A Vision Answer Is Not Evidence
> **Working claim:** A model's description, reading, or transcription of a non-text input is a *claim*, not a fact.

Working claim: A model's description, reading, or transcription of a non-text input is a claim, not a fact. It becomes usable evidence only when an independent process, a structured re-extraction, a grounding to a source region, a cross-check against authoritative data, or agreement across redundant views, confirms it. Systems that act on unverified vision answers are acting on fluent guesses that happen to be right most of the time.
An incident, told as evidence
Start with an incident, because this chapter's claim is abstract until it costs money. A procurement-automation product read supplier invoices with a vision-language model and posted approved totals into an accounting system. The prompt asked the model to return the invoice total as JSON. It did, fluently, in clean structured form, thousands of times a day, and it was right the overwhelming majority of the time. One invoice from a supplier whose template put the total in an unusual place, in a smaller font, next to a larger "subtotal before discount, " caused the model to return the subtotal as the total. The number was plausible, the JSON was valid, the confidence the model expressed (when asked) was high, and the system posted it. The discrepancy surfaced weeks later in a reconciliation, after the payment had gone out.
Nothing in that pipeline was lying. The model produced its best reading. The JSON schema validated. The number was a real number that appeared on the invoice. The failure was not in any component; it was in the epistemics of the system. The team had treated a model's reading of an image as a fact about the world, when it was only a claim about an image, a claim with no independent confirmation, no tie to a specific region of the document, and no cross-check against anything that could have disagreed. The number was valid JSON describing a guess.
This is the chapter that names the rule the whole book is organized around. In a text system, you can often take the model's output as the output, because the input was already the ground truth and the model's job was to transform it. In a multimodal system, the model's output is a measurement of a signal, and an unverified measurement is not evidence. The GPT-4V system card is explicit that the model produces confident, detailed errors; MMMU-Pro showed that those errors multiply precisely when shortcuts are removed. Building on top of such a component without verification means building on confident guesses.
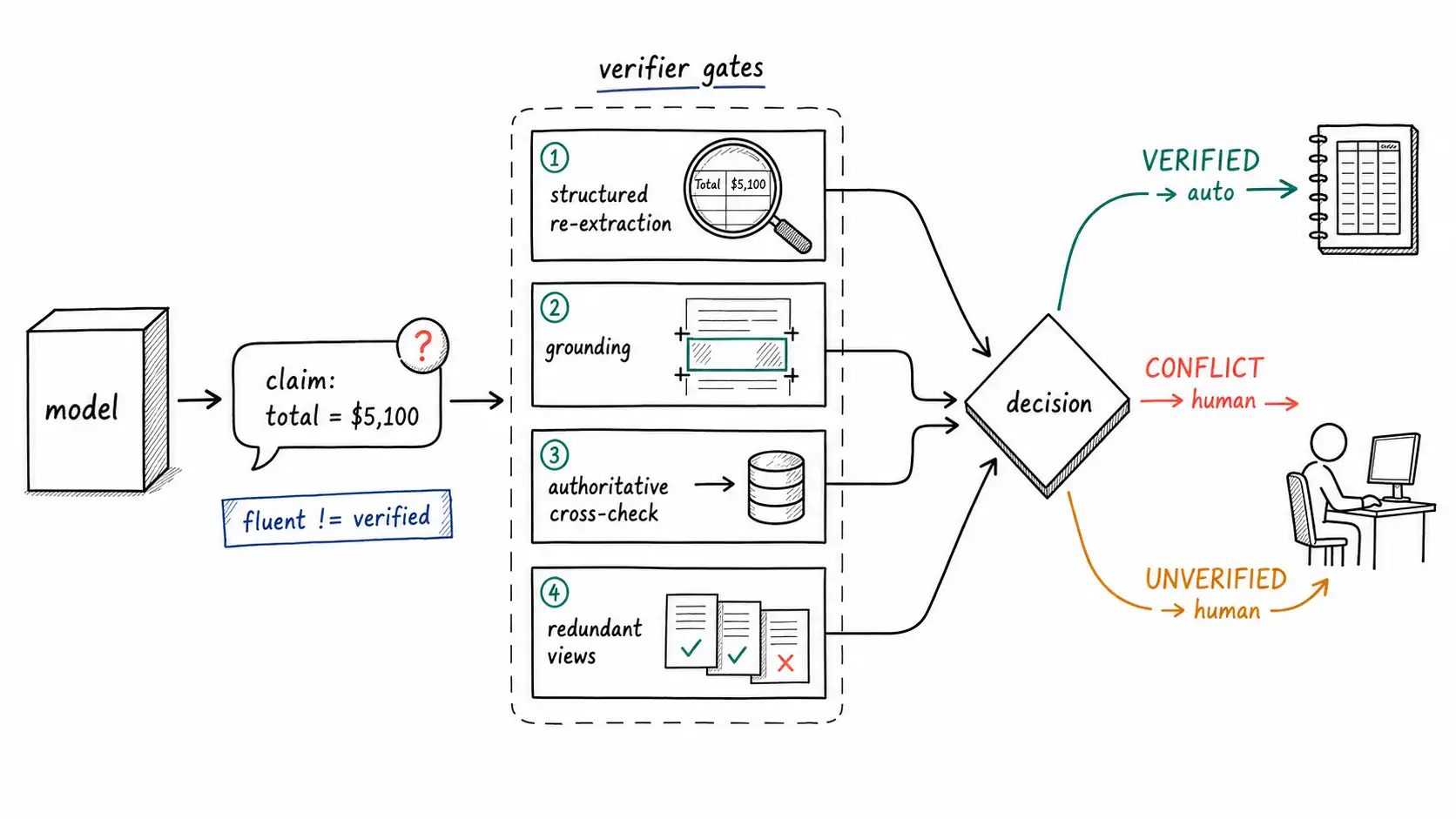
Why the model cannot be its own witness
The obvious objection is: why not just ask the model how confident it is, or have it double-check itself? Both fail, for the same reason, and the reason is worth understanding because it disqualifies a whole family of tempting shortcuts.
A model's self-reported confidence about a perceptual reading is not calibrated to whether the detail survived ingestion. Recall Chapter 1: the relevant pixels may have been destroyed by resizing before the model ever reasoned. The model is not reasoning about the original image; it is reasoning about a compressed projection, and it has no privileged channel telling it "the total was in 6-point font and got blurred away." So when you ask "how confident are you that the total is $5,100?", you are asking the model to introspect on information it never had, and it answers from the same fluent prior that produced the reading, high confidence, because $5,100 is a perfectly plausible total. Confidence and accuracy decouple exactly where you need them coupled.
Self-checking has the same defect."Look again and verify the total" sends the same compressed projection through the same model that produced the error, often producing the same error with added conviction. Self-consistency across multiple samples helps a little, if three independent samples disagree, that is a useful signal, but agreement among samples drawn from the same blind projection can be agreement on the same mistake. The model cannot be its own witness because the witness and the suspect share the same compressed eyes. Verification has to come from outside the model's perceptual path.
The four kinds of external verification
There are exactly four families of external verification, and a mature multimodal system uses whichever ones its object of truth admits. They are not alternatives to each other so much as a toolkit; the strongest systems stack them.
1. Structured re-extraction (a second, different reader). Run a deterministic or differently-built extractor over the same region and compare. For the invoice, this means an OCR engine plus a layout parser independently locating the "total" field and reading its digits, then comparing that number to the model's claimed number. Two readers built on different principles rarely make the same mistake on the same input; disagreement flags the input for review. The point is not that OCR is more accurate than the model, often it is not, but that it is independently wrong, and independence is what verification needs.
2. Grounding to a source region. Require the model (or the pipeline) to return where the claim came from, the bounding box, the page, the audio offset, the frame. A claim you can point at is a claim a human can check in one glance, and a claim that cannot be localized is automatically suspect. Grounding turns "the total is $5,100" into "the total is $5,100, read from this box on page 1, " which a reviewer can confirm or reject in seconds, and which an automated check can confirm by re-OCRing just that box. We devote a full chapter to grounding; here it is one of the four verifiers.
3. Cross-check against authoritative data. Where an external source of truth exists, use it. The chart blind spot dissolves when the underlying dataset is available, extract from the data, not the picture. The invoice total can be checked against the sum of the line items the system also extracted (a consistency check the procurement team did not run); the part number against the parts database; the transcribed dosage against the formulary's allowed range. This is the most powerful verifier when it is available, because it checks against the world rather than against another reading of the same signal.
4. Redundant views and agreement. When the same fact appears in multiple places, multiple frames of a video, multiple photos of the same object, the transcript and the slide and the chat in a meeting, agreement across views is evidence and disagreement is a flag. The video door-damage case is recoverable this way: the audio said "the big dent on the driver's door, " and a frame near that timestamp showed it; the two views agree, and that agreement is worth more than either alone.
A verification contract in code
The architectural move is to stop returning a bare answer and start returning a verified result whose type makes the verification status impossible to ignore. The result carries the claim, the evidence that supports or contradicts it, and a disposition.
from dataclasses import dataclass, field
from enum import Enum
class Disposition(str, Enum):
VERIFIED = "verified" # passed independent checks
UNVERIFIED = "unverified" # no independent confirmation available
CONFLICT = "conflict" # verifiers disagree -> human review
OUT_OF_ENVELOPE = "ooe" # input failed the quality gate
@dataclass
class Grounding:
page: int | None = None
bbox: tuple[float, float, float, float] | None = None # x,y,w,h, normalized
audio_offset_ms: int | None = None
frame_index: int | None = None
@dataclass
class VerifiedClaim:
field: str # "invoice_total"
value: str # the model's claim, e.g."5100.00"
grounding: Grounding
checks: dict[str, str] = field(default_factory=dict) # verifier -> outcome
disposition: Disposition = Disposition. UNVERIFIED
@property
def usable_without_human(self) -> bool:
return self.disposition == Disposition. VERIFIED
def verify_invoice_total(claim_value: str, doc) -> VerifiedClaim:
g = locate_field(doc, "invoice_total") # layout parser finds the box
claim = VerifiedClaim(field="invoice_total", value=claim_value, grounding=g)
# Verifier 1: independent OCR of just the grounded box.
ocr_value = ocr_region(doc.page_image(g.page), g.bbox)
claim.checks["ocr_region"] = "match" if money_eq(ocr_value, claim_value) else f"ocr={ocr_value}"
# Verifier 3: consistency - does it equal subtotal + tax - discount?
derived = doc.fields["subtotal"] + doc.fields["tax"] - doc.fields["discount"]
claim.checks["line_item_consistency"] = "match" if money_eq(derived, claim_value) else f"derived={derived}"
matches = sum(1 for v in claim.checks.values() if v == "match")
if g.bbox is None:
claim.disposition = Disposition. UNVERIFIED # could not even ground it
elif matches == len(claim.checks):
claim.disposition = Disposition. VERIFIED
elif matches == 0:
claim.disposition = Disposition. CONFLICT # everything disagrees
else:
claim.disposition = Disposition. CONFLICT # partial -> human looks
return claimThe subtotal-as-total incident is a non-event under this contract. The model claims 5100.00; the line-item consistency check derives the real total of 5780.00 from fields the system already extracted; the checks disagree; the disposition becomes CONFLICT; the system routes to human review instead of posting. No better model was required, only the refusal to treat the model's reading as evidence before an independent process agreed with it.
The disposition is the product
Notice what usable_without_human does: it makes the default for an unverified or conflicting claim "a human must look, " and the privilege of automatic action something a claim has to earn by passing independent checks. This inverts the demo-driven default, where everything is auto-actioned unless something obviously breaks. The inversion is the entire safety posture of a multimodal system, and it is why this type lives at the center of the architecture rather than at the edge.
This also gives you the honest dial for the perennial product question, "how much can we automate?" The answer is not a guess; it is a measured quantity: the fraction of real inputs whose claims reach VERIFIED. If 80% of invoices verify cleanly against both OCR-of-region and line-item consistency, you automate 80% and route 20% to review, and you know which 20% and why. The procurement team, before the incident, had an automation rate of 100% and a verification rate of 0%, and the difference between those two numbers was the incident waiting to happen. The benchmarks reinforce the need for this honesty: DocVQA and ChartQA report accuracies well below 100% even for strong models on curated data, and MM-Vet shows integrated tasks are harder still, which means the unverified-claim rate on your messier real data is high enough that auto-acting on all of it is a decision to absorb its error rate silently.
When verification is impossible, say so
Not every object of truth admits external verification."Describe the mood of this photograph for an alt-text caption" has no structured re-extraction, no authoritative dataset, and no crisp grounding; it is inherently a judgment, and a wrong judgment is low-stakes. That is fine, and the discipline does not demand you invent a verifier where none exists. What it demands is honesty about the disposition: a claim that cannot be verified is UNVERIFIED, and an UNVERIFIED claim must not be used as though it were VERIFIED for a high-stakes action. The alt-text caption ships as unverified, because being occasionally wrong about mood is acceptable. The invoice total does not ship as unverified, because being occasionally wrong about money is not. The classification of stakes, which the MODAL framework's "Object of truth" question forces you to make explicit, is what decides whether an unverifiable claim is acceptable or a reason not to automate at all.
This is also the honest answer to the use cases where teams want magic: "the model can just look at the X-ray and tell us." If there is no independent verifier and the stakes are high, the correct architecture is not full automation with a disclaimer; it is decision support, where the model's claim is presented to a qualified human alongside its grounding and the human is the verifier and the actor. The model's value there is real, it surfaces, prioritizes, and explains, but it is not evidence, and the system must be built so that nobody, including the model, mistakes it for evidence.
The principle restated as architecture
The chapter reduces to one architectural commitment, which we will lean on in every chapter that follows: the unit of output in a multimodal system is a verified claim, not an answer. A verified claim knows what it asserts, where in the source it came from, which independent checks it passed or failed, and therefore whether it may be acted on without a human. This is more work than returning a string, and the extra work is the difference between the procurement team before the incident and after it. The reframe from Chapter 1, from "can it see?" to "can we prove what it saw?", is, concretely, this: replace every place your code returns a bare model reading with a place that returns a VerifiedClaim, and let the disposition, not the fluency, decide what happens next.
Chapter summary
A model's reading of an image, document, chart, or audio clip is a claim about a signal, not a fact about the world, and an unverified claim is a fluent guess that happens to be right most of the time, which is exactly the failure mode that produces a confident wrong invoice total posted to a ledger. The model cannot be its own witness: its self-reported confidence is uncalibrated to whether the relevant detail survived the lossy projection it never saw past, and self-checking re-runs the same compressed input through the same model. Verification must come from outside the model's perceptual path, and there are four families of it, structured re-extraction by an independently-built reader, grounding to a source region a human or machine can re-check, cross-check against authoritative data (the strongest, where available), and agreement across redundant views. Encode this by making the unit of output a VerifiedClaim that carries the claim, its grounding, the outcome of each verifier, and a disposition (verified, unverified, conflict, out-of-envelope), with automatic action a privilege earned by verification rather than a default. The disposition is the product: the verified fraction is the honest automation rate, and the gap between automation rate and verification rate is the incident waiting to happen. Where no verifier exists and stakes are low, ship as honestly unverified; where no verifier exists and stakes are high, build decision support with a human as the verifier, never silent automation. The whole book reduces to one commitment: the unit of output is a verified claim, not an answer. This chapter builds on the blind spots catalogued in Every Modality Brings Its Own Blind Spots; the next movement turns to the model architecture underlying these claims: Encoders, Contrastive Learning, and Cross-Modal Alignment.