The Use Case Field Guide
> **Working claim:** The disciplines in this book, name the modality and its blind spot, define the object of truth, preserve derived artifacts with provenance, ground every claim, verify before acting, and evaluate by slice, are not abstract.

Working claim: The disciplines in this book, name the modality and its blind spot, define the object of truth, preserve derived artifacts with provenance, ground every claim, verify before acting, and evaluate by slice, are not abstract. They instantiate differently for each product, and the fastest way to design a multimodal feature well is to start from the playbook for its closest neighbor. Each playbook below is a compression of the whole book aimed at one shape of problem.
How to read a playbook
Each playbook below follows the same five questions, the MODAL framework applied, but the answers differ sharply, which is the point: the same discipline yields different architectures for different problems. The five questions are: what does multimodal genuinely help with here; what does it not solve (the trap); what ingestion does the object of truth demand; how do you evaluate it honestly; and what are the characteristic failure modes and the privacy or safety concerns. Read your closest neighbor first, then the ones adjacent to it, because real products are usually combinations (a support assistant that reads screenshots and listens to voice notes is the support playbook plus the audio playbook, with their blind spots compounding per Chapter 2).
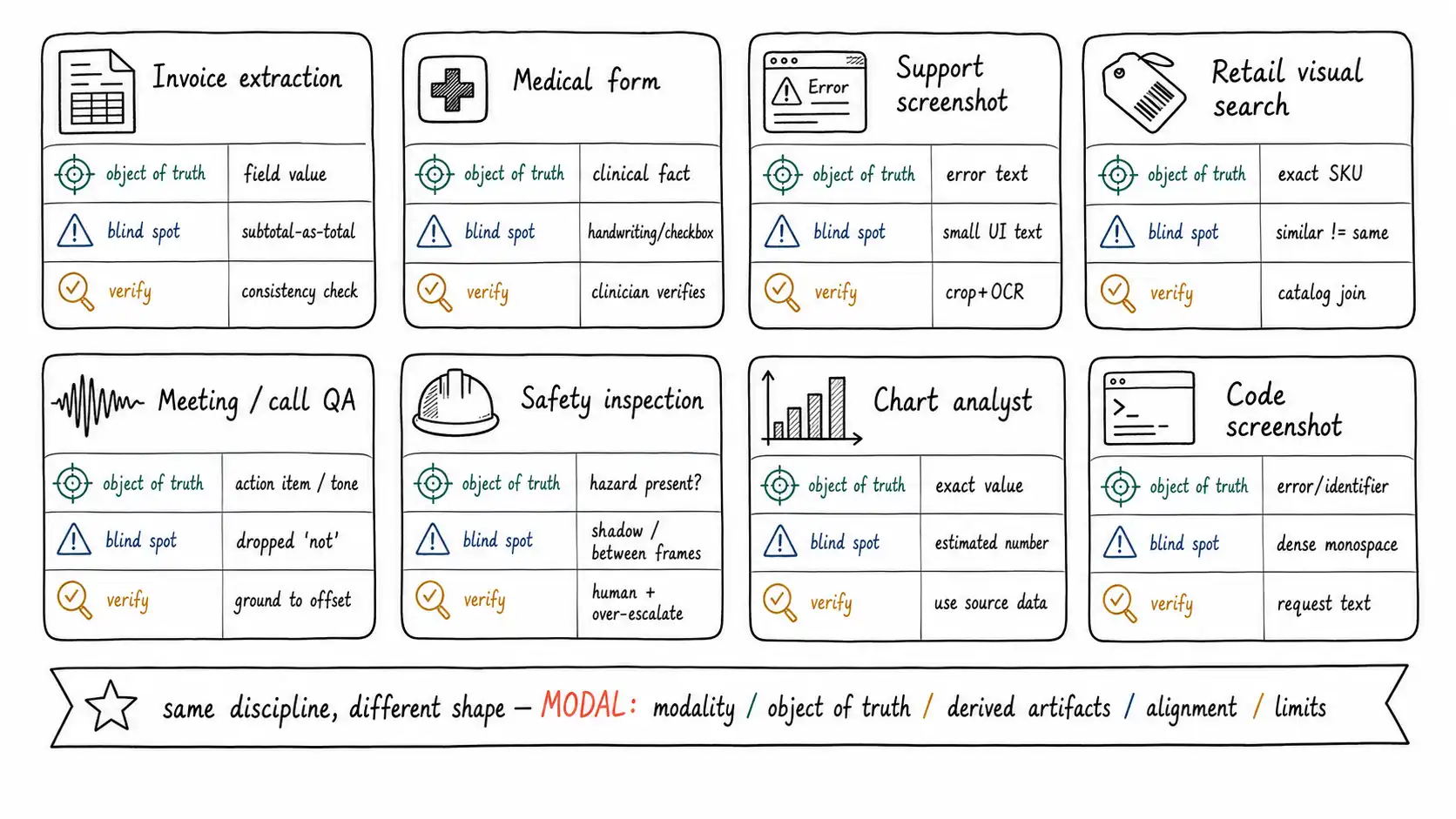
Invoice and document extraction
Helps with: turning unstructured invoices, statements, and forms into structured fields at volume, replacing manual data entry for the clean majority. Does not solve: the long tail of unusual templates, and it does not understand the document, it extracts fields, and field accuracy is far below the OCR accuracy it is tempting to report (Chapter 7). Ingestion: layout-aware OCR plus high-resolution page-image crops, the document schema of Chapter 6 (text spans with boxes, table cells with merged-cell spans, key-value pairs, page supersession), and crops for any stamps or signatures. Evaluation: per-field, per-template accuracy with the worst-template slice as the launch gate (Chapter 12); internal-consistency verification (subtotal + tax = total) as both a quality check and an automation gate; track the verified fraction as the honest automation rate. Failure modes: subtotal-as-total and misattribution at 100% character accuracy; superseded pages; the new-customer-template cliff. Privacy: invoices and statements carry bank details, tax IDs, and personal data, minimize, classify sensitivity, and make deletion reach the embeddings. The benchmark to study is DocVQA, because it scores the document-understanding layer this product lives or dies on.
Medical form review
Helps with: triaging and pre-filling structured data from referrals, intake forms, and lab reports so clinicians spend less time on transcription. Does not solve: diagnosis, and it must never be allowed to, this is decision support, with the clinician as the verifier and the actor (Chapter 3, Chapter 15). Ingestion: the document pipeline plus explicit handwriting flagging (Chapter 7), checkbox-state detection (a checked vs unchecked box can be the entire clinical fact), and crops of any embedded photographs. Evaluation: harm-weighted error with strong asymmetry (a missed allergy is catastrophic; a false flag is a clinician's two-second dismissal), calibrated abstention, and grounding accuracy because every extracted clinical fact must point at the line that states it. Failure modes: handwritten dosages misread; the crossed-out-and-amended field (the "no known allergies → penicillin" case); checkbox state inverted. Privacy: this is special-category data under GDPR Article 9; consent, sensitivity tagging, and the external-model policy gate are mandatory, not optional, and the original may need to stay inside your boundary entirely.
Customer-support screenshot assistant
Helps with: understanding the screenshot a user pastes, the error dialog, the UI state, the billing screen, to resolve tickets faster. Does not solve: reading small UI text reliably from a full-frame screenshot (the resolution blind spot), and it confuses modalities (a screenshot of a PDF is a document, not a photo). Ingestion: modality detection and reroute (Chapter 1), a localize-then-crop pass to read small error text at high resolution (Chapter 14), and OCR of UI text rather than a gist description. Evaluation: task resolution accuracy sliced by app/screen type and resolution; perception eval on the specific error text, separate from reasoning about the fix. Failure modes: misreading an error code or a digit in an order number; describing the screen instead of reading its text; the 30x cost surprise from full-resolution screenshots. Privacy: screenshots routinely contain other tabs, names, and account data outside the relevant region, crop and redact at ingest.
Retail visual search and catalog enrichment
Helps with: finding visually similar products from a photo (discovery) and auto-tagging catalog images with attributes (enrichment). Does not solve: finding the exact same product, because similar is not same, the embedding space is blind to SKU, size, version, and region (Chapter 5). Ingestion: CLIP-style image embeddings for recall, plus the structured catalog record for the decision; for enrichment, vision attributes verified against the known product taxonomy. Evaluation: for search, exact-match rate and "right product in top-k" separately from "visually similar in top-k"; for enrichment, per-attribute accuracy against catalog ground truth. Failure modes: wrong size/SKU returned with high confidence; discontinued or wrong-region items surfaced; enrichment hallucinating attributes captions never specify. Architecture rule: candidates from the embedding space, decision from structured attributes, always. MM-Vet's integrated-capability framing is the reminder that search-plus-decision is two capabilities, not one.
Meeting intelligence and call-center QA
Helps with: summaries, action items, and quality scoring from recorded calls and meetings. Does not solve: the inverting word (a dropped "not"), and a transcript-only system cannot hear tone, so it cannot tell a calm resolution from a barely-contained escalation (Chapter 9). Ingestion: the timestamped, diarized transcript schema with token-level confidence, decision-bearing-token flagging (negations, numbers, names), and preserved non-speech events; keep the audio, not just the transcript. Evaluation: for meeting intelligence, action-item accuracy with grounding to the audio offset, and error specifically on decision-bearing tokens rather than WER; for call-center QA, agreement with human scorers sliced by accent and noise, and explicit measurement of whether emotional/escalation cues are captured. Failure modes: the Friday-migration inversion; misattributed action items (wrong speaker); QA scoring that misses an escalation because the words were polite. Privacy: recordings capture every voice in the room, including non-consenting parties; consent and retention are load-bearing. Whisper is the transcription anchor, but the whole point is that transcription is the start, not the system.
Safety inspection from photos and video
Helps with: surfacing and prioritizing potential hazards from inspection photos and walk-through videos, so human inspectors focus where it matters. Does not solve: the final safety verdict, this is high-stakes decision support with deliberate over-escalation (Chapter 15). Ingestion: for video, audio/shot-guided dense sampling so a short hazard is not skipped, temporal-order preservation for before/after causality (harness-before-climb), and high-resolution crops for small hazards. Evaluation: harm-weighted with extreme asymmetry, a missed hazard is the catastrophic error, calibrated abstention, and temporal-causality tests. Failure modes: the hazard in shadow read as absent; the event between video samples; reversed causality; a confident "all clear" that is a fluent guess. Safety rule: never auto-close on a model's say-so; ground every finding to a frame and a box for the inspector; tune thresholds toward flagging. The GPT-4V system card's documented spatial and counting weaknesses are directly relevant where the object of truth is a count of safety violations or a precise spatial relation.
Chart and dashboard analyst
Helps with: explaining trends and summarizing dashboards in natural language. Does not solve: reading exact values from a rendered chart, those are estimates and are confidently wrong (Chapter 2, Chapter 5). Ingestion: wherever the underlying data exists, extract from the data, not the picture, which is exact and costs zero vision tokens; only fall back to reading the rendered figure when the data is genuinely unavailable, and then treat every read value as an unverified claim. Evaluation: ChartQA-style, separating trend/description accuracy (often good) from precise-value accuracy (often poor), and never reporting the former as if it were the latter. Failure modes: the bar read as 42 instead of 47; a computed total built on misread values; a confident narrative about a misread trend. Architecture rule: for any numeric claim, prefer source data; if reading the image, verify and label the value as estimated.
UI and code screenshot debugging assistant
Helps with: reading a screenshot of an error, a stack trace, or a UI to suggest fixes. Does not solve: reliably reading dense code or long identifiers from a screenshot, small monospace text is exactly the resolution blind spot. Ingestion: OCR of the code/error region at high resolution (crop first), and where possible ask the user for the text rather than a screenshot, because text is exact, cheaper, and groundable. Evaluation: perception eval on the exact error text and identifiers, separate from reasoning about the fix; slice by language and resolution. Failure modes: a misread variable name or error code that sends the debugging down the wrong path; describing the UI instead of reading the trace. Practical rule: treat a screenshot of text as a worse version of the text, accept it, but prefer and request the text itself, and crop-and-OCR what you must read exactly.
The cross-playbook decision table
A compact comparison makes the family resemblances and the differences visible at once, which is how you find your nearest neighbor and borrow from it.
| Playbook | Object of truth | Worst blind spot | Primary verifier | Automate or assist? |
|---|---|---|---|---|
| Invoice extraction | Field values | Structure lost at perfect OCR | Internal consistency + region re-OCR | Automate the verified majority |
| Medical form | Clinical facts | Handwriting; checkbox state | Clinician (human) | Assist only |
| Support screenshot | Error/UI text | Small text resolution | Crop + OCR + cross-check | Mostly automate, escalate edge cases |
| Retail visual search | Exact product | Similar ≠ same | Structured catalog join | Automate discovery, verify exactness |
| Meeting / call QA | Decisions, tone | Inverting word; lost paralinguistics | Ground to offset + flagged-token check | Assist + automate low-stakes |
| Safety inspection | Hazard presence/order | Shadow, between-frames, causality | Human inspector | Assist only, over-escalate |
| Chart analyst | Exact values | Estimated numbers | Source data | Automate from data, not picture |
| Code screenshot | Error/identifier text | Dense monospace | Request text + OCR | Assist, prefer text input |
Read the "automate or assist" column down: the answer is set by the stakes and the availability of a verifier, exactly as Chapter 3 argued. Where a strong independent verifier exists (invoice consistency, catalog join, source data), you can automate the verified fraction. Where the stakes are high and the verifier is a human (medical, safety), you assist and never auto-act. The common thread across all eight is the book entire: name the modality and its blind spot, fix the object of truth as something checkable rather than a description, build ingestion that preserves provenance, ground every claim to its source, verify before acting, evaluate by slice, and let the stakes decide how much the system does alone. A new multimodal product you have not seen is, almost always, a recombination of these, and designing it well is mostly recognizing which playbooks it is made of and inheriting their hard-won failure modes before production teaches them to you.
Chapter summary
The book's disciplines instantiate differently per product, so the fastest way to design a multimodal feature is to start from its nearest-neighbor playbook and inherit its failure modes in advance. Invoice extraction automates a verified majority but must report field (not OCR) accuracy and verify by internal consistency. Medical form review is assist-only decision support on special-category data, with harm-weighted asymmetry and mandatory consent. The support-screenshot assistant must detect modality, crop-and-OCR small text, and avoid the full-resolution cost surprise. Retail visual search finds candidates by embedding and decides by structured catalog join, because similar is not same. Meeting intelligence and call-center QA must catch the inverting word and preserve tone, grounding action items to audio offsets (Whisper is the start, not the system). Safety inspection from photos/video is over-escalating assist-only work that must beat sampling gaps and causality reversal and ground every finding for a human. The chart analyst extracts from source data, not the rendered picture (ChartQA), because read values are confident estimates. The code-screenshot assistant prefers requested text over a worse image of text. The cross-playbook table shows the "automate vs assist" decision is set by stakes and verifier availability exactly as Chapter 3 argued, and the common thread across all eight is the whole book: name the modality and its blind spot, fix a checkable object of truth, preserve provenance, ground every claim, verify before acting, evaluate by slice, and let the stakes decide autonomy, because a new product is almost always a recombination of these, and good design is recognizing which. This chapter applies the privacy and safety posture established in Privacy, Safety, and High-Stakes Images to each playbook.