The Agent's Read/Write Loop
> **Working claim:** A chatbot reads memory at the start of a turn and writes it at the end. An agent lives in a loop where memory is touched at every step, read to decide, written as it acts, re-read after each tool result.

Key Takeaways
- The Agent's Read/Write Loop is a chapter about agent memory systems, not a generic AI adoption note.
- The operating rule is to treat every memory as a sourced, scoped, revisable claim instead of an ambient fact.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Agent memory is useful only when every stored claim has source, scope, decay, and deletion rules.
Working claim: A chatbot reads memory at the start of a turn and writes it at the end. An agent lives in a loop where memory is touched at every step, read to decide, written as it acts, re-read after each tool result. This interleaving is what makes agent memory its own discipline, and it introduces failure modes a turn-based system never sees: mid-task memory drift, write-amplification inside loops, and the agent acting on a memory it wrote three steps ago in the same task.
Two diagrams that look similar and are not
Draw the memory flow of a chatbot and the memory flow of an agent on the same whiteboard and they will look almost identical for the first two boxes, which is exactly why teams build agent memory as if it were chatbot memory and then wonder why it behaves strangely.
The chatbot flow:
[turn starts] -> recall relevant memory -> build prompt -> model responds
-> extract candidate memories -> write -> [turn ends]Read once, write once, per turn. Memory is a bookend. The transcript is the loop; memory wraps around it.
The agent flow:
[task starts]
-> recall task + procedural + semantic memory
-> LOOP:
-> model reasons about next step (reads working state)
-> model calls a tool
-> tool returns a result <-- new information enters mid-task
-> agent may WRITE episodic memory of the action
-> agent may WRITE/UPDATE task memory (subtask done, blocker found)
-> agent may RE-RECALL memory triggered by the new result
-> repeat until done or stuck
-> on success: maybe consolidate a procedural skill
-> on failure: maybe write a reflection
[task ends]The agent reads and writes inside the loop, many times, and the loop can run for dozens of iterations across one task and many sessions. Memory is not a bookend; it is load-bearing structure threaded through every step. This is the ReAct pattern, interleaved reasoning and acting, extended with persistent memory (see Toolformer for the complementary treatment of how models learn to call tools as first-class reasoning steps), and it changes the engineering problem entirely. In a chatbot, a memory error pollutes one answer. In an agent, a memory error written at step 3 is read at step 7, acted on at step 9, and compounded into a reflection at the end that poisons the next task. The loop amplifies memory errors.
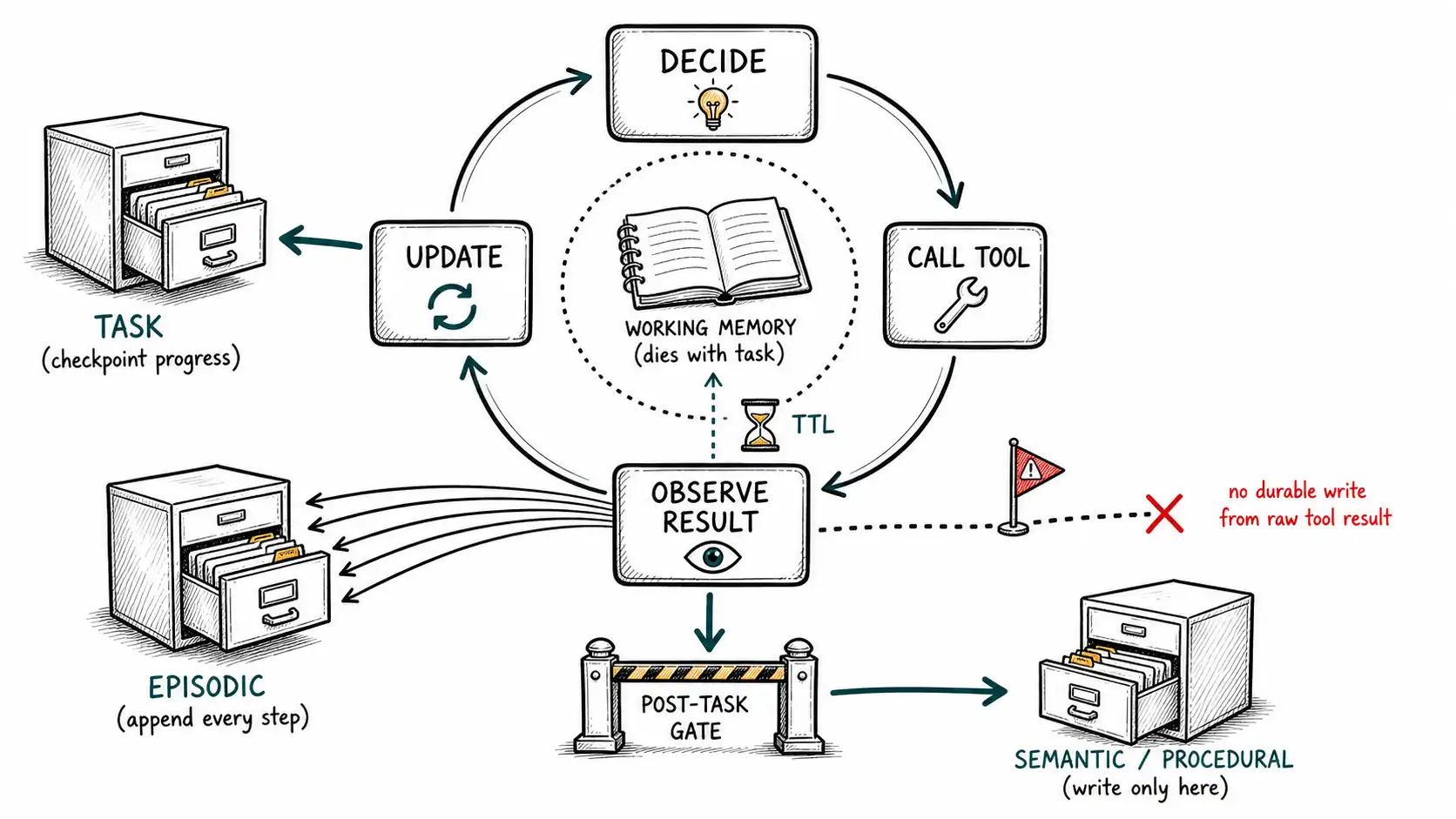
Working memory vs. durable memory inside the loop
The first distinction the loop forces is between two things teams routinely merge: the agent's working memory (the state of the current task, alive only while the task runs) and durable memory (what persists across tasks and sessions). MemGPT made this concrete with an operating-systems metaphor: a small, fast "main context" the model sees directly, and a large "external context" paged in and out under the agent's control. The loop reads and writes working memory constantly and cheaply; it reads and writes durable memory deliberately and rarely.
The failure is to durably persist working memory. An agent debugging a flaky test writes to working memory "hypothesis: the test fails because of a race condition", a perfectly good transient note that guides the next few steps. If that note leaks into durable semantic memory, the agent has now permanently "learned" that this test has a race condition, and it will recall that false fact in future sessions, possibly long after the real bug (a timezone issue, say) was fixed. The hypothesis was working memory. It belonged in the loop and should have died with the task. The discipline is: working memory is the scratchpad; durable memory is the record; a hypothesis is not a fact until it survives the task and clears the write gate.
Here is the loop with that separation made explicit:
class AgentLoop:
def run(self, task: Task, ctx: MemoryContext):
# Durable reads: deliberate, scoped, budgeted (Chapter 5).
working = WorkingMemory()
working.task = ctx.task_memory.load(task.id) or task
working.procedures = ctx.procedural.recall(task) # how to do it
working.facts = ctx.semantic.recall(task, budget=8) # what's true
working.prefs = ctx.preference.recall(task) # defaults
while not working.task.is_terminal():
step = self.model.decide_next_step(working) # reads working mem
if step.is_tool_call:
result = self.tools.call(step.tool, step.args)
# Episodic write: append-only record of what happened.
ctx.episodic.append(Episode.from_action(step, result, task))
# Working-memory update: cheap, transient, NOT persisted.
working.observe(result)
# Task-memory update: durable, but lifecycle-governed.
if result.completes_subtask:
ctx.task_memory.mark_done(task.id, step.subtask_id)
if result.reveals_blocker:
ctx.task_memory.set_blocker(task.id, result.blocker)
# Triggered re-recall: the result may make new memory relevant.
if result.mentions_new_entity:
working.facts += ctx.semantic.recall_about(result.entity,
budget=3)
else:
working.task = step.apply_to(working.task)
self._post_task(task, working, ctx) # consolidation / reflectionThree kinds of write appear in that loop, and they have wildly different governance. The episodic. append is cheap and append-only, record everything that happened, it is the evidence layer (see Generative Agents for the canonical treatment of append-only episodic streams as the foundation for reflection and higher-order memory). The working. observe is not a durable write at all, it mutates in-memory state that dies with the task. The task_memory. mark_done is durable but lifecycle-governed, it changes persistent task state. Only one kind of write is conspicuously absent from the hot loop: there is no semantic. write inside the while. Durable facts and preferences are not written mid-task. They are proposed at the end, in _post_task, where they can be gated calmly. Writing semantic memory inside the loop is how working hypotheses become permanent false facts.
Triggered re-recall: the part chatbots don't have
The line if result. mentions_new_entity: working. facts += ctx. semantic. recall_about(...) is small and easy to miss, and it is one of the things that genuinely distinguishes agent memory. In a chatbot, recall happens once, at the top of the turn, against the user's message. In an agent, the tool results themselves can make new memory relevant mid-task. The agent calls a search tool, the result mentions a customer named ACME, and now the agent should recall what it knows about ACME, which it could not have known to recall at task start, because ACME had not yet entered the picture.
This triggered re-recall is powerful and dangerous in equal measure. Powerful, because it lets the agent bring relevant durable memory to bear exactly when it becomes relevant, which is most of what makes an agent feel competent. Dangerous, because it is also the mechanism by which poisoned tool results inject memory recall: a malicious document returned by a tool can mention an entity specifically to trigger recall of (or a write of) attacker-chosen memory. We will return to this in Chapter 12; for now, note the design rule: triggered re-recall reads durable memory but must never trigger a durable write directly from untrusted tool content. Tool results are episodic evidence, not memory candidates, until they pass the gate.
Write amplification inside loops
A turn-based system writes once per turn, so write volume scales with conversations. An agent in a loop can write many times per task, and tasks can spawn sub-tasks and retries, so write volume scales with agent actions, which is a much larger and lumpier number. This is write amplification, and it has both a cost dimension and a correctness dimension.
The cost dimension is straightforward: if you run an extraction model on every step to propose durable memories, you pay for an extra inference per action, and a long agentic task with fifty steps just multiplied your memory cost fiftyfold. Worse, if those proposals hit a vector store or a write gate that itself calls a model (for contradiction-checking, say), you have a fan-out that can dominate the task's total cost. The fix is to batch durable extraction to task boundaries, propose durable memories once, in _post_task, over the whole episodic record of the task, rather than per step. Episodic appends are cheap and should be per-step; durable derivation is expensive and should be per-task.
The correctness dimension is subtler and worse. If the agent writes a durable memory mid-task and then reads it back later in the same task, it can convince itself of something through repetition within a single run, a feedback loop where a tentative hypothesis, written and re-read, hardens into a "fact" without any external confirmation. This is the agentic version of rumination. An agent debugging in circles can write "the cache is the problem" at step 4, recall it at step 8, write "confirmed: cache is the problem" at step 9 (confirmed by nothing but its own prior note), and emerge from the task with a high-confidence false memory built entirely from self-reference. The episodic log will show the whole sad spiral, which is one more reason to keep it. The defense is the working/durable separation: hypotheses live in working memory, which is not recalled in future tasks, so even a confidently wrong intra-task conclusion dies with the task unless it independently clears the end-of-task write gate against external evidence (see Reflexion for the alternative where only externally-verified trial outcomes are written to durable memory, avoiding this intra-task self-reinforcement trap).
A state machine for memory operations in the loop
It helps to model the loop as a state machine where memory operations are transitions, because then you can reason about which operations are legal in which states. The states are the phases of a task; the transitions are reads and writes; the invariants are the rules that keep memory honest.
| State | Legal memory reads | Legal memory writes | Forbidden |
|---|---|---|---|
| Task start | task, procedural, semantic, preference (budgeted) | none yet | durable writes before any evidence |
| Deciding next step | working memory only | working memory | reading unbounded durable memory each step (cost) |
| After tool result | working; triggered semantic re-recall | episodic (append), task (lifecycle), working | durable semantic/preference write from raw tool content |
| Task success | full episodic record of task | procedural (skill consolidation, gated), semantic (gated) | persisting working hypotheses as facts |
| Task failure | full episodic record of task | reflection / semantic-negative (gated) | blaming a durable fact without provenance |
| Interrupted | task memory (checkpoint) | task (checkpoint state) | losing in-flight task state |
The "Interrupted" row matters more than it looks. Agents get interrupted, the user closes the session, the process is killed, a rate limit trips, a dependency is down. A turn-based system has nothing in flight to lose. An agent fifteen steps into a task has a great deal in flight, and if working memory dies with the process and was never checkpointed to durable task memory, the agent resumes from zero and re-does everything (expensive) or, worse, re-does it differently and produces inconsistent state. So the loop must periodically checkpoint working state into durable task memory, not the transient hypotheses, but the durable progress: which subtasks are done, what was decided, where it is blocked. Resumption is a first-class concern, and it is the subject of Chapter 8.
The memory interface the loop needs
Because memory is touched so often inside the loop, the interface matters as much as the storage. A good agent memory interface makes the cheap operations cheap and the dangerous operations explicit. Compare two designs.
A bad interface exposes one method, remember(text), that does extraction, classification, and writing in one opaque call. The agent calls it whenever it "feels like remembering something, " which is constantly, and every call is a potential durable write with no visible governance. This is the interface that produces the single-store, ungoverned blob from Chapter 2.
A good interface separates the operations by cost and risk, so that the expensive and dangerous ones are syntactically distinct from the cheap and safe ones:
class MemoryContext:
# Cheap, safe, high-volume: always record what happened.
def log_episode(self, episode: Episode) -> None: ...
# Cheap, safe: transient task state, lifecycle-governed.
@property
def task_memory(self) -> TaskMemory: ...
# Budgeted reads: explicit budget so the loop can't read unboundedly.
def recall(self, query: Recall, *, budget_tokens: int) -> list[Memory]: ...
# Expensive, dangerous, RARE: proposes durable memory, returns
# candidates that must pass the gate. Note it returns proposals,
# not confirmations - the gate decides, not the caller.
def propose_durable(self, episodes: list[Episode]) -> list[Candidate]: ...
# The only path to a durable write, and it is auditable.
def commit(self, candidate: Candidate, decision: WriteDecision) -> None: ...Notice that propose_durable takes a list of episodes, not a single utterance, it is designed to be called once per task over the whole record, not once per step. And there is no method that both extracts and commits in one call; extraction proposes, the gate disposes, and commit is a separate, audited act. The interface itself enforces the architecture. An interface that makes durable writing as easy as logging will get durable writes treated like logging, and you are back to the rumor engine.
Reading after writing: cache coherence in the loop
One more loop-specific hazard. Because the agent reads and writes durable memory within overlapping windows, you can get read-after-write incoherence. The agent writes a task update at step 9 ("cutover blocked"), then at step 11 a triggered re-recall reads task memory, does it see the step-9 write? If the durable store is eventually consistent (a common property of vector stores and replicated databases), it might not, and the agent acts on a stale view of state it itself just changed. This is a classic distributed-systems problem wearing an agent costume.
The pragmatic defenses are familiar from databases. Keep working memory as the authoritative source of intra-task state, so the agent reads its own recent writes from the working copy and only treats the durable store as the source of cross-task state. Use read-your-writes consistency for the durable task store specifically (it is small and per-task, so this is cheap). And when consolidating at task end, reconcile the working state against the durable state explicitly rather than assuming they agree. The general rule: within a task, trust working memory; across tasks, trust durable memory; never let an eventually-consistent durable read silently override a write the agent just made.
What this chapter sets up
The loop is the stage on which the rest of the book plays out. Every operation we will study has a place in it: the write gate (Chapter 4) is what commit consults; recall (Chapter 5) is what recall does under its budget; reflection and consolidation (Chapter 6) are _post_task; procedural skills (Chapter 7) are written at task success; task memory (Chapter 8) is the checkpointed durable state that survives interruption; and poisoning defenses (Chapter 12) live precisely at the boundary between a tool result and a durable write, which the loop is careful never to let collapse.
We have established where memory lives in an agent. The next two chapters are the two operations that loop touches most consequentially. We start with the harder of the two, the write, because, as the loop makes vivid, a write made at step 3 is read at step 7, acted on at step 9, and lives in every future task until someone finds it. Reading the wrong memory is a bad moment. Writing the wrong memory is a bad future.
Internal map
For the larger argument, keep this chapter connected to memory systems for agents, Memory Systems for Agents, Agents That Actually Work, and agentic workflows.