Video Is Not Just Frames
This chapter turns video is not just frames into a concrete operating problem for the multimodal book.

Working claim: Video adds a dimension still images do not have, time, and the two failures unique to it are sampling (events shorter than your frame interval are invisible) and causality (a set of frames reasoned over without order can get "before vs after" exactly backward). Treating video as an unordered bag of frames, with the audio track thrown away, deletes the very information that distinguishes a video from a photo album.
The two seconds that decided a claim
Return to the claims team's fourth failure, because it is the cleanest illustration of video's first blind spot. A policyholder uploaded a phone video, a slow walk around their car. The damage, a deep dent on the driver's door, was visible for about two seconds as the camera panned across it. The ingestion pipeline sampled one frame per second. None of the sampled frames happened to land in that two-second window where the door filled the frame; the samples caught the hood, the bumper, the rear, all undamaged. The model, shown those frames, described an undamaged car. The claim was auto-routed to a low-touch fast-track. The damage was real and significant.
The information was there. It was uploaded, stored, and recoverable. It was absent from the model's reasoning purely because of a sampling cadence the team chose without measuring what it could miss. This is the temporal blind spot from Chapter 2, and it has no analog in still images: with a photo, what you see is what was sent; with video, what the model "sees" is a function of which frames you decided to extract, and every frame you skipped is a frame whose content the system is blind to. An event shorter than your sampling interval is, to the system, an event that did not happen. The audio track, meanwhile, contained the user saying "you can see the big dent on the driver's door here, " and the team had ignored it entirely, because they had treated the video as "just frames", discarding the modality (audio) that would have caught the failure of the modality (sampled frames) they kept.
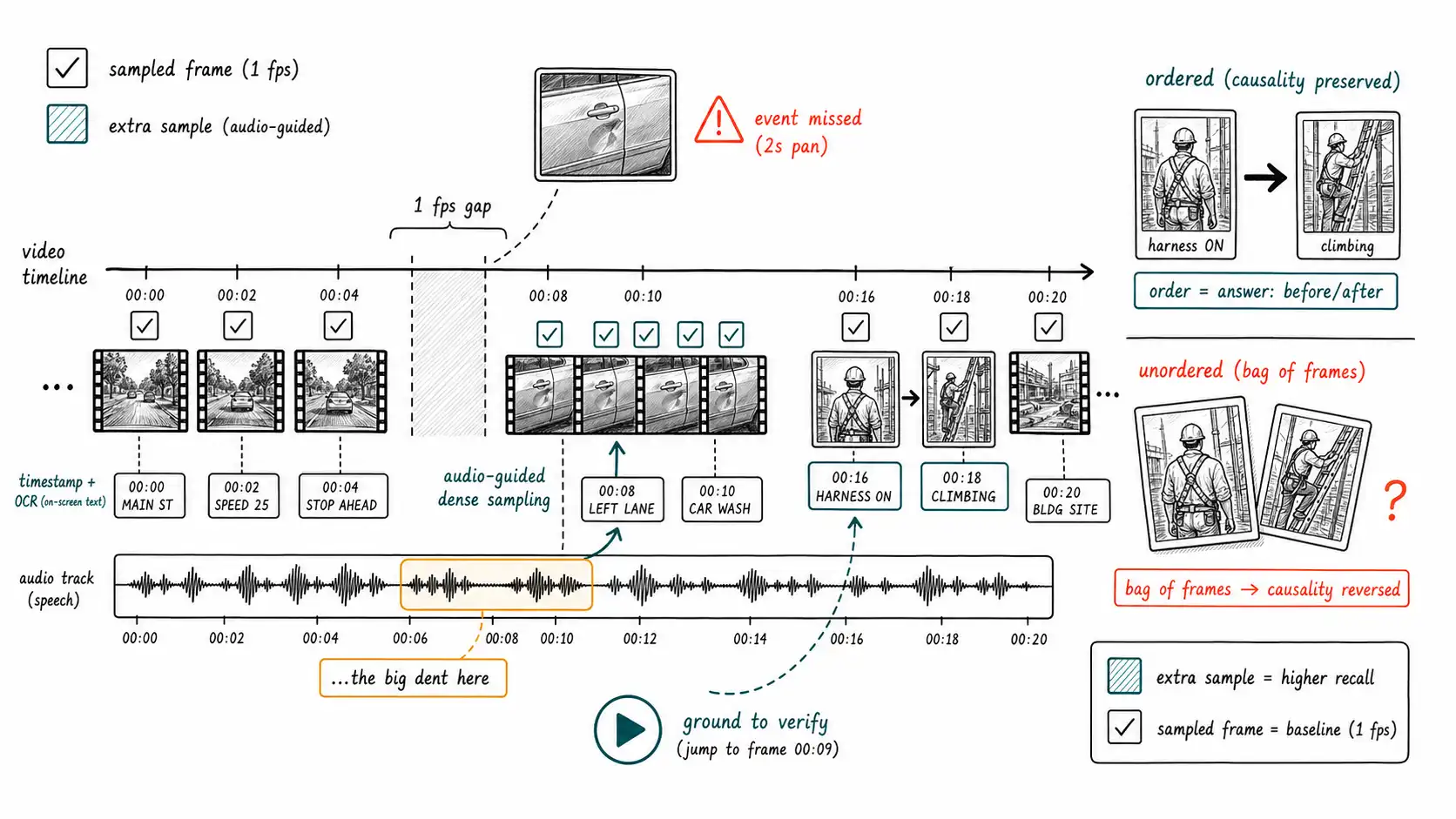
Sampling is a deletion decision
The first discipline of video is to treat frame sampling as what it is: a deletion decision with a measurable cost. A uniform "one frame per N seconds" is cheap and predictable and silently deletes any event shorter than N seconds. The fixes form a ladder of increasing sophistication and cost:
- Uniform sampling at a fixed interval. The baseline. Choose N by asking: what is the shortest event that matters for my object of truth? If a two-second pan can carry the answer, N must be well under two seconds in the regions that matter, or uniform sampling is the wrong tool.
- Shot/scene detection. Sample more densely at shot boundaries (cuts, large visual changes), because content changes there. This catches "a new thing appeared" far better than a blind interval, and it is cheap.
- Motion- or event-triggered sampling. Increase sampling rate where there is motion, a detected object of interest, or audio activity. A walk-around video gets dense sampling when the camera is moving across a surface (likely showing something) and sparse sampling when it is still.
- Audio-guided sampling. Use the audio track, which the flat-frames pipeline throws away, to find moments of interest ("... the big dent here") and sample densely around them. This is the single change that would have saved the claims team: align frame sampling to the audio cues that signal where the relevant content is.
- Dense ingestion into long context. The Gemini 1.5 report demonstrated ingesting video at fine sampling into very large context windows, reducing the sampling-gap problem by simply sampling much more. This raises the ceiling and is the right tool when latency and cost allow, but for most production systems most of the time, cost forces a sampling decision, so the ladder above still matters.
The rule across the ladder: sample where the answer might be, not uniformly across a timeline that is mostly empty. And measure the deletion: build an eval where the relevant event is deliberately short, and confirm your sampler catches it. A sampler you have not stress-tested against short events is a sampler that will silently miss them in production.
Causality: a bag of frames can reverse time
The second blind spot is subtler and more dangerous because it survives perfect sampling. Suppose you sample correctly and the model sees every relevant frame, but you present them to the model as an unordered set, or the model reasons over them without robust attention to order. Now "did the worker put on the harness before climbing, or after?" becomes answerable backward. The frames showing harness-on and climbing both exist; their order is the answer, and an order-blind reasoner has a coin-flip on the safety-critical question. The GPT-4V system card's documented weaknesses in precise spatial and relational reasoning extend to temporal relations: "before" and "after" are temporal relations, and they are exactly where confident error clusters.
The engineering response is to preserve and present order explicitly: tag every frame with its timestamp, present frames in temporal sequence, and for causality questions, structure the reasoning around the timeline rather than the set. Video-MMMU evaluates exactly this kind of temporal and knowledge-acquisition reasoning over professional videos, and it exists because video understanding is not still-image understanding repeated, it requires holding the sequence, and models vary in how well they do. For high-stakes causality (safety compliance, accident reconstruction, procedure verification), order is the object of truth, and a system that does not represent order robustly is guessing on the question that matters most.
A video ingestion pipeline that keeps time
The pipeline that respects both blind spots produces a time-indexed, multi-track representation: sampled frames with timestamps, the audio transcript with offsets (Chapter 9, powered by Whisper-style ASR), OCR of any on-screen text, detected shots and events, and a retrieval index over all of it. The structure is the antidote to "just frames."
from dataclasses import dataclass, field
@dataclass
class Frame:
frame_index: int
timestamp_ms: int
image_uri: str
ocr_text: str | None = None # on-screen text (slides, captions, signage)
is_shot_boundary: bool = False
@dataclass
class VideoDoc:
source_id: str
source_hash: str
duration_ms: int
frames: list[Frame] # IN TEMPORAL ORDER, always
transcript: "Transcript" # from Ch. 9: speaker + offsets + events
shots: list[tuple[int, int]] = field(default_factory=list) # (start,end) ms
def ingest_video(path) -> VideoDoc:
shots = detect_shots(path) # scene/cut detection
audio = transcribe_with_offsets(path) # Ch. 9 schema, keeps the AUDIO
frames = []
for start, end in shots:
# Dense sampling near shot boundaries and near audio cues of interest.
cues = audio_cues_in(audio, start, end) # e.g."here", "look at", numbers
rate_ms = 300 if cues else 1000 # sample faster where it matters
for ts in range(start, end, rate_ms):
img = frame_at(path, ts)
frames.append(Frame(
frame_index=len(frames), timestamp_ms=ts,
image_uri=store(img), ocr_text=ocr(img),
is_shot_boundary=(ts == start),))
frames.sort(key=lambda f: f.timestamp_ms) # preserve temporal order
return VideoDoc(source_id=hash_path(path), source_hash=file_hash(path),
duration_ms=duration(path), frames=frames,
transcript=audio, shots=shots)Three design choices carry the chapter. The pipeline keeps the audio and uses it both as content (the transcript) and as a sampling guide (audio_cues_in drives denser frame sampling where the speaker signals interest), the exact fix for the claims-team video. Frames are stored in temporal order and tagged with timestamps and shot boundaries, so downstream reasoning can respect causality and so any claim can be grounded to a frame. And on-screen text is OCR'd per frame, because a training video's content is often in its slides and captions, not its imagery, a fact the "describe the frames" approach misses entirely. The result is not a bag of frames; it is a time-indexed object with multiple aligned tracks, over which causality and grounding both work.
On-screen text and the training-video case
A class of video that deserves special mention is instructional and professional video, training, lectures, software demos, recorded webinars, because there the content is frequently in the on-screen text, not the imagery. A software-training video's value is in the menus, code, and captions on screen; a recorded lecture's value is in the slides. Video-MMMU is built around exactly this: knowledge acquisition from professional videos, where understanding requires reading what is shown, not just describing the scene. A pipeline that samples frames and asks the model to "describe" them will produce "a person presenting slides" and miss the entire content. The fix is per-frame OCR (in the schema above) plus alignment of the on-screen text with the transcript, so a question like "what command did they run at step 3?" is answered from the OCR'd terminal text grounded to its frame, not from a vision-language model's gist of a blurry screen capture. The resolution blind spot bites hard here, code and menu text are small, so this is also a place where high-resolution crops of the region of interest (Chapter 6) matter, and where verified OCR beats a fluent description.
Long video, retrieval, and the integrated-task warning
Hours-long video forces a retrieval architecture: you cannot put a three-hour recording into one prompt economically, even with large context windows, so the time-indexed VideoDoc becomes a retrieval corpus. A query ("when did they discuss the budget?") retrieves the relevant transcript segments and their frames by time, and the model reasons over that grounded slice, the multimodal-RAG pattern of Chapter 11 applied to a single long asset. The Gemini 1.5 report shows the long-context ceiling rising, which lets you retrieve generous slices, but the MM-Vet warning stands: integrated tasks (find the moment, read its on-screen text, reason about its causality, ground the answer) are harder than any component, and the system's claims about a video remain unverified until grounded to a frame or an audio offset and checked. Video is the modality where the most things can go wrong at once, sampling, causality, resolution, audio, which is exactly why it most needs the time-indexed, grounded, verified discipline this book has been building toward, and least tolerates "just send the frames to the model."
Chapter summary
Video adds time, and its two unique failures are sampling and causality. Sampling is a deletion decision: an event shorter than the frame interval is invisible, as when a two-second pan across a dented door fell entirely between one-frame-per-second samples and a real claim was auto-routed as undamaged, while the discarded audio track contained the answer. The fix is a ladder from uniform sampling up through shot detection, motion/event triggering, audio-guided dense sampling (the single change that would have caught the dent), and dense ingestion into long context (Gemini 1.5), the rule being to sample where the answer might be and to stress-test the sampler against deliberately short events. Causality survives perfect sampling: a bag of frames reasoned over without order can answer "before vs after" backward, which is a coin-flip on safety-critical questions, so order must be preserved and presented explicitly (Video-MMMU exists to measure this). The ingestion pipeline produces a time-indexed, multi-track VideoDoc that keeps the audio (as content and as a sampling guide), stores frames in temporal order with timestamps and shot boundaries, and OCRs on-screen text per frame, because instructional and professional video's content is often in its text, not its imagery, where the resolution blind spot demands high-res crops and verified OCR over fluent description. Long video forces a retrieval architecture over the time-indexed object, and the integrated-task warning (MM-Vet) is sharpest here: video is where the most can go wrong at once, so it most needs grounded, verified, time-aware discipline and least tolerates "just send the frames." This chapter follows Audio Is Not Text After Transcription; the next movement assembles time-indexed evidence into a retrieval layer: Multimodal RAG and Cross-Modal Search.