Encoders, Contrastive Learning, and Cross-Modal Alignment
> **Working claim:** You do not need to train a vision-language model to build with one, but you do need an accurate mental model of how machines come to associate an image with words.

Working claim: You do not need to train a vision-language model to build with one, but you do need an accurate mental model of how machines come to associate an image with words. That mental model, encoders projecting different signals into a shared space, learned by pulling matching pairs together and pushing mismatched pairs apart, explains both why these systems are powerful and exactly where they will mislead you.
Why a builder needs this chapter
This is not a chapter about training models, and you will not be asked to derive a loss function. But every practical decision in the later chapters, when to use cross-modal retrieval, why captions are not images, why OCR text is not document understanding, why a "similar-looking" product can be the semantically wrong one, rests on understanding two mechanisms: how a single modality becomes a vector (encoding), and how two modalities come to share a coordinate system (alignment). Get these two ideas right and the rest of the book's failure modes become predictable rather than surprising. Get them wrong and you will reach for cross-modal search where you need structured extraction, or trust a similarity score as if it were a verdict, which Chapter 5 will show is its own category of mistake.
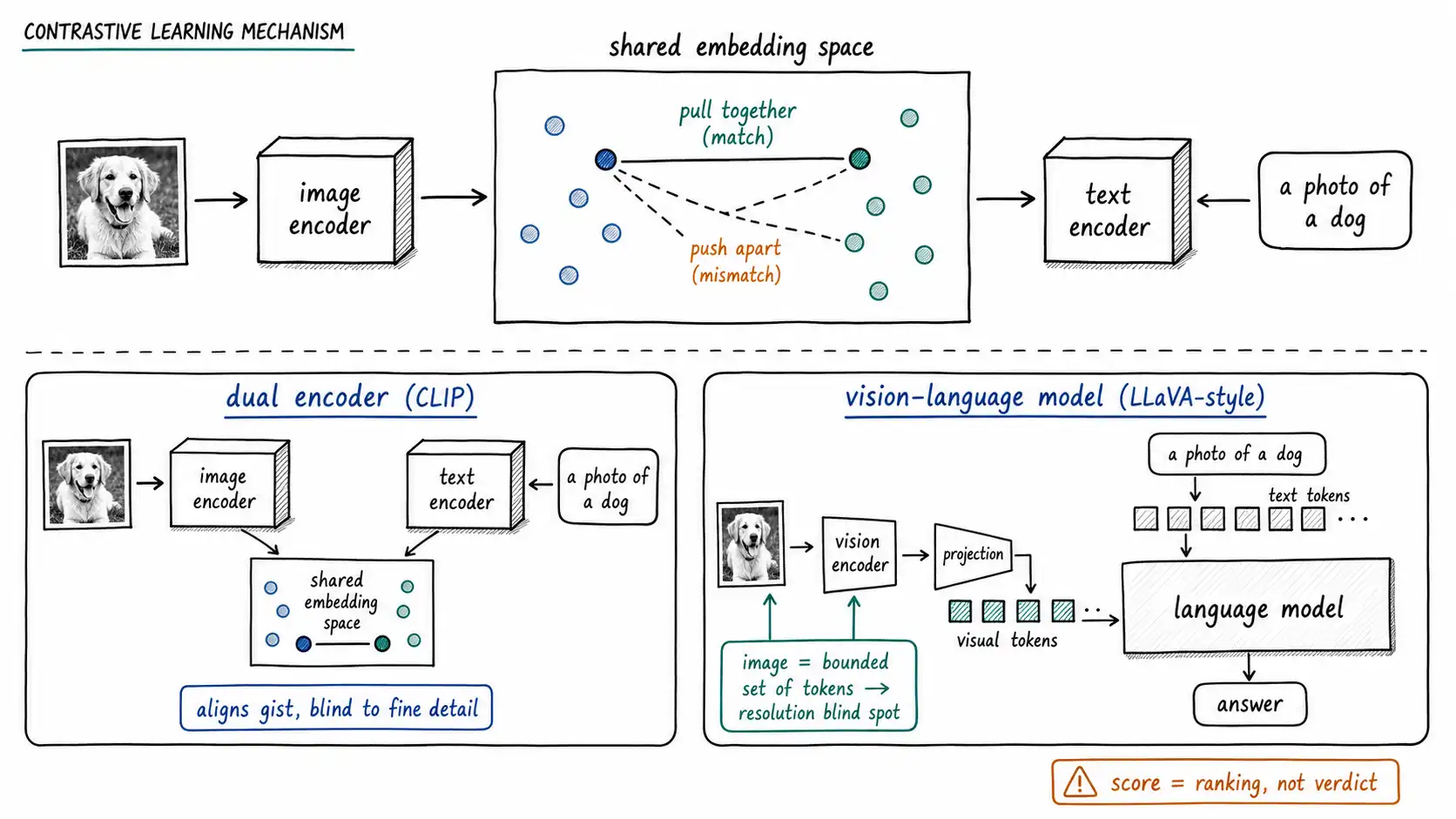
Encoding: turning a signal into coordinates
An encoder is a function that takes a signal, an image, an audio clip, a span of text, and produces a fixed-length vector, an embedding, that is meant to place "similar" inputs near each other and "different" inputs far apart. The crucial word is meant: what counts as similar is entirely determined by what the encoder was trained to care about, and that training objective is the source of both its usefulness and its blind spots.
For text, the encoder reads tokens and produces a vector that captures something like topical and semantic content. For images, the encoder, historically a convolutional network, now usually a Vision Transformer, splits the image into patches, processes them, and produces a vector that captures the visual content the training objective rewarded. For audio, the encoder turns the waveform into spectral features and processes those into a vector. In every case the output is the same shape of object: a point in a high-dimensional space. And in every case the encoder has thrown away everything the objective did not reward it for keeping. An image encoder trained to recognize objects keeps "there is a dog" and discards "the dog's collar tag reads "Max", " because the tag was never part of what it was scored on. This is the embedding-level restatement of Chapter 2's image blind spot: small task-irrelevant detail is not just lost in resizing, it is actively discarded by an encoder optimizing for gist.
Contrastive learning and CLIP: how words and pixels meet
The breakthrough that made general-purpose vision-language systems practical was learning to encode images and text into the same space, so that an image of a dog and the text "a photo of a dog" land near each other. CLIP is the canonical example and the one worth understanding in detail, because its design is the intuition behind almost everything downstream.
CLIP trains two encoders at once, one for images, one for text, on a very large set of image-caption pairs scraped from the web. The training objective is contrastive: take a batch of, say, hundreds of image-text pairs, embed all the images and all the texts, and then arrange the learning so that each image's embedding is closest to its own caption's embedding and far from every other caption in the batch, and symmetrically for each caption. Pull the matching pair together; push the mismatched pairs apart. Repeat across hundreds of millions of pairs. The result is a shared embedding space where a meaningful chunk of visual and textual semantics line up: you can embed a brand-new image and a brand-new sentence the model never saw and measure how well they match by the proximity of their vectors.
Two consequences of this design matter enormously for builders:
First, CLIP gives you zero-shot cross-modal capability. Because images and text share a space, you can classify an image without training a classifier: embed the image, embed candidate label texts like "a photo of a hard hat" and "a photo of a bare head, " and pick the nearest. You can search images with text queries, search text with images, and rank either against the other. This is the engine of multimodal retrieval in Chapter 11.
Second, and just as important, CLIP learned from captions, which describe the gist of images, so it is excellent at gist-level alignment and indifferent to everything captions usually omit. Captions say "a dog in a park, " not "the dog's tag reads Max" or "the third bar of the chart is at 47." So CLIP-style alignment inherits, at the representation level, exactly the blind spots Chapter 2 named: it aligns the describable gist and is blind to the fine, the exact, and the textual-within-the-image. Captions are not images, and an alignment learned from captions is an alignment to caption-level meaning, not to pixel-level fact. This is why CLIP-based retrieval can confidently return a visually-and-topically similar product that is the wrong size, wrong model number, or wrong color variant, the distinctions captions rarely make are the distinctions the embedding never learned.
From alignment to conversation: vision-language models
CLIP aligns; it does not talk. To get a system that looks at an image and answers questions about it in free text, you connect a vision encoder to a language model. Flamingo was an influential early architecture: take a powerful frozen language model, take a frozen vision encoder, and train a bridge between them, cross-attention layers that let the language model attend to the encoded image, so that the language model can condition its generation on visual features and answer questions, with very few examples.
LLaVA made the recipe widely reproducible and exposed its structure clearly. The architecture is almost embarrassingly simple to describe: a CLIP-style vision encoder produces image features, a small learned projection maps those features into the language model's token-embedding space (so the image becomes, in effect, a sequence of "visual tokens" the language model can read alongside text tokens), and the whole thing is fine-tuned on instruction-following data, image-question-answer triples, so that it learns to respond helpfully rather than merely describe. The LLaVA project page documents this visual-instruction-tuning recipe and its results.
This structure explains a great deal about how the systems behave in production:
- The image becomes a bounded set of tokens. The projection produces a fixed (and not enormous) number of visual tokens. This is the architectural origin of the resolution blind spot: fine detail that does not survive into those tokens is unavailable to the language model no matter how cleverly you prompt. It is also the origin of the cost model in Chapter 14: images cost tokens, and higher-resolution or tiled inputs cost more tokens.
- The language model does the reasoning. Once the image is visual tokens, the reasoning is the language model's reasoning, with all its strengths (fluent synthesis, instruction-following) and weaknesses (confident fabrication, weak exact arithmetic). The model's eloquence about an image is the language model's eloquence; its accuracy about the image is bounded by what the visual tokens carried.
- Instruction tuning shapes behavior, not perception. Fine-tuning on instruction data makes the model helpful and well-formatted, which is exactly what makes its errors so dangerous: a well-instruction-tuned model gives a confident, nicely structured wrong answer. The tuning improved the wrapping, not the eyes.
Binding more than two modalities
CLIP binds images and text. Production systems often have audio, video, and depth too, and a natural question is whether everything can share one space. ImageBind showed a clever and instructive answer: you do not need paired data between every pair of modalities. If you have image-text pairs, image-audio pairs, image-depth pairs, and so on, always pairing through images, you can learn a single joint space in which audio and text also end up aligned even though you never trained on audio-text pairs directly, because images act as the binding hub. This "emergent" alignment is genuinely useful: it enables, for instance, retrieving images from an audio query.
For a builder, the practical lessons from ImageBind are two. The capability, one space for many modalities, enabling any-to-any retrieval: is real and worth knowing exists. But the binding-through-images design means the alignment between two non-image modalities is indirect and weaker than a directly-trained pair, so cross-modal matches that route through the hub are noisier and need the verification discipline of Chapter 3 even more, not less. A shared space is a convenience for retrieval and ranking; it is never, by itself, a verifier.
The capability comparison table
These mechanisms produce distinct task types that teams routinely conflate. Naming them apart is half the battle.
| Task | What it does | Mechanism | What it is NOT |
|---|---|---|---|
| OCR | Reads characters from an image | Specialized text-detection + recognition | Not understanding of layout or meaning |
| Image captioning | Produces a short gist description | Image encoder → text decoder | Not extraction; omits the specific and exact |
| CLIP-style retrieval | Ranks images/text by shared-space proximity | Dual encoders, contrastive | Not a verdict; gist-level, blind to fine distinctions |
| VQA (visual QA) | Answers a question about one image | Vision-language model | Not measurement; bounded by visual tokens |
| Document QA | Answers a question about a document image | VLM (often + OCR + layout) | Not guaranteed structure-faithful (Ch. 6-7) |
| Multimodal RAG | Retrieves then answers over mixed media | Retrieval + VLM | Not grounded unless provenance is preserved (Ch. 8) |
The table's purpose is to stop sentences like "we'll use the multimodal model to do OCR." A vision-language model can read text in an image, but that is VQA over text, not OCR, and for high-stakes character-exact reading a purpose-built OCR engine (verified per Chapter 3) is usually the right tool. Likewise "CLIP can tell us if the product matches" confuses a ranking signal with a verdict. Each row is a different mechanism with a different reliability profile, and choosing the right one for your object of truth is most of good multimodal design.
A minimal cross-modal retrieval sketch
To make the shared-space idea concrete, and to set up Chapter 11, here is the smallest honest version of CLIP-style retrieval, written to foreground provenance rather than to impress.
import numpy as np
def embed_image(img) -> np.ndarray:
v = clip_image_encoder(img) # shared-space vector
return v / np.linalg.norm(v) # normalize for cosine via dot product
def embed_text(text: str) -> np.ndarray:
v = clip_text_encoder(text)
return v / np.linalg.norm(v)
def index_catalog(products) -> list[dict]:
"""Each indexed item keeps provenance, not just the vector."""
index = []
for p in products:
index.append({
"vector": embed_image(p.image),
"product_id": p.id, # provenance: what this vector IS
"image_hash": p.image_hash, # so a result ties back to a source
"caption": p.caption,})
return index
def search_by_text(query: str, index, k=5):
q = embed_text(query)
scored = sorted(index, key=lambda it: float(q @ it["vector"]), reverse=True)
# The score is a RANKING signal, not a confidence of correctness.
return [{"product_id": it["product_id"],
"score": float(q @ it["vector"]),
"image_hash": it["image_hash"]} for it in scored[:k]]Two deliberate choices encode the chapter's lessons. Every indexed vector carries its provenance (product_id, image_hash), because Chapter 8 will insist that a retrieval result must point back at its source. And the docstring on search_by_text says out loud that the score is a ranking signal, the thing Chapter 5 is entirely about not over-trusting. A high cosine similarity means "this is among the most caption-level-similar items, " not "this is the right item, " and treating the former as the latter is the embedding-space version of treating a vision answer as evidence.
What this mental model buys you
With encoding and alignment in hand, several later decisions stop being mysterious. You will understand why cropping a region before sending it to a vision-language model recovers detail (you are giving the encoder more pixels per unit of the thing you care about, so more of it survives into the visual tokens). You will understand why a CLIP retrieval over product photos needs a reranker and a metadata filter (the shared space ranks by gist; the exact variant must be pinned by structured attributes the embedding never learned). You will understand why "just let the multimodal model read the document" is a reasoning step that still needs OCR and layout underneath it for anything character-exact. And you will understand the boundary the next chapter polices: a shared embedding space is a beautiful instrument for finding candidates, and a terrible instrument for deciding truth, because proximity in a space learned from captions is similarity of gist, and gist is not fact.
Chapter summary
Builders do not train vision-language models but must understand two mechanisms to use them well: encoding (turning a signal into a fixed vector that keeps what the training objective rewarded and discards everything else) and alignment (placing two modalities in a shared space). CLIP learns a shared image-text space by contrastive training on image-caption pairs, pulling matching pairs together, pushing mismatches apart, which yields powerful zero-shot cross-modal retrieval and, because it learned from gist-level captions, inherits the blind spots of captions: it aligns the describable and ignores the fine, exact, and textual-within-the-image, so captions are not images. Vision-language models like Flamingo and LLaVA connect a vision encoder to a language model through a projection that turns the image into a bounded set of visual tokens, which is the architectural origin of both the resolution blind spot and the per-image token cost, and means the model's eloquence is the language model's eloquence while its accuracy is bounded by what those tokens carried; instruction tuning improves the wrapping, not the eyes. ImageBind binds many modalities through images as a hub, enabling any-to-any retrieval but with weaker indirect alignment between non-image pairs. The capability table separates OCR, captioning, CLIP retrieval, VQA, document QA, and multimodal RAG, which teams routinely conflate, each with a different reliability profile. A minimal retrieval sketch keeps provenance on every vector and labels the similarity score as a ranking signal, not a verdict, the precise boundary the next chapter is about. This chapter follows A Vision Answer Is Not Evidence; the next chapter explores Joint Embedding Spaces and Their Limits.