OCR Is Not Document Understanding
> **Working claim:** Reading the characters on a page and understanding the document are different problems with different metrics, different failure modes, and different owners.

Working claim: Reading the characters on a page and understanding the document are different problems with different metrics, different failure modes, and different owners. A pipeline can post a 99% character-accuracy OCR number and still extract the wrong field, attribute a value to the wrong key, or answer from a superseded page, because understanding is about which character means what, and character accuracy never measures that.
Two metrics that get confused into one
A document-AI team running invoice extraction reported to its stakeholders a single proud number: 98.7% OCR accuracy. The stakeholders heard "the system reads invoices with 98.7% accuracy" and planned automation around it. Both halves of that sentence were wrong about each other. The 98.7% was character accuracy, of all the glyphs on the page, 98.7% were transcribed correctly, measured against a benchmark of clean scans. The thing the stakeholders cared about was field accuracy: of the invoices processed, what fraction had the correct vendor, date, total, and line items extracted and correctly labeled. On the messy real intake, field accuracy was closer to 84%, and the 16% of failures were not random character errors. They were the structural failures of Chapter 6, the right number assigned to the wrong field, the total taken from a subtotal, the date read from the wrong of two dates, none of which a character metric can see, because every character involved was read perfectly.
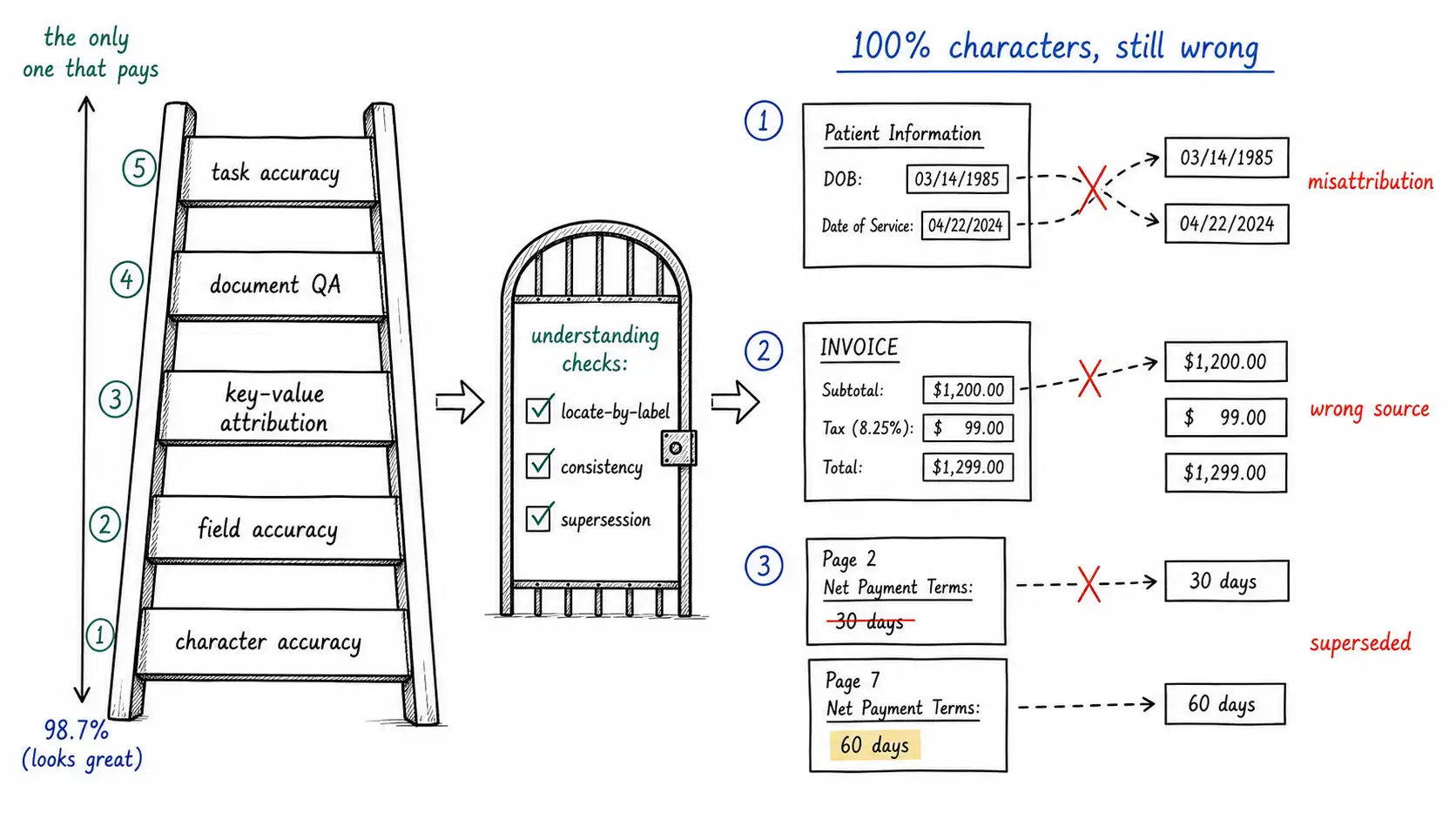
This is the chapter's whole argument, and it is worth stating as a hierarchy of distinct quantities, because teams routinely collapse them into one and then are surprised by production:
| Metric | Question it answers | Blind to |
|---|---|---|
| Character / word accuracy | Were the glyphs transcribed right? | Whether the right glyphs were used, and what they mean |
| Field extraction accuracy | Was each target field correctly read and labeled? | Whether downstream reasoning over fields is right |
| Key-value attribution accuracy | Is each value attached to the correct key? | Document-level consistency and recency |
| Document QA accuracy | Can the system answer questions requiring layout reasoning? | (This is the closest to "understanding") |
| Task accuracy | Did the end-to-end decision come out right? | Nothing, this is the only one that pays the bills |
Each row down measures something closer to understanding and further from transcription, and each row's failures are invisible to the rows above it. DocVQA deliberately scores the fourth row, document question answering, rather than the first, and the DocVQA challenge keeps the documents messy and the questions layout-dependent specifically so the score cannot be gamed by good OCR alone. If you report OCR accuracy to a stakeholder making an automation decision, you are answering a question they did not ask with a number that flatters the system.
Why good OCR and bad understanding coexist so comfortably
It is worth understanding why the two come apart, because the mechanism tells you where to intervene. OCR is a local, per-glyph problem: given this patch of pixels, what character is it? Modern engines are extremely good at it on reasonable inputs. Understanding is a global, relational problem: given all the read characters and their positions, which is the total, which date governs, which value belongs to which label, and which page is current? These are different computations, and being good at the first buys you almost nothing on the second.
Consider three failures that all occur at 100% character accuracy:
- Misattribution. A form has "Date of Birth" and "Date of Service" stacked, with their values to the right. Naive extraction pairs each label with the nearest value by raster order and swaps them when the layout is slightly off. Every character is correct; the patient's birth date is now their service date.
- Wrong-source selection. An invoice shows "Subtotal, " "Tax, " and "Total." All three are read perfectly. The extractor, lacking layout understanding, picks the largest number, or the last number, or the number nearest the word "amount, " and lands on the subtotal. Right characters, wrong field.
- Stale-page answer. A contract's page 2 states a 30-day term; page 7's addendum changes it to 60 days. Both are read perfectly. A system that does not model supersession answers "30 days." Right characters, superseded fact.
None of these is an OCR error. All of them are understanding errors, and they are the ones that cause incidents. This is why the GPT-4V system card's candor about confident errors matters even when OCR is involved: a vision-language model layered on top can reason fluently over correctly-read characters and still misattribute, mis-select, and ignore supersession, because reasoning over a document's structure is exactly where confident error lives.
Extraction as labeled fields, not free text
The architectural response is to stop treating extraction as "get the text" and start treating it as "fill a typed, labeled schema, with provenance, and verify each field." The object of truth is a set of named fields, each tied to where on the page it came from, each independently checkable.
from dataclasses import dataclass
@dataclass
class ExtractedField:
name: str # "invoice_total"
value: str
page: int
bbox: tuple[float, float, float, float] # where it was read (grounding)
source_text: str # the exact OCR'd characters at that box
label_text: str | None # the nearby key/label, if a key-value pair
confidence: str # "verified" | "unverified" | "conflict"
def extract_invoice(doc) -> dict[str, ExtractedField]:
fields = {}
# Use layout to LOCATE fields by their labels and positions, not by raster order.
fields["invoice_date"] = locate_by_label(doc, label="Invoice Date")
fields["due_date"] = locate_by_label(doc, label="Due Date") # not the same date!
fields["subtotal"] = locate_by_label(doc, label="Subtotal")
fields["tax"] = locate_by_label(doc, label="Tax")
fields["total"] = locate_by_label(doc, label="Total")
# Understanding-level verification (Ch. 3), not character-level:
derived = money(fields["subtotal"].value) + money(fields["tax"].value)
if money_eq(derived, fields["total"].value):
fields["total"].confidence = "verified" # internally consistent
else:
fields["total"].confidence = "conflict" # -> human review
# Recency check: is this the current version of the document?
if doc.superseded_by is not None:
for f in fields.values():
f.confidence = "conflict" # answering from a stale doc
return fieldsThree things in this code are the chapter in practice. Fields are located by their labels and positions (locate_by_label), not by guessing from raster order, which directly addresses misattribution and wrong-source selection. The total is verified by an understanding-level consistency check (subtotal + tax = total), which a character metric cannot perform and which catches the subtotal-as-total error. And the supersession check downgrades every field's confidence when the document has been superseded, which addresses stale-page answers. The output is not text; it is labeled, grounded, verified fields: the only representation over which a downstream decision is safe.
Tables and merged cells: the hardest structure
Tables deserve their own treatment because they concentrate the OCR-vs-understanding gap. A table's meaning is entirely relational: a number means nothing without its row and column headers, and merged or spanning cells make the row/column assignment ambiguous to anything that does not model the grid. OCR reads "5,100" perfectly; understanding requires knowing it is in the "Q3" column and the "Revenue" row, under a "EMEA" spanning header, three relationships, none of which are characters.
The reliable representation is structured table extraction that produces, for each cell, its row index, column index, spans, and the header path that gives it meaning, exactly the TableCell of Chapter 6. The test that distinguishes a real table extractor from a fake one is the merged-cell question: ask "what was EMEA's Q3 revenue?" and see whether the system correctly resolves the spanning header. A pipeline that flattened the table to text will have lost the spanning relationship and will answer from whichever number is textually nearest "Q3, " which is frequently wrong. ChartQA (see also ChartQA arxiv) measures the analogous gap for charts, where the "table" is the visual encoding and the question requires reading values off the structure, and the consistently sub-perfect scores even for strong models are the quantitative reminder that structure reasoning is unsolved enough to require verification.
Handwriting and the honest limits
Handwriting is where OCR's limits are starkest and where overclaiming is most dangerous. Modern handwriting recognition is far better than it was, but it remains materially less reliable than printed-text OCR, and its errors are not graceful, a misread digit in a handwritten dosage or account number is a high-impact error with no fluency cue. The honest engineering posture for handwriting is: extract it, flag it as handwriting in the schema (so downstream consumers know its provenance is lower-confidence), lower the confidence threshold for automatic action accordingly, and route handwritten high-stakes fields to human review by default. A medical form's handwritten dosage is precisely the field you do not auto-action on a recognizer's say-so. Naming handwriting explicitly in the extraction schema, rather than letting it flow anonymously into the field values, is the difference between a system that knows what it is unsure about and one that does not.
What to actually report to stakeholders
Because the metric confusion is the root of the overclaim, the chapter's most practical artifact is a reporting discipline. When a stakeholder asks "how accurate is the document system, " do not answer with OCR accuracy. Answer with the metric that matches their decision:
- If they are deciding whether to automate, report task accuracy and the verified fraction (Chapter 3), what share of documents the system can complete end-to-end with verified confidence, plus the human-review rate.
- If they are deciding which field to trust, report per-field extraction accuracy, sliced by document template, because the system is rarely uniformly good across templates.
- If they are debugging why it fails, report the failure taxonomy distribution from Chapter 1 (perception/OCR/grounding/reasoning/policy), because that says where to invest.
- Report OCR accuracy only when the question is genuinely "is the recognizer good enough, " which is a component-level question that almost no business decision actually rests on.
Reporting the right metric is not pedantry; it is what keeps the automation decision honest. The team that reported 98.7% and built automation around it was not lying, it was answering the wrong question with a real number, and the 14-point gap between character accuracy and field accuracy was the size of the surprise that landed in production. Document understanding is the field-and-task layer, it is measured there, and the recognizer's score, however good, is a fact about the recognizer and not about the system.
Chapter summary
OCR and document understanding are different problems: OCR is a local per-glyph transcription task, understanding is a global relational task about which character means what, and being excellent at the first buys almost nothing on the second. Character accuracy, field accuracy, key-value attribution, document QA, and task accuracy form a hierarchy in which each lower metric is blind to the failures of the higher ones, and the failures that cause incidents (misattribution, wrong-source selection, stale-page answers) all occur at 100% character accuracy, invisible to the metric teams proudly report. DocVQA and ChartQA deliberately score the understanding layer over messy, layout-dependent inputs to defeat OCR-only gaming. The architectural response is to extract typed, labeled, grounded fields located by their labels and positions (not raster order), and to verify each at the understanding level, internal consistency (subtotal + tax = total), key-value attribution, and supersession, rather than at the character level. Tables concentrate the gap because their meaning is purely relational; the merged-cell question separates real table extraction from text flattening. Handwriting is the starkest limit: extract it but flag it as lower-confidence and route high-stakes handwritten fields to humans. Finally, report the metric that matches the decision, task accuracy and verified fraction for automation choices, per-field-per-template accuracy for trust, the failure taxonomy for debugging, and reserve OCR accuracy for the rare component-level question, because the 14-point gap between character and field accuracy is exactly the size of the production surprise. This chapter builds on Documents Are Multimodal Objects; the next chapter closes the loop by making every extracted value verifiable: Grounding, Bounding Boxes, and Visual Citations.