Joint Embedding Spaces and Their Limits
> **Working claim:** A shared embedding space is the best tool there is for finding candidates across modalities and a dangerous tool for deciding truth.

Working claim: A shared embedding space is the best tool there is for finding candidates across modalities and a dangerous tool for deciding truth. Proximity in a space learned from gist-level pairs means "similar in the ways the training objective cared about, " which is reliably not the same as "the right one" along the dimensions, exact identity, quantity, recency, permission, that production decisions usually turn on.
A retrieval that was confidently similar and completely wrong
A retail company built visual search: a shopper photographs a product they like, the system embeds the photo in a CLIP-style space, finds the nearest catalog images, and returns them as "shop this look." It demoed beautifully, photograph a striped blue shirt, get striped blue shirts. Then the complaints arrived. A shopper photographed a specific running shoe to find that shoe in their size; the system returned five shoes that looked nearly identical, same silhouette, same colorway, same general vibe, none of which were the same model, and one of which was a discontinued line the company could not sell. A shopper photographed a 1-liter bottle of a cleaning product; the system returned the visually-indistinguishable 500ml bottle. A shopper photographed a power adapter; the system returned an adapter for the wrong region's plug.
Every one of these results was a good result by the only criterion the embedding space optimizes: visual-and-semantic similarity at the gist level. The shoes were similar. The bottles were similar. The adapters were similar. The space did its job perfectly. The job was the wrong job. The shopper's object of truth was not "similar" but "the same product, available, in my size, for my region", and similar and same are different relations, separated by exactly the fine, exact, categorical distinctions that captions omit and contrastive training therefore never learned. This chapter is about that gap, because it is the single most common way embedding-based multimodal features disappoint in production, and because the fix is structural, not a matter of a better embedding model.
What proximity actually means
In Chapter 4 we saw that a contrastive space is shaped by what its training pairs distinguished. Web captions distinguish "a striped blue shirt" from "a red dress." They almost never distinguish "model SKU-4471 in size 9" from "model SKU-4470 in size 10, " because no caption ever said that. So the embedding for two near-identical shoes is nearly identical, by design: the space was never given a reason to separate them. Proximity in the space is therefore a measure of caption-level resemblance, and the dimensions along which production decisions turn are frequently the ones captions ignore:
- Exact identity. Which specific SKU, model number, part number, document version, person. Captions say "a laptop, " not "the 14-inch 2023 model, configuration B."
- Quantity and scale. 1L vs 500ml, 12-pack vs 6-pack, 30mg vs 300mg. Two images of "a bottle of pills" embed together regardless of the dose printed on the label.
- Categorical distinctions invisible to gist. US plug vs EU plug, left-hand vs right-hand part, before vs after a recall.
- Recency and validity. The current version of a form vs last year's; the in-stock item vs the discontinued one. The space has no notion of time.
- Permission and tenancy. Whose document this is. The space has no notion of who is allowed to see what.
A similarity score collapses all of an item's dimensions into one number measuring resemblance along the axes the training objective happened to care about. When your decision turns on an axis the objective ignored, a high score is not just uninformative, it is actively misleading, because it presents two genuinely different things as the same to two decimal places of confidence.
Why a higher-quality embedding model does not fix it
The reflex, when retrieval returns the wrong-but-similar item, is to upgrade the embedding model. This usually disappoints, and understanding why saves a quarter of wasted work. A better embedding model is better at the task embedding models do: capturing more nuanced gist-level similarity. It will distinguish a striped shirt from a checked one more reliably. It will not, in general, learn to separate two SKUs that differ only by a model number printed in small text on the box, because (a) that text may not survive the encoder's resolution at all, and (b) even if it did, the contrastive objective was never given pairs that punished conflating them. The distinction your decision needs lives outside the space's competence, and no amount of in-space improvement reaches it. The fix is not a better number; it is a different mechanism for the dimensions the number ignores.
The structural fix: candidates from the space, decisions from attributes
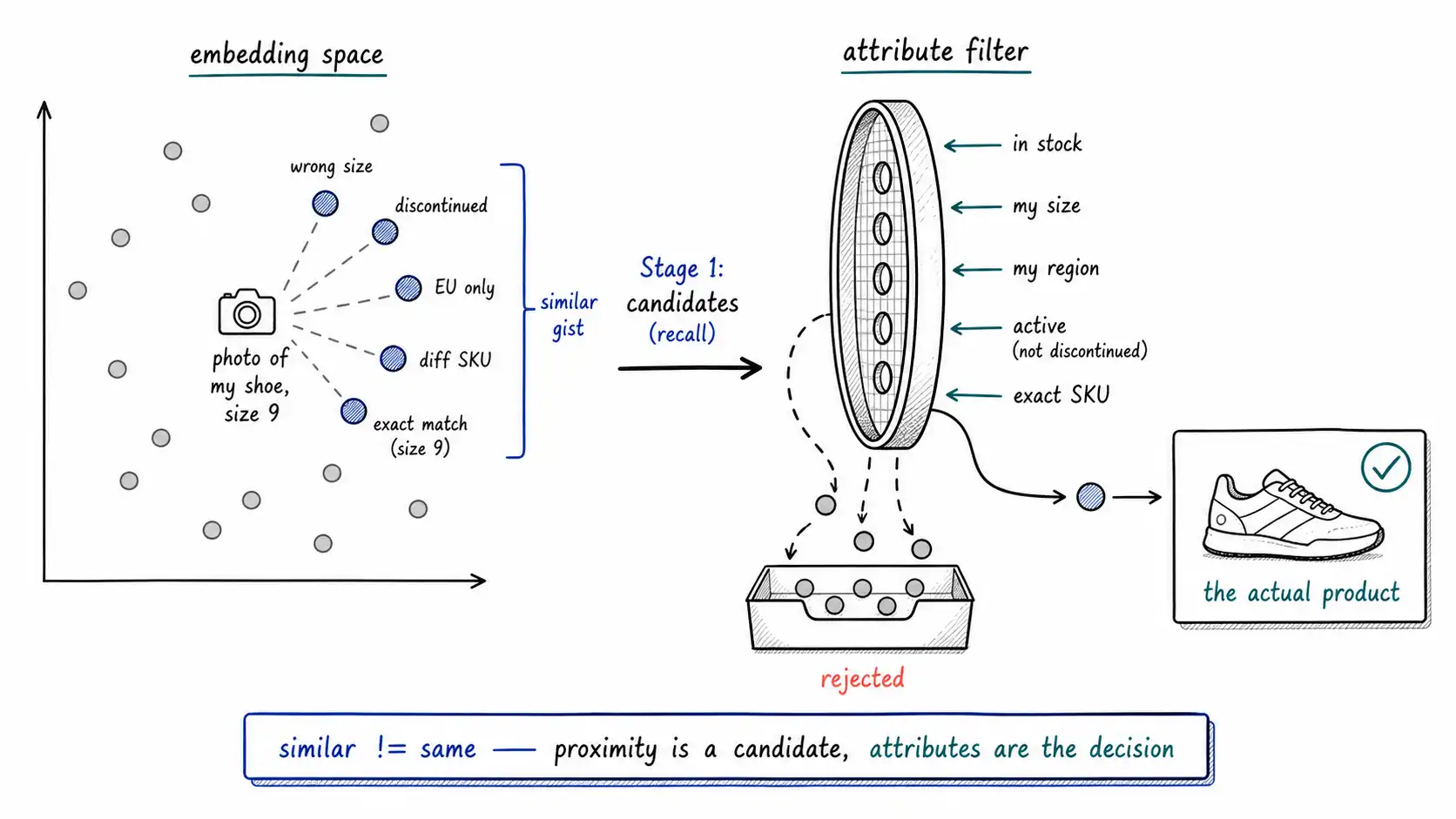
The pattern that resolves the retail company's problem, and the general pattern for using embedding spaces responsibly, has two stages with a hard boundary between them.
Stage 1, retrieval: use the embedding space to get candidates. Embed the query, find the k nearest items. This is what the space is excellent at: casting a wide, recall-oriented net over "things that resemble this." Tune k generously; you want the right answer to be in the candidate set, even buried.
Stage 2, decision: use structured attributes and explicit constraints to choose among candidates. Apply hard filters the space cannot represent, region, in-stock, current version, the shopper's size, the requester's permissions, and rank or verify the survivors using exact attributes, not the embedding score. For visual product search, this means after the embedding finds candidate SKUs, you read the structured catalog record for each (size availability, region, lifecycle status, exact model) and filter and rank on those facts. The shoe in the wrong size is filtered out; the discontinued line is filtered out; the EU adapter is filtered out, none of which the embedding could do, all of which a metadata join does trivially.
def visual_search(query_image, catalog_index, ctx) -> list[dict]:
"""Two stages: embedding for candidates, attributes for decisions."""
# Stage 1: recall-oriented candidate retrieval from the shared space.
q = embed_image(query_image)
candidates = nearest(q, catalog_index, k=50) # cast a wide net
# Stage 2: hard constraints the embedding space cannot represent.
results = []
for c in candidates:
rec = catalog.get(c["product_id"]) # structured truth
if rec.lifecycle!= "active": continue # not discontinued
if ctx.region not in rec.sold_regions: continue # right plug/region
if ctx.size and ctx.size not in rec.sizes_in_stock: continue
results.append({
"product_id": rec.id,
"embedding_score": c["score"], # kept for telemetry, NOT for ranking
"exact_match": rec.model_code == infer_model_code(query_image),})
# Rank by structured signals; embedding score breaks ties only.
results.sort(key=lambda r: (r["exact_match"], r["embedding_score"]), reverse=True)
return results[:5]The comment on embedding_score is the whole chapter: the score is retained for monitoring (a population of low best-scores tells you visual search is struggling) but it does not, by itself, decide anything. Decisions are made by the structured record. This is the embedding-space analog of Chapter 3's rule, the similarity is a claim ("this resembles your query"), and the catalog join is the verification ("... and here is what it actually is").
The same limit in documents and charts
This is not only a retail-search phenomenon; it is the general boundary of joint spaces, and it recurs wherever teams use embeddings for multimodal tasks. In document systems, embedding a page image (or its OCR text) to retrieve "the relevant page" finds pages that resemble the query, and a form's page from last year resembles this year's page extremely closely, so version-blind embedding retrieval will happily surface the superseded version, exactly the recency blind spot. DocVQA-style systems that retrieve by similarity must constrain by document version and date in structured metadata, not trust the space to know which is current.
In charts, the limit is starker. You cannot embed your way to a precise value. An embedding of a chart image captures "a bar chart that looks like this, " which is useful for finding the chart and useless for reading it; ChartQA is a reasoning-and-extraction task, not a similarity task, and the value must come from extraction (ideally from source data, per Chapter 3) not from proximity. MM-Vet scores integrated capabilities precisely because real tasks compose retrieval and reasoning and extraction, and the embedding space contributes only the first.
ImageBind and the temptation of one space for everything
ImageBind makes the joint-space idea intoxicating: one space binding image, text, audio, depth, and more, with emergent cross-modal retrieval you never explicitly trained. The capability is real and the temptation is to make this one space the backbone of the whole system, index everything into it, query everything from it, decide everything by proximity. Resist proportionally to the stakes. The same limits apply, amplified: alignment between two non-image modalities is indirect (bound through the image hub) and therefore noisier, and audio-to-text or audio-to-image proximity is an even weaker signal of identity than image-to-text proximity. One space is a wonderful router and a worse judge the further you get from where the pairs were dense. Use it to fan out and find candidates across modalities; never let it close a decision on its own.
A decision table: when is a joint space the right tool?
To turn the chapter into a reusable judgment, here is the test to apply before reaching for embedding-based retrieval as the answer rather than the candidate-finder.
| Your object of truth depends on... | Embedding space alone? | Why / what to add |
|---|---|---|
| Gist resemblance ("things like this") | Yes | This is exactly what it measures |
| Exact identity (SKU, version, person) | No | Join structured attributes; verify the identifier |
| Quantity / scale (dose, size, count) | No | Read the structured field; the space ignores magnitude |
| Recency / validity (current vs old) | No | Filter by date/version metadata; the space is timeless |
| Permission / tenancy (who may see it) | No | Enforce access control before, not via, similarity |
| A precise number from a figure | No | Extract from source data; similarity can't read values |
| Wide recall before a precise reranker | Yes, as stage 1 | Pair with reranking + verification (Ch. 8, 11) |
The pattern across the "No" rows is the same: each is a dimension along which captions are silent and the contrastive objective was therefore blind, so each needs a mechanism outside the space, a structured field, a date filter, an access check, an extraction. The "Yes" rows are the space's genuine home: resemblance and recall. A system that respects this table uses embedding spaces for what they are superb at and stops asking them to adjudicate what they cannot represent, which is most of what high-stakes production decisions actually turn on.
Chapter summary
A joint embedding space measures resemblance along the dimensions its training pairs distinguished, and because those pairs are gist-level captions, the space is blind to exactly the dimensions production decisions usually turn on: exact identity, quantity and scale, categorical distinctions invisible to gist, recency, and permission. The retail visual-search failure, returning the wrong size, the discontinued line, the wrong-region adapter, all with high similarity, is the canonical case: similar and same are different relations, and the score conflates them. A higher-quality embedding model does not fix this, because the needed distinction lives outside the space's competence, not inside its resolution. The structural fix is two stages with a hard boundary: use the space for recall-oriented candidate retrieval (its genuine strength), then make the actual decision with structured attributes and explicit constraints the space cannot represent, region, stock, version, size, permission, exact identifier, keeping the similarity score for telemetry, not for ranking. The same limit recurs in documents (version-blind retrieval surfaces superseded pages) and charts (you cannot embed your way to a precise value; that is an extraction task). ImageBind's one-space-for-everything is a superb router and a worse judge the further you get from dense pairs, so fan out with it but never close a decision with it. The decision table reduces to one test: if the object of truth depends on a dimension captions are silent about, the embedding space is at most a candidate-finder, and the decision must come from a mechanism outside it. This chapter builds on Encoders, Contrastive Learning, and Cross-Modal Alignment; the next movement turns from representations to the most structurally complex input modality: Documents Are Multimodal Objects.