per-scope retention and deletion controls in a managed memory service). Retention policy sets a maximum lifetime per category (the retention_days in the consent policy above), after which a memory is deleted regardless of whether anyone asked. This is the proactive complement to user-initiated erasure, and it dramatically shrinks both your liability surface and your blast radius if you are breached, a store that holds ninety days of sensitive memory is a smaller catastrophe than one holding seven years of it.
-- Retention sweep: hard-delete memories past their category's retention window.
-- Runs on a schedule; respects legal holds; writes audit records.
WITH expired AS (
SELECT m.memory_id, m.category, m.owner_scope
FROM semantic_memory m
JOIN retention_policy r ON r.category = m.category
WHERE m.created_at < now() - (r.retention_days || ' days')::interval
AND m.owner_scope NOT IN (SELECT scope FROM legal_holds)
)
DELETE FROM semantic_memory WHERE memory_id IN (SELECT memory_id FROM expired);The legal_holds exception is important and cuts the other way: sometimes you are required to retain (litigation hold, regulatory record-keeping), and a blind retention sweep that deletes held data is its own violation. Retention is therefore a balance, minimise by default, but honor holds, and the policy must encode both directions.
Tenant isolation: one user's memory never surfaces in another's
The failure that ends companies is cross-tenant leakage: customer A's memory surfacing in customer B's session. It is the worst because it is silent (B may never report seeing A's data, but A's data was exposed), because it scales (one bug leaks many records), and because it is a breach, not a bug. Isolation is enforced by the scope hierarchy (Chapter 9) and the scope-before-score recall rule (Chapter 5), but it must be tested adversarially, not just asserted.
def test_tenant_isolation():
# Seed identical, highly-relevant memories for two tenants.
seed_memory(tenant="A", claim="The admin password rotation is monthly")
seed_memory(tenant="B", claim="The admin password rotation is weekly")
# Recall AS tenant B, with a query that would match BOTH on relevance.
results = recall(query="how often do we rotate admin passwords?",
requester=Identity(tenant="B"))
# Tenant A's memory must be INVISIBLE - not down-ranked, absent.
assert all(r.owner_scope.tenant == "B" for r in results), \
"CROSS-TENANT LEAK: tenant A memory surfaced for tenant B"
assert not any("monthly" in r.claim for r in results)This test belongs in the suite that gates every deploy, and it must use highly relevant cross-tenant memories, the dangerous case is precisely when the other tenant's memory is so on-topic that a relevance-only system would surface it. A test with irrelevant cross-tenant data passes trivially and proves nothing. The assertion is all results are tenant B, not tenant A is ranked low, because isolation is a hard boundary: there is no acceptable relevance score at which another tenant's memory may appear.
Work versus personal: the same user, different contexts
A subtler scoping problem: the same human in two roles. An enterprise copilot serves Sam at work; Sam's personal assistant serves Sam at home. These should not share memory, even though they are the same person, because Sam's personal health note has no business in the work copilot and Sam's confidential work project has no business in the personal assistant. The owner_scope must distinguish not just who but in what context, user: sam@work versus user: sam@personal, and recall must respect the boundary. Users intuitively expect this separation (they are unsettled when work systems know personal things and vice versa), and honoring it is both a privacy duty and a trust feature. Memory minimisation includes minimising which context a memory leaks into, not only how much you keep.
What this chapter sets up
Governance is the part of memory engineering where the bill comes due: consent encoded as per-category policy with sensitive categories blocked from auto-extraction; visibility through a control panel that shows users what the agent remembers and how it learned it; correction through supersession that cascades to derivations; deletion as an auditable, complete, verified workflow that reaches derived memory and every cached copy; retention that minimises by default while honoring legal holds; tenant isolation tested adversarially as a hard boundary; and work/personal separation as a scoping discipline. These are not features you add when a regulator calls; they are constraints the architecture has carried since the first commit, finally exercised.
Governance defends against the system's own carelessness and the law's requirements. The next chapter defends against something worse: an adversary who wants your memory to be wrong, who crafts inputs specifically to plant false durable beliefs, poison shared memory, and turn the agent's own recall against it. Memory is not just a privacy surface. It is an attack surface.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.